《ggplot2:数据分析与图形艺术》笔记
Posted 萱草yy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《ggplot2:数据分析与图形艺术》笔记相关的知识,希望对你有一定的参考价值。
第1章 简介
1.3图形的语法


第2章从qplot开始入门
1、基本用法:qplot(x,y,data)
x是自变量横轴,y是因变量纵轴,data是数据框
2、图形参数
colour=I("red"),shape,size=I(2),alpha=I(1/20)
colour是(外框)颜色,fill是填充颜色,shape是点的形状,适合描述分类变量:形状和颜色
size是点的大小,适合描述连续变量:大小和颜色
alpha是点的透明度,1/20说明20个重叠在一起就会变得不透明,可以用来观察点的密集区域
3、几何对象geom=c("point","smooth")按顺序堆叠,按数据维度可划分为:
- 二维变量关系:
geom=“point”:绘制散点图geom=“smooth”:拟合一条平滑曲线,灰色区域是置信区间,不绘制标准误差则se=FASLEgeom=“boxplot”:绘制箱线胡须图,概括一系列点的分布情况geom=“path” 和 geom=“line”:在数据点之间绘制连线,一般用来探索时间和其他变量之间的关系,线条图只能创建从左到右的连线,而路径图则可以是任意方向
- 一维分布:集合对象由变量类型决定
- 连续变量:
geom=“histogram”:直方图(默认)geom=“freqpoly”:频率多边形geom=“density”:密度曲线
- 离散变量:
geom=“bar”:条形图
3.1 平滑曲线geom=“smooth”具体参数默认灰色区域是置信区间,设置se=FALSE将不绘制标准误method参数,选择不同的平滑器:
- method=“loess”,span=0。1:局部回归方法,曲线的平滑程度由span控制,内存消耗为O(n2),当n超过1000时将采用别的平滑算法。n较小时是默认选项
- method=“gam”,formula=y~s(x):mgcv包拟合广义加性模型。与lm的样条类似,但样条的阶数是通过数据估计得到的。对于大数据(n>1000)使用y~s(x,bs=“cs”)
- method=“lm”:线性模型,默认是一条直线,可通过formula=y~poly(x,2)拟合二次多项式,也可加载splines包使用样条曲线formula=y~ns(x,2),第二个参数是自由都,取值越大,曲线的波动越大
- method=“rlm”:MASS包,和lm类似,但采用更稳健的拟合算法,使得对异常值不太敏感
3.2 箱线图和扰动点图:研究连续变量随着分类变量的变化情况
- geom=“jitter”:扰动点图
- geom=“boxplot”:箱线胡须图,反映中位数等。可以配合使用colour、fill和size等
3.3 直方图和密度曲线图:展示单个变量的分布(连续变量)
- 一般绘制
geom=“histogram”直方图,binwidth设定组距(组距大反映总体特征),break可以显示指定切分位置geom=“density”:密度曲线图,adjust控制曲线的平滑程度(adjust越大曲线越平滑)
- 增加 分类型变量 控制
参数colour或者fill根据设定分类变量时,几何对象会自动拆分,并绘制多条密度曲线图或直方图3.4条形图geom=“bar”(离散变量)
- 普通条形图
- 增加 连续变量 权重: weight
3.5时间序列中的线条图和路径图
- geom=“line”:线条图,按x的取值排序(一般横轴是时间),从左到右连接
- geom=“path” :路径图,任意原始顺序连接(点的顺序反映先后时间):colour参数设置时间来反映
group设置多个序列个体,并映射到一张图中(4.5.3节)
4、分面:facets 将图形拆分成多个窗格(7.2节)
facets=row.var.name~.:单列多行
facets=row.var.name~col.var.name:多行多列
“..density..”——新语法,将密度而不是频数映射到y轴
5、其他参数
main——标题
xlab,ylab——横纵坐标轴标题。如ylab=expression(frac(y,x))=y/x
xlim,ylim——横纵坐标轴取值范围,如c(.2,1)
log——log=“xy”或者log=“x”设置某个坐标取对数
第9章 数据操作
9.1 plyr包简介
- 分组变量:用一张图内的数据分成几个部分处理
- 分面变量:用来把数据分割成几个部分,每个部分分别画在一张小图里
ddply(.data,.variable,.fun)——针对多个子集,应用对单独子集的操作函数
- subset()——用来对数据取子集
ddply(diamonds,.(color),subset,order(carat)<=2) #选取各个颜色里最小的2颗钻石
- transform()——用来进行数据变换
ddply(diamonds,.(color),transform,price=scale(price)) #每个颜色组里钻石的价格标准化
- colwise()——把一个处理向量的函数变为处理每列数据框
colwise(func)func(<data.frame>)或者colwise(func)(<dataframe>)
- numcolwise()——只对数值类型的列操作
- catcolwise()——只对分类类型的列操作
9.2“宽数据”变为“长数据”
melt()——变量不再放在各个列上,而是排成一列,每个变量都分别占其中的几行。reshape2包
data是待变形的元数据id.vars依旧放在列上位置保持不变的变量,该值通常是离散的,类似数据库中的主键measure.vars需要被放在同一列的变量,不同变量放在同一列并根据变量名进行分组。
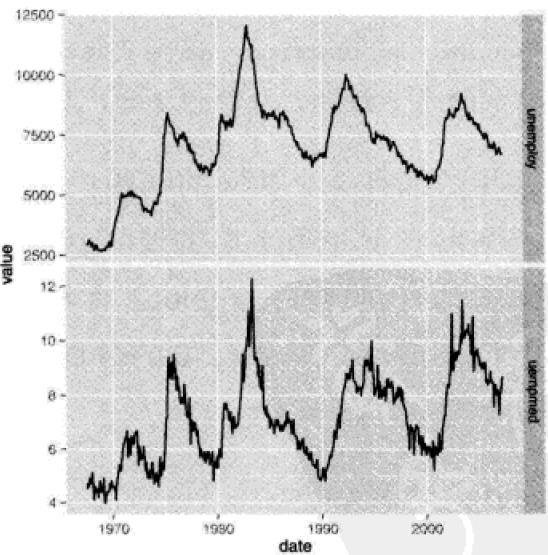
- 多重时间序列图
在一张图上画2个时间序列:
1、画图时把两个变量放在两个不同的图层上2、把数据变成一个“长数据”,然后根据variable变量区分
分析:由于两个时间序列取值差异太大,常常会导致其中一个序列值趋近一条直线改进方法:
1、把数值调整到相同范围:做极差正规化变换2、使用自由标度的分面qplot(date,value,data=emp,geom="line")+facet_grid(variable~.,scale=“free_y”)
- 平行坐标图
每个样本画一条曲线时(需要保证样本取值可比),将行名rowname作为分组变量,同时结合大数据作图方法(透明度和聚类)
9.3 ggplot()方法
主要思想:将数据变形和图形展示尽可能分开进行,而不必让画图局限在某些特殊函数里。ggplot负责绘图,fortify()负责数据变形
ggplot是一种泛型函数,只提供作图所需要的工具。
- 线性模型


