AI与传统编译器
Posted 冲冲冲冲冲冲!!!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI与传统编译器相关的知识,希望对你有一定的参考价值。
AI与传统编译器
至于TVM,现在有很多框架(TF,Pytorch),然后会部署到不同平台(CPU、GPU、TPU),神经网络编译器,就是把不同框架里写的东西,编译成一样的格式,再生成到某一平台的代码
再来看传统编译器(更偏向于LLVM),现在有许多语言(C、ObjC、C++),也有许多平台(x86、arm),编译器做把不同语言编译到同样的中间代码,再生成某一平台的代码
这两个就是把前端的表示进行统一,再生成硬件相关的程序,只不过一个前端表示的是神经网络,一个是大家都熟悉的代码,结构类似,但实际内部工作大相径庭
传统编译器:输入高级语言输出低级语言
神经网络编译器:输入计算图/算子,输出低级语言
相同点是都做了类似语言转换的工作
不同点
传统编译器解决的主要问题是降低编程难度,其次是优化程序性能
神经网络编译器解决的主要问题是优化程序性能,其次是降低编程难度
问题
对于神经网络编译器,如果没有体系结构相关信息的输入,是否能生成高效代码(涉及完全自动化的问题)
当前的技术投入比来看,神经网络编译器和人工算子实现的,哪个性价比更高
神经网络编译器,编译时,考虑神经网络有关的特性,优化程序。
程序优化,解释器vs编译器,JVM,JIT,llvm, Halide,TensorFlow, XLA, ONNX, TVM, MLIR
AI编译器和传统编译器的本质是一样的,都是一类能够将不同的编程语言所表达code,进行转换的program。这也是AI编译器之所以被称之为“编译器”的原因。
两者的联系
因为AI编译器出现的比较晚,所以在设计的时候,往往会借鉴传统编译器的思路:
两者的理念比较类似。两者都力求通过一种更加通用,更加自动化的方式进行程序优化和代码生成,从而降低手工优化的effort。
两者的软件结构比较类似。一般都分成前端,IR,后端等模块。前端负责讲不同的语言的描述,转换成统一的IR表述,后端通常会对IR表示进行优化,最终生成可执行的code。IR层用来解耦前端和后端,降低集成的effort。
两者的优化方式比较类似。通常编译器都会对code,进行一系列的优化,从而提高performance,或者减少memory footprint等。AI编译器和传统编译器都是通过在IR上面,run各种各样的pass,进行优化的。而且,AI编译器,往往还会借鉴传统编译器中的一些pass,比如constant folding, dead code elimination等
AI编译器通常会依赖于传统编译器。AI编译器在IR上面,对model进行优化之后,通常会有lowering的过程,将优化后的high-level IR,转换成传统编译器的low-level IR,然后依赖传统编译器,做最终的机器码生成。
两者的区别
两者最根本的区别是应用场景的区别:
AI编译器是把一个深度学习模型,转换成executable。这里可以把一个深度学习模型,理解成一段用DSL(Domain Specific Language)描述的code,executable就是一段用硬件能理解的机器码描述的code。这正好能对应到compiler的定义。
传统编译器是把一段用高级语言编写的code,转换成executable。这里的高级语言可能是C/C++等。这也能够对应到compiler的定义。
应用场景的区别,导致了两者在设计上不同:
两者的IR表达层次有区别。AI编译器一般会有一套high-level的IR,用来更抽象的描述深度学习模型中,常用的high-level的运算,比如convolution,matmul等。传统编译器的IR更偏low-level,用于描述一些更加基本的运算,比如load,store,arithmetic等。有了high-level的IR,AI编译器在描述深度学习模型的时候会更加方便。
两者的优化策略有区别。AI编译器因为是面向AI领域的,在优化时,可以引入更多领域特定的先验知识,从而进行更加high-level,更加aggressive的优化。比如说:
AI编译器可以在high-level的IR上面做operator fusion等,传统编译器在做类似的loop fusion的时候,往往更加保守。
