CNN- 数据预处理
Posted 路萧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CNN- 数据预处理相关的知识,希望对你有一定的参考价值。
对于CNN输入的数据,常见的有三种处理方式:
1.Mean subtraction. 将数据的每一维特征都减去平均值。在numpy 中 X -= np.mean(X, axis = 0)
2.Normalization 归一化数据,使数据在相同尺度。 在numpy 中 X /= np.std(X, axis = 0)
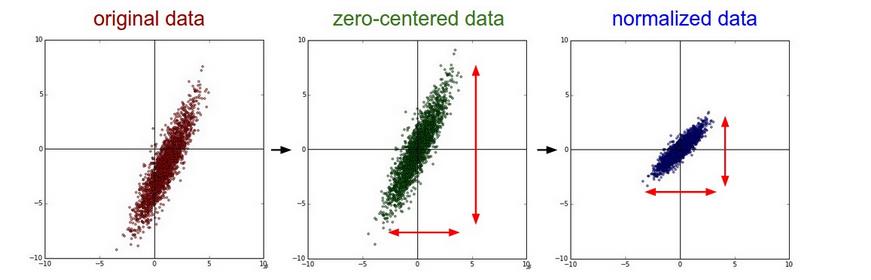
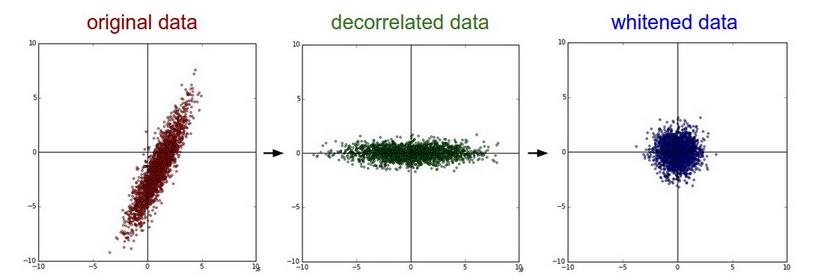
3. PCA and Whitening. 首先均值化数据,然后求协方差矩阵。
X -= np.mean(X, axis = 0) //求均值
cov = np.dot( X.T, X) / X.shape[0] // 求协方差矩阵
U,S,V = np.linalg.svd(cov) //奇异值分解,其中 U 为特征向量,S为奇异值分解向量为特征向量的平方
Xrot = np.dot(X, U) //去除数据相关性
Xrot_reduced = np.dot(X, U[:,:100]) 降维到 100 维
Xwhite = Xrot / np. sqrt(s + 1e-5) //白化数据 1e-5 为防止除0
可视化数据:例子为CIFAR-10 images
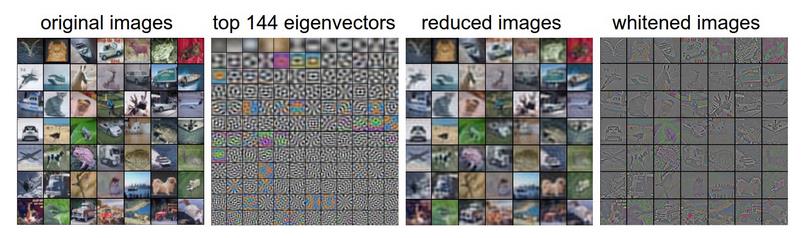
左边第一张图片为CIFAR-10 中的49张图片(每张图片有3072个特征),第二张图片为3072特征向量中的前144个特征,第三张图片为通过PCA降维降到144维,使用的是图二中的前144维,第四张图片为白化后的图片。
常见的数据处理是 Mean substraction 和 Normalization.
权重的设置
陷阱:全零初始化 如果参数是全零,导致输出的结果相同,那么通过反向传播计算梯度也相同,那么参数也不会更新。
用较小的数随机化: W = 0.01* np.random.randn(D,H) randn 返回的样本满足标准正态分布.
标准化变量 1/sqrt(n) W = np.random.randn(n) / sqrt(n) 或者 W = np.random.randn(n) / sqrt(2.0/n)
初始化偏置项
很常见的是将偏置项设置为0,ReLu 激活函数有些人会设置为 0.01, 在实际中通常设置为 W = np. random.randn(n) * sqrt(2.0/n)
Batch Normalization
发现一个讲解Batch Normalization 的博客 详见http://blog.csdn.net/hjimce/article/details/50866313
正则化
有多种方法来防止神经网络的过拟合。
L2 范式 w = w + 1/2 λw2
L1 范式 w = w + λ|w| 向量各元素绝对值之和
L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0
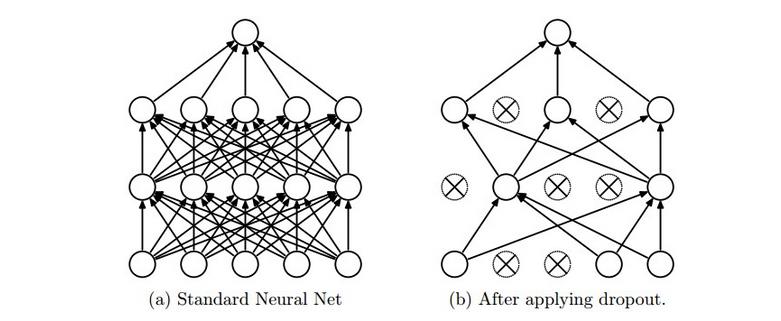
Dropout
Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了。如下图所示
主要参考CS231n 课程。
以上是关于CNN- 数据预处理的主要内容,如果未能解决你的问题,请参考以下文章