- 编写自己的方法
其它:
第4章:
1、图形属性映射:aes(x=x,y=y,colour=z)图形属性参数
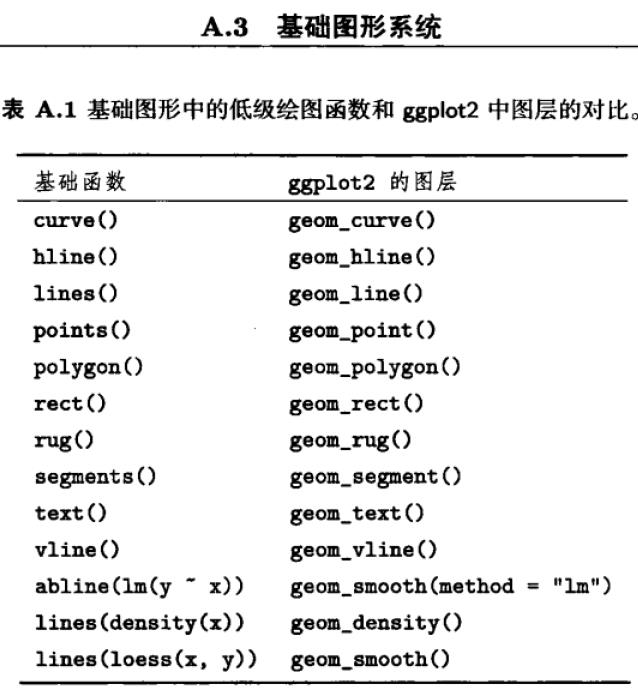
2、统计变换

3、位置调整

4、整合

以上是关于《ggplot2:数据分析与图形艺术》笔记的主要内容,如果未能解决你的问题,请参考以下文章