AI编译器可以降低计算的精度,比如int8, bf16等,因为深度学习模型,对计算精度不那么敏感。但传统编译器一般不会做这种优化。
对神经网络优化,尽量减少逻辑判断,一算到底是最好的。对内存要尽可能优化,降低内存占用。
神经网就是一组矩阵计算。神经网编译器,就是将这组计算针对平台尽可能加速。
编译神经网络,把一张张计算图编译成cpu的gpu的,或者是某些专用的AI计算设备,比如google 的TPU的指令集合。具体说来就是先来个图剪枝,再来个拓扑序遍历计算图,一边遍历,一边映射为中间表示。
后面从中间表示到指令集,就大同小异了。
神经网络编译器大概有TVM/Glow/TensorRT/TensorComprehension/XLA/Tiramisu。这些针对的都是神经网络模型推理阶段的优化,从神经网络模型到机器代码的编译。一般过程是:神经网络模型->图优化->中间代码生成(例如Halide)->中间代码优化(例如TC/Tiramisu使用多面体模型进行变换)->机器代码。编译的是神经网络的模型,优化的是网络模型本身,各层数据数据存储的方式(如分块存储,nchw,nhcw),各个算子(如mlp,conv)的计算方式(如向量化,分块)等等。
传统编译器(GCC,Clang这些)的编译范围更广,是从源代码到机器代码的编译,输入是一段完整的代码,经过了词法分析,语法分析,语义分析,中间代码生成,优化,最后到机器代码。
联系:
首先是神经网络编译器,从中间代码到机器代码的过程,可能就对应了传统编译器的整个编译过程,比如Halide->机器代码
然后,目标都是都要针对目标处理器进行的优化。无论是什么代码/模型,最后的优化,就是如何最大化利用硬件,比如cache的命中率,计算速度啥的,最终目标都是生成好的机器代码。
神经网络编译器,可以对应用做很多很强的假设,主要以嵌套循环的计算为主,所以可以针对性的进行优化。
传统编译器的前端也非常厚重,都是以编程语言为输入来生成IR的。神经网络编译器的主要问题,还是性能优化和适配,所以基本都不做前端,直接用代码手动构造IR。
针对deep learning的编译器,把应用限制在tensor operator上,做domain specific optimization。传统编译器面向的程序更加general。前者更偏上层,只需要考虑deep models,流行的deep models基本算子就卷积和矩阵乘,后者更偏底层。
以TVM和LLVM举例,TVM拿到模型的计算图,先用Relay做一下图切分,算子融合,conv-bn-relu之类的,也有人做multiple conv fusion,这一步是graph-level的优化;之后再到算子层面,现在的deep compiler侧重于循环优化,这部分在传统编译器里研究的很多,即使是deep learning领域,能做的domain specific的优化也没多少,auto tuning做的主要还是tiling的参数 (AutoTVM / FlexTensor (ASPLOS 2020) / Ansor (OSDI 2020))。做完operator-level的优化,TVM IR转成LLVM IR,再借助LLVM的各种后端,生成可执行代码。
要部署一个模型,后端可以选择使用手调库,比如厂商库,MKLDNN, CuDNN,某些厂商的,或者第三方的Blas库,算子库,比如阿里的MNN;另外一条路,就是选择deep compilers,做代码生成。
先说deep compiler的缺点。首先编译器能做的工作比较有限,实际的部署,要考虑到模型设计,模型压缩之类的。因为比较偏上层,代码生成部分交给了black-box compiler, 很难做到汇编级的调优,能在tuning中避免shared memory bank conflicts,但是,并不能优化掉register bank conflicts,在现有的DSL中,也缺乏底层的表达,相比于某些手调库,最终性能不太行。比如说,某些人专门做Winograd Conv的优化,性能都快接近理论极限了 (ppopp 2020)。能想到的缺点,都非常细节,觉得未来很容易解决,比如GPU的prefetch,现在TVM里面,用prefetch怎么选size和offset,基本都会导致性能变差。
