视图与冗余物理表的查询性能测试
Posted rongyongfeikai2
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视图与冗余物理表的查询性能测试相关的知识,希望对你有一定的参考价值。
如果有30张表,他们各自有各自的自定义字段,也有一部分公有字段;需要将公有字段归一起来统一查询,一般而言有两种方式:1.公共字段物理表 数据在入库/更新时,更新自己的表的数据,同时亦将数据更新入公共表中
2.视图 数据在入库/更新时,更新自己的表的数据,视图因为是逻辑上的表所以查询时可以查询到更新
两种方式各有优劣:
1.公共字段方式
优点:查询公共表时占优势,sql比较简单,pg在解析和优化sql时耗时都比较短;而且数据在一张表中,不需要扫描多张表
缺点:APP表和公共字段表必须同时更新,需要事务[事务由于需要写预写日志等,会降低写性能];如果表上有索引时,增更删时均需要更新索引,也会降低写性能,尤其是表不断变大的情况下
2.视图的方式
优点:只需要更新各自的APP表即可,各APP表的数据量均会小于总数据量,写占优
缺点:表数量上升,涉及到多表union all,查询时会慢
--当然以上的查询均是指用到公共字段的查询时,APP内部只用自己的APP表,所以查询性能并不受上述影响
所以这两种方式类似于一个南拳北腿,各有擅长的领域,并不好粗暴的进行比较。
不过,对于视图的查询性能差到怎样一个地步,我们还是颇有兴趣的。
环境:单机实体机,8个逻辑核,32G内存,CentOS7.0操作系统,PostgreSQL9.4
表:
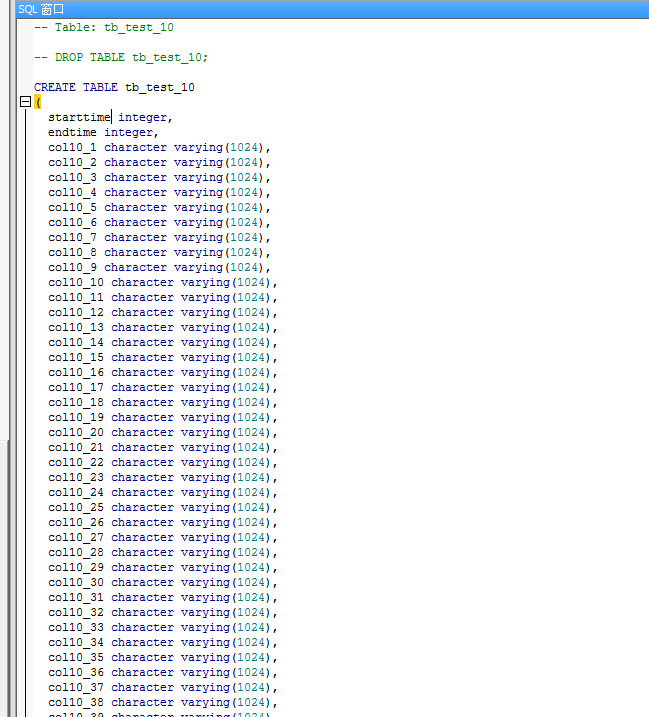
APP表:tb_test_1/.../tb_test_30[总共30张表,分别有starttime,endtime以及col[表id]_1/col[表id]_2/.../col[表id]_45总共47个字段
如下图所示:
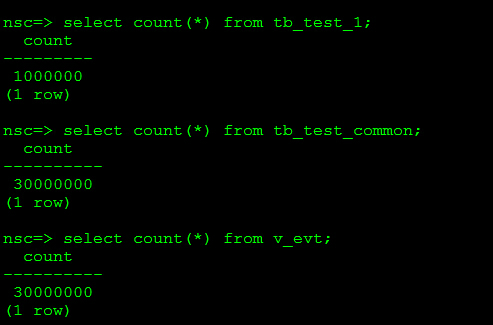
视图:v_evt,分别有startime,endtime以及col0_1/.../col0_40(对应app表的前40个字段)总共42个字段
APP表每张表100万数据量,30个APP表,对应到tb_test_common中总共3000万数据量
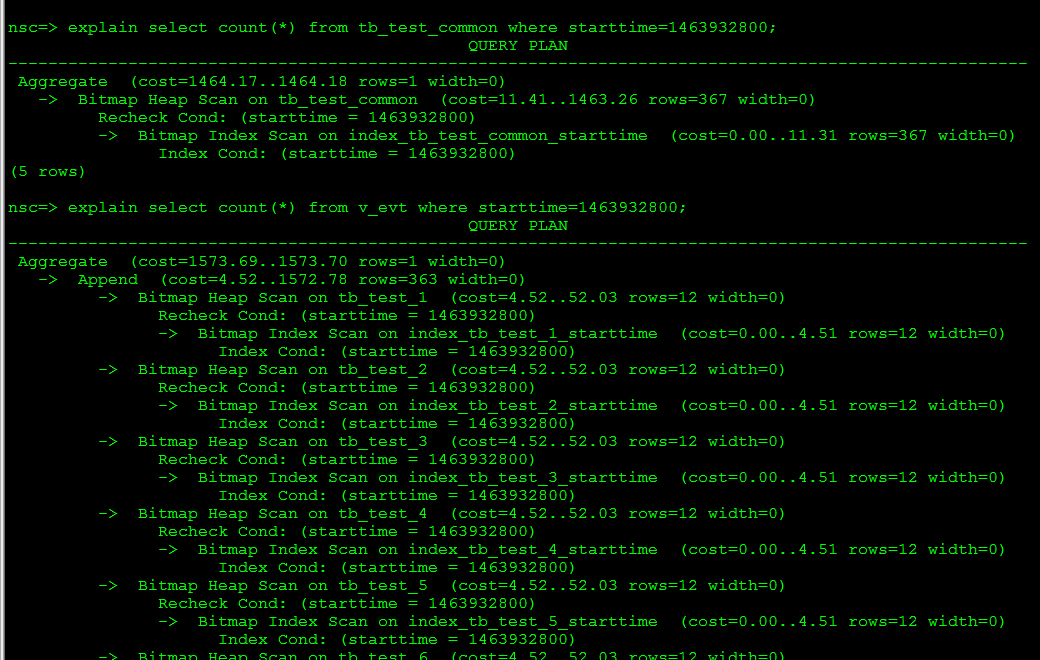
在每张表的starttime和endtime上均建立索引,增快按照starttime和endtime进行where查询时的速度【当然,前面提过,索引一方面消耗存储空间,一方面insert/update时均需要更新索引,降低写速度】
我们查一下执行规划,可以清晰看到select语句是走了bitmap index scan的。