但是,手调库的缺点更加明显,除了耗费人力外,优化也是general的,无法cover到具体的input configuration。即使是针对某些input,选择调用不同的kernel,也非常有限。比如MKL-DNN,CuDNN虽然是厂商库,代表了手调的state-of-the-art,可能对3 * 3的卷积做了特殊优化,但对于某些大的feature map,或者大的kernel size性能就很差。在某个具体网络上,通过auto-tuning,超过MKL-DNN和CuDNN并不难。AMD的就更不用说了,性能太差了,针对CUDA做的调优,用hipify工具转到ROCm上,性能都强。
自动调优最重要的是调优之后的性能,其次是调优的时间。
对TVM了解比较深,对其他的deep compiler了解不多。至少相比于主流框架Torch/TensorFlow来看,当然考虑了这些框架用的底层库,在某个网络上,比如ResNet-18,针对Input大小为(1, 3, 224, 224)做调优,超过还不算太难。因为做的就是inference optimization,实际部署模型的时候,input size都是运行时不再变的,所以这条路可行。
调优时间上,Ansor调一个网络大概一天左右,比较短了。Facebook有工作做贪心搜索,能把调优时间降到一分钟以内,最终性能也不算差。
如果指的是针对神经网络的编译器,相对传统编译器最大的不同,引入了multi-level IR。
传统编译器里分为前端,优化和后端,前端和语言打交道,后端和机器打交道,现代编译器的的前端和后端分的很开,共同桥梁就是IR。IR可以说是一种胶水语言,注重逻辑,去掉了平台相关的各种特性,支持一种新语言或新硬件,都会非常方便。
由于神经网络结构领域的特殊性,这类编译器不光要解决跨平台,还有解决对神经网络本身的优化问题,原先一层的IR就显得远远不够,如果设计一个方便硬件优化的low level的语言,几乎很难从中推理一些NN中高阶的概念进行优化。比如说LLVM,很难把一连串的循环理解成卷积。一个完善的High level IR,至少需要包括对计算图的表示(DAG, let binding),满足对tensor和operator的支持。
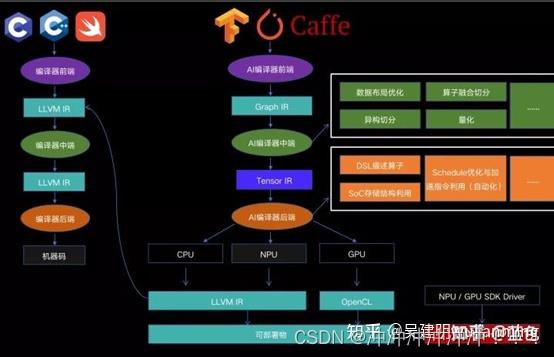
神经网络编译器或者深度学习编译器(下称 DL 编译器),属于一种领域特定编译器,专门用于将神经网络的训练/推理部署到 CPU、GPU、NPU 上。与传统的编译器有着类似的结构,有很多共用的部分,同时也有自己的侧重点。
关于 DL 编译器,更多谈一下 edge 端 DL 编译器。
- DL 编译器产生的背景
早期神经网络部署的侧重点在于框架和算子库。神经网络可以由数据流图来表示,图上的节点就是算子(比如 Conv2D、BatchNorm、Softmax),节点之间的连接代表 Tensor。由于数据流图很直观,很多框架的 Runtime 采用了类似 Caffe 的方式,运行时通过一定的顺序(例如直接 Post order DFS)分配 Tensor、调用算子库就行了。优化重点在于优化算子库的性能。
随着时间的发展,这种直观的部署方式,也逐渐暴露出一些问题。
越来越多的新算子被提出,算子库的开发和维护工作量越来越大
比如提出一个新的 Swish,算子库就要新增 Swish 的实现,还要有优化、测试。Swish由一些基础的一元二元算子组成。
NPU 的爆发导致性能可移植性成为一种刚需
大多数 NPU 作为一种 ASIC 在神经网络场景对计算、存储和 data movement 做了特殊优化,对能效比相对 CPU、GPU 要好很多。在移动端和 edge 端,越来越多的 NPU 开始出现。同时 NPU 的 ISA 千奇百怪,一般也缺乏 GCC、LLVM 等工具链,使得已有的针对 CPU 和 GPU 优化的算子库,很难短期移植到 NPU 上,充分利用硬件的能力达到较好的性能。
更多可优化的点得到关注
早期 CPU 和 GPU 上带宽问题不是很明显,大家更多关注单个算子的性能。但在移动端和 edge 端的应用中,逐渐遇到了带宽跟不上算力的问题,在这些 target 上增大带宽,意味着功耗和成本的上升,利用算子间的 fusion 和调度,节省带宽开始被重视起来。
- 与传统编译器前端的异同
传统编译器多接受文本类型的编程语言,通过 lexer 和 parser 构造 token 和 AST。
DL 编译器接收的一般是 DL 框架的模型文件,例如 TensorFlow 的 pb、PyTorch 的 pth,还有 ONNX 等。DL 编译器一般把模型的导入模块叫做 importer,将 DL 框架的模型转换为 DL 编译器的 IR,只跟模型文件格式和 IR 表示耦合,要支持新的框架,只需要新增一个 importer 就行了。
- 与传统编译器中后端的异同
DL 编译器和传统编译器一样,使用 Constant Folding、DCE、CSE 等对 IR 进行优化。
除此之外,DL 编译器还会有一些领域特定的图优化:
合并冗余、消除无意义的 Transpose、Reshape、Pad
合并 BatchNorm 到 Conv2D、MatMul
对于先 Add 后激活的残差结构,可以将一路输入作为另一路 Conv2D 的初始值
目前大多数图优化,还是根据经验人工编写 rules,同样有着工作量越来越大,容易陷入局部最优的问题。有一些研究已经开始解决这些问题。应用了传统编译器界研究了很多年的 Equality Saturation 技术。
图优化之后 DL 编译器,还要进行一些 ISA 相关的优化:
Layout
选择 NCHW ,还是 NHWC ,还是 NCHW16c 等等,对于算子在特定 ISA 上的效率,会产生影响,需要纳入 cost-model
Tiling
一些 NPU 利用高速片上内存进行计算,容量一般都很有限,编译器需要对大块的计算进行 tiling。对于 Conv2D 这类数据复用很多的计算,如何进行 tiling 对性能和带宽,也有很大影响,选择 tiling 参数,也需要纳入 cost-model
Fusion
一些 NPU 可以 fusion Conv2D 和激活,甚至 fusion 一段一元二元算子组成的计算图。编译器需要根据硬件,提供的能力和 cost-model 选择合适的 fusion 区域,如果贪心去匹配,也容易产生次优结果。
Partition
对于 CPU、DSP、GPU、NPU 组成的异构系统,编译器需要考虑算力、带宽、数据交换的代价,对计算图进行合理地切分。
这几个优化有时候,也需要同时考虑,比如, fusion 多层 Conv2D 时的 tiling 和单层又有不同。
很多场景下计算图中的 Shape 是已知的,在方便了上述优化的同时,还解锁了下面几个优化:
峰值最小的内存分配
因为分配释放序列和每次分配的 Buffer 大小已知,可以找到每个 Buffer 的最优分配位置,使得内存峰值占用最小
Concat 消除
对于一些特殊情况,可以通过将几个算子输出的 Buffer 分配到一起,从而避免运行时 Concat 的发生。比较常见的是 densenet 中 Concat 的消除。
- DL 编译器特别的地方
DL 编译器因为领域特定,还包含一些特别的功能。
稀疏
稀疏存储 Tensor 可以降低带宽。一些 NPU 还可以通过跳过无用计算的方式,加速稀疏 Tensor 的计算。
DL 编译器需要根据数据、Weights 的分布合理选择,对某个 Tensor 是否进行稀疏。
量化
很多场景下神经网络的推理,不需要太高的数据精度。int8 甚至 int4 已经在工业界落地。模型量化分为训练感知量化(QAT)和训练后量化(PTQ)。大部分用户使用 PTQ,编译器需要利用用户提供的校准集(calibration dataset),得出需要量化的 Tensor 的数据分布,选择非饱和或者饱和量化。
为了简化,将”面向神经网络的编译器“简称为"AI编译器"。
关于AI编译器和传统编译器的区别和联系,从形式上可以理解为是输入和输出的区别。AI编译器的输入是建模的DSL描述(可能是python,比如TensorFlow/PyTorch,也可能是Lua,比如,上一代的Torch,还可能是Caffe时代的PB描述文件,如果自己手写一个AI框架的自定义DSL),输出通常是传统编译器的输入(LLVM IR也可以视为是广义的传统编译器的输入)。传统编译器的输入是传统编程语言描述的代码,输出的是硬件可执行码。
- 透过形式,再深究一下背后的东西。AI编译器和传统编译器的优化原理,有很多共通的地方,比如:
计算图层面的循环不变量优化(Loop Invariant Node Motion),高级语言层面的循环不变量优化(Loop Invariant Code Motion)。
计算图层面的常量折叠和高级语言层面的常量折叠。
计算图层面的peep hole optimization(模板匹配),高级语言层面的peep hole optimization。