数据准备好了,我们设计了5种比对方式,分别为:
执行结果(第一次执行结果,后面视图查询速度会明显加快,因为有执行规划的缓存)
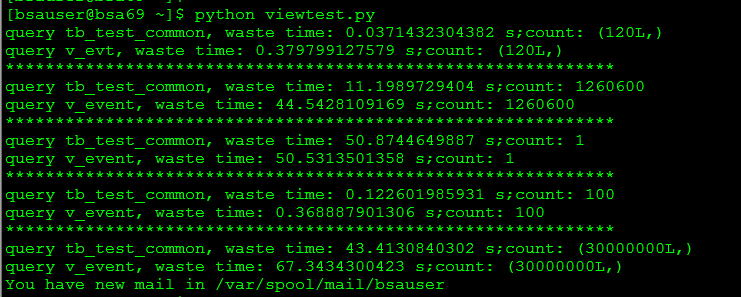
我用个表格展示,会更加清晰:
|
| 公共字段表 | 视图 |
| where条件过滤 | 0.0371432304382 | 0.379799127579 |
| 过滤条件+order by limit 10 | 11.1989729404 | 44.5428109169 |
| 聚合函数 | 50.8744649887 | 50.5313501358 |
| 不进行过滤,全表order by取limit | 0.122601985931 | 0.368887901306 |
| count | 43.4130840302 | 67.3434300423 |
上面的时间均是以秒作为单位。大家应该对性能大概有了个感性的认识。
====华丽分割线,以下是构建数据的脚本======================
#coding:utf-8
import psycopg2
import traceback
import random
import time
HOST="localhost"
DBNAME=""
USERNAME=""
PASSWORD=""
#数据库时间为2016-05-23当天
starttime = 1463932800
endtime = 1464019199
def create_tables(nums):
arr = list()
for i in range(0,nums):
tablename = "tb_test_"+str(i)
if i == 0:
tablename = 'tb_test_common'
sql = "create table " + tablename + "("\\
+ "starttime integer,"\\
+ "endtime integer,"
colnum = 46
#公共表时间字段+40个字段,普通APP表时间字段+45个字段
if i == 0:
colnum = 41
for j in range(1,colnum):
sql += "col"+str(i)+"_"+str(j)+" varchar(1024)"
if j != colnum - 1:
sql += ","
sql += ")"
arr.append(sql)
return ";".join(arr)
#写一个一百万数据的文件
def write_million_data(filepath):
print "create data file start ..."
f = open(filepath,"w")
for i in range(0,1000000):
curstart = random.randint(starttime,endtime)
f.write(str(curstart)+",")
f.write(str(random.randint(curstart,endtime))+",")
for j in range(0,45):
f.write("hello")
if j != 44:
f.write(",")
f.write("\\n")
f.close()
print "create data file end ..."
def create_view(nums):
sql = "create view v_evt as "
for i in range(1,nums):
sql += "select starttime,endtime,"
for j in range(1,41):
sql += "col"+str(i)+"_"+str(j)+" as col_0_"+str(j)
if j != 40:
sql += ","
sql += " from tb_test_"+str(i)+" "
if i != nums-1:
sql += " union all "
return sql
def init_all():
filepath = "/tmp/view_data"
write_million_data(filepath)
conn = psycopg2.connect(host=HOST,dbname=DBNAME,user=USERNAME,password=PASSWORD)
cur = conn.cursor()
#新建31张表;第一张为公有字段表,其他30张为app表
cur.execute(create_tables(31))
conn.commit()
print "create tables"
#将数据copy入第1-30的APP表和公共表
for i in range(1,31):
cur.copy_from(open(filepath,"r"),"tb_test_"+str(i),sep=",")
print "copy data into table"
conn.commit()
for i in range(1,31):
insql = "insert into tb_test_common select starttime,endtime,"
for j in range(1,41):
insql += "col"+str(i)+"_"+str(j)
if j != 40:
insql += ','
insql += " from tb_test_"+str(i)
print insql
cur.execute(insql)
conn.commit()
#在starttime和endtime字段建立索引
for i in range(1,31):
cur.execute("create index index_tb_test_"+str(i)+"_starttime on tb_test_"+str(i)+"(starttime)")
cur.execute("create index index_tb_test_"+str(i)+"_endime on tb_test_"+str(i)+"(endtime)")
conn.commit()
print "create index on index_tb_test_"+str(i)
cur.execute("create index index_tb_test_common_starttime on tb_test_common(starttime)")
cur.execute("create index index_tb_test_common_endime on tb_test_common(endtime)")
conn.commit()
print "create index on tb_test_common"
#建立视图
vsql = create_view(31)
cur.execute(vsql)
conn.commit()
print "create view"
#将数据写入40张表
conn.close()
if __name__ == '__main__':
#init_all()
'''冗余表的优点在于查询,而缺点在于增删改[需要事务,同时需要写两份]'''
'''视图的优点在于增删改只需要改原始物理表,而缺点在于查询'''
'''所以以下测试是用冗余表之长对决视图之短'''
'''为了查询性能非常优秀,我为公共表和普通表的字段startime和endtime字段建立索引,并在查询条件中使用它'''