计算图层面的strength reduction优化(比如针对Transformer模型的冗余padding计算消除优化,在LightSeq,Faster Transformer的开源代码里,都可以看到),高级语言层面的strength reduction优化。
将大量计算零碎算子进行fusion&codegen优化,减少AI框架和访存overhead的优化,将多条高级语言指令进行融合,减少中间变量的访存操作,通过寄存器中转优化,目的上是相似的(细节原理上是不同的)
还有类似TASO这样的工作等等。
本质上都是在一种,或多种表达形式上,进行变换,变换的目的是为了优化,优化的标的可能是性能、显存/内存,通信量、功耗等等,在计算图上面结合不同的约束条件,进行变换工作。从这个层面来看,大量的传统编译领域技术,在AI编译领域的应用,只是施加的层次不同。
- 与此同时,也会存在一些细节层面的区别。最大的一个区别,AI编译器作为一个domain specific的compiler,其实多了不少可以利用这个domain特性使巧劲的地方,举几个例子:
自动分布式并行。自动分布式并行,可以在不同层面来进行推进,一种方式是在更靠近编译的IR层(比如HLO IR以及TorchScript的IR),完成自动并行策略的探索。另一种方式是在更靠近建模层的图表示层来做,比如TF Graph/JAX Graph/PyTorch NN module。从系统极致角度来考虑,前者更为究竟,这是看到G-shard,MindSpore的作法,从实现的工程量/效果回报速度来看,后者更为practical,这是看到Horovod/DeepSpeed/Megatron的作法。
关于算子优化,也有不同的作法。一种是通过自动codegen的作法,进行批量化生成,另一种是通过手写(或半手工,类似ATLAS这种计算库里的作法)开发精细的kernel,获得极致的性能。如果AI workload高度diversified,前者更有效率,如果AI workload呈现半收敛态,后者反而效率更高。对于新硬件,多出了show case和长尾case的不同考虑,让这个问题变得更复杂了。
结合一些workload,甚至业务层面的特点,可以起到“四两拨千斤”的优化效果。几个比较具体的例子,推荐类模型涉及到ID类特征的处理,可能涉及到对字符串类源特征的处理,提前在预处理环节对字符串做ID化,还是在模型里做ID化,对性能影响会非常明显,而这个优化其实不需要复杂的系统优化技术就能达到。另一个例子,如果能够对一些重要的建模库进行干预,在模型写法上,对后端AI框架更为友好,实际上能大大简化后端优化的复杂性,Google开源出的Transformer的代码,其实就有TPU-friendly的痕迹。
这些巧劲得以发挥的一个关键原因,当视野集中在AI domain的关键workload时,可以结合这些workload的特性,做一些看起来"overfit",但实现效率更高的设计妥协。而传统编译器,因为打击的workload多样性更强(通用域编译器和domain-specific编译器的区别),所以在leverage workload特性上会更为谨慎,通常会以workload-agnostic的角度来提供优化手段,workload-specific的优化,就往往上推到各自domain里了,比如在数据库领域,利用编译思想,进行JIT优化的工作。
4.应该如何看待AI编译器,在AI系统中的地位和作用。观点是"no silver bullet"。这就好比传统系统领域,存在编译器、库(STL/glibc/…),运行时,这若干个component进行组合协同一样,当然可以不使用STL,期望编译器足够的优秀,对于一个普通版本的STL alike的实现,能通过编译手段获得极致性能,但这样决策涉及到在编译器上投入的effort,是否值得就要仔细考虑了。在AI system领域,同样会有类似的分工。对于一个workload,一族workload,整个AI worload的全场景,应该如何在AI编译器、AI底层库、运行时、AI建模库之间进行职能划分,很考验系统设计能力的事情。如果再有机会对硬件设计也有干预,影响到programming model,device compiler的设计,更具挑战,也更有意思的事情了。
对于社区AI编译领域的一些作法,比如需要用户手工打标签,标识哪段子图可以进行JIT优化是有些diss的,时过境迁,现在觉得这种作法和AI编译的通用优化,不是互斥矛盾的,反而可能是另一种看到了整体工作复杂性以后的trade-off考虑罢了。从系统设计的角度来说,对MLIR的设计理念的认同度也更高了,当然MLIR社区里的声音不够清晰统一。
1.神经网络编译器背景和历史
1、早期深度学习框架,重点是框架和库,与编译器关系相对较弱
比如Tensorflow早期版本,在神经网络/深度学习的编程模型上,主要进行了graph/图和op/算子两层抽象
图层通过声明式的编程方式,然后通过静态图的方式进行执行,这里其实也做了一些编译器的事情,这里包括硬件无关和硬件相关的优化:硬件无关的优化包括编译器通用的优化,如表达式化简、常量折叠,也包括与深度学习/神经网络强相关的,如自动微分等;硬件相关的优化包括简单的算子融合、内存分配优化等。
算子层通常采用手写的方式,比如GPU上基于CUDA/cuDNN。
这种方式遇到几个问题:
表达上,语法不是Python原生的,算法工程师使用的易用性不够好
更多的Transform出现,比如并行、量化、混合精度等
算子粒度和边界提前确定后,无法充分发挥硬件的性能
硬件厂商提供的算子库,也不一定是性能最优的,在SIMT和SIMD的架构中,scheduling、tilling都是有很大的空间,在具体到一个模型,shape确定的情况下,开发者还有可能开发出性能更高的算子。
AI专用芯片出现(Google TPU、华为Ascend等),3与4的情况加剧。
2、后期引入大量编译器的技术进行改进
表达上的改进(Pytorch/TorchScript、JAX)
Pytorch的Eager Model是一种解决易用性的方案,虽然基本上还是图层和算子两层的抽象,但是整个语法基本上是Python Native的,让算法工程师比较容易上手;不过这个方案在运行的时候,基于Python解释器的能力,不是一种高性能的解决方案,本身与神经网络的编译器关系不大;但是其表达的方式成为后面框架参考的标杆,图层的神经网络编译器,主要就是考虑如何把这样表达转换到图层的IR进行优化,目前主要有两种方式:
AST-Based:以Pytorch TorchScript为例,主要通过Python的修饰符,把Python代码的AST拿到,然后变换成图层的IR,进行编译优化。
Tracing-Based:以JAX为例,主要把Python代码假执行一遍,保存执行序列,基于执行序列,变换到图层IR进行编译优化。
两种方案各有优缺点,第一种方案实现复杂,第二种方案在一些处理上有限制(比如控制流的处理)。
性能上的优化(XLA/TVM/TC)
性能上的优化思路其实比较统一,就是打开图和算子的边界,进行重新组合优化。
XLA:基本上的思路,把图层下发的子图中的算子全部打开成小算子,然后基于这张小算子组成的子图,进行编译优化,包括buffer fusion、水平融合等,这里的关键是大算子怎样打开、小算子如何重新融合、新的大的算子(kernel)怎样生成,整体设计主要通过HLO/LLO/LLVM层lowering实现,所有规则都是手工提前指定。
TVM:分为Relay和TVM两层,Relay主要关注图层,TVM主要关注算子层,总体思路与XLA是类似的,也是拿到前端给一张子图进行优化,Relay关注算子间的融合、TVM关注新的算子和kernel的生成,区别在于TVM是一个开放的架构,Relay目标是可以接入各种前端,TVM也是一个可以独立使用的算子开发和编译的工具(基于Halide IR,最新演进到自己定义的TIR),TVM在算子实现方面采用了compute和schedule分离的方案,开发人员通过compute,设计计算的逻辑,通过schedule来指定调度优化的逻辑。
TC(Tensor Comprehensions):开发者发现算子的计算逻辑的开发,比较容易的,但是schedule的开发非常困难,既要了解算法的逻辑,又要熟悉硬件的体系架构,更重要的是,图算边界打开后,小算子融合后,生成新的算子和kernel,这些新的算子compute是容易确定的(小算子compute的组合),但是schedule却很难生成,传统的方法就是事先定义一大堆schedule模板,万一组合的新算子不在模板之内,性能就可能比较差,甚至出错; TC则希望通过Polyhedra model,实现auto schedule,降低开发门槛,当然这个项目基本已经停更了,类似的工作在MLIR、MindSpore上,还在不停发展。
图层和算子层的IR表达
在神经网络编译器发展过程中,有多种IR的出现,各有特点:
图层IR:朴素的DataflowIR、函数式IR、函数式图IR、SSA风格IR
算子层IR:HalideIR、LLVM等
图算融合表达:MLIR
以前分析过图层IR,供参考:
2.回到问题
1、神经网络编译器与传统编译器的相同点
神经网络编译器和传统编译器一样,也是有前端表达、硬件无关优化和硬件相关优化、最后的codegen等,整体结构是类似的。
2、神经网络编译器与传统编译器的区别
主要体现在神经网络编译器,像数据库的SQL引擎/向量化引擎一样,一个特定领域的编译器,这些领域特征包括:以Python为主的动态解释器语言的前端、多层IR设计(图层/算子层/codegen)、面向神经网络的特定优化(自动微分、量化/混合精度、大规模并行、张量运算/循环优化等)。
编译前端解析
与传统编译器不同,神经网络编译器通常不需要lexer/parser,而是基于前端语言(如Python)的AST,将模型解析,构造为计算图IR,侧重于保留shape、layout等Tensor计算特征信息,当然部分编译器,还能保留控制流的信息。
这里的难点在于,Python是一种灵活度极高的解释执行的语言,像弱类型、灵活的数据结构等,而神经网络编译器本质上是偏静态,两者之间的完全转化是不大可能的。
多层IR设计
为什么需要多层IR设计,主要是为了同时满足易用性与高性能这两类需求。为了让开发者使用方便,框架前端(图层)会尽量对Tensor计算进行抽象封装,开发者只要关注模型和粗粒度OP;而在后端算子性能优化时,又可以打破算子的边界,从更细粒度的循环调度等维度,结合不同的硬件特点完成优化。因此,多层IR设计无疑是较好的选择。
High-level IR(图层IR),如XLA的HLO,TVM的Relay IR,MindSpore的MindIR等,重点关注非循环相关的优化。除了传统编译器中常见的常量折叠、代数化简、公共子表达式等优化外,还会完成Layout转换,算子融合等优化,通过分析和优化现有网络计算图逻辑,对原有计算逻辑进行拆分、重组、融合等操作,减少算子执行间隙的开销,提升设备计算资源利用率,实现网络整体执行时间的优化。
Low-level IR,如TVM的TIR,HalideIR,以及isl schedule tree[7]等。针对Low-level IR主要有循环变换、循环切分等调度相关的优化,与硬件intrinsic映射、内存分配等后端pass优化。自动调度优化,主要包含了基于搜索的自动调度优化(如ansor)和基于polyhedral编译技术的自动调度优化(如TC和MindAKG)。
有人可能会问,图层和算子层的表达和编译能否放在一起?也许可以,但是明显看到这样做面临几个挑战:
1、整图展开到原子算子,看上去编译的规模/复杂度,指数级上升
2、显然图编译优化的问题和算子编译优化的问题,有明显的区别,一个关注变换和融合,另外一个关注循环优化,放在一起对编译器实现的复杂度是个比较大的挑战
3、要看到硬件供应商和框架供应商,目前是分开的,两者总是需要一个边界。
面向神经网络的特定优化
自动微分:BP是深度学习/神经网络最有代表的部分,目前相对已经比较成熟,基于计算图的自动微分、基于Tape和运算符重载的自动微分方案、基于source2source的自动微分,都是现在主流的方案。
并行优化:随着深度学习的模型规模越来越大,模型的并行优化,也成为编译优化的一部分,包括:数据并行、算子级模型并行、Pipeline模型并行、优化器模型并行和重计算等
张量计算/循环优化:循环优化其实是一个古老的编译器的难题,在高性能计算领域,循环优化已经研究了几十年,一直没有很好的解决,但是看上去,深度学习/神经网络领域的问题,要简单一点,原因是这个领域大量的以Dense的矩阵运算为主,不像高性能计算领域那么复杂(大量稀疏/非规则的矩阵和向量运算),这为循环优化带来了很大的空间,不过即便是这样,自动scheduling、自动tilling、自动向量化这些理想的方案和技术也还远远没有成熟。
量化/…:推理侧常用的一些变换。
3)神经网络编译器未来的方向探讨
编译器形态:也许需要两类编译器同时存在,一类是面向极致高性能的AOT编译器,同时这类编译器对NPU更加友好;另外一类是JIT编译器,适合与动态图配合;
IR形态:需不需要MLIR这种统一的形态?
自动并行:配合Cost model,提供自动并行优化的能力;
自动Scheduling/Tilling/Tensorizing:可能很难全部做到,能支持大部分也可以。
以上是关于AI与传统编译器的主要内容,如果未能解决你的问题,请参考以下文章