'''但众所周知的,有索引意味着insert和update均需要更新索引,所以写入速度是影响的'''
#进行性能测试
conn = psycopg2.connect(host=HOST,dbname=DBNAME,user=USERNAME,password=PASSWORD)
cur = conn.cursor()
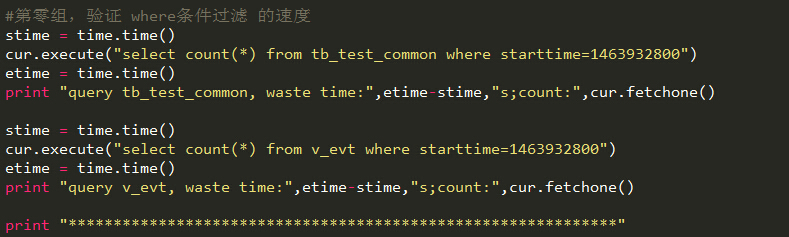
#第零组,验证 where条件过滤 的速度
stime = time.time()
cur.execute("select count(*) from tb_test_common where starttime=1463932800")
etime = time.time()
print "query tb_test_common, waste time:",etime-stime,"s;count:",cur.fetchone()
stime = time.time()
cur.execute("select count(*) from v_evt where starttime=1463932800")
etime = time.time()
print "query v_evt, waste time:",etime-stime,"s;count:",cur.fetchone()
print "*************************************************************"
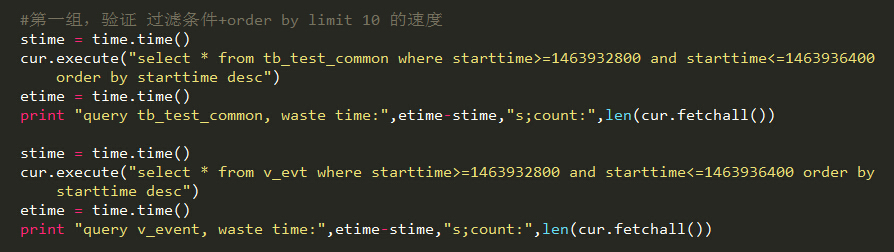
#第一组,验证 过滤条件+order by limit 10 的速度
stime = time.time()
cur.execute("select * from tb_test_common where starttime>=1463932800 and starttime<=1463936400 order by starttime desc")
etime = time.time()
print "query tb_test_common, waste time:",etime-stime,"s;count:",len(cur.fetchall())
stime = time.time()
cur.execute("select * from v_evt where starttime>=1463932800 and starttime<=1463936400 order by starttime desc")
etime = time.time()
print "query v_event, waste time:",etime-stime,"s;count:",len(cur.fetchall())
print "*************************************************************"
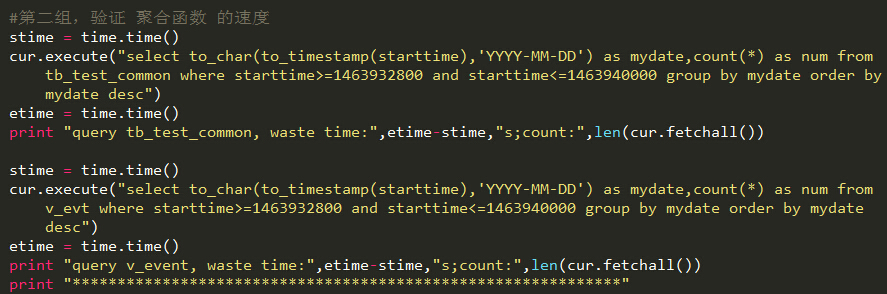
#第二组,验证 聚合函数 的速度
stime = time.time()
cur.execute("select to_char(to_timestamp(starttime),'YYYY-MM-DD') as mydate,count(*) as num from tb_test_common where starttime>=1463932800 and starttime<=1463940000 group by mydate order by mydate desc")
etime = time.time()
print "query tb_test_common, waste time:",etime-stime,"s;count:",len(cur.fetchall())
stime = time.time()
cur.execute("select to_char(to_timestamp(starttime),'YYYY-MM-DD') as mydate,count(*) as num from v_evt where starttime>=1463932800 and starttime<=1463940000 group by mydate order by mydate desc")
etime = time.time()
print "query v_event, waste time:",etime-stime,"s;count:",len(cur.fetchall())
print "*************************************************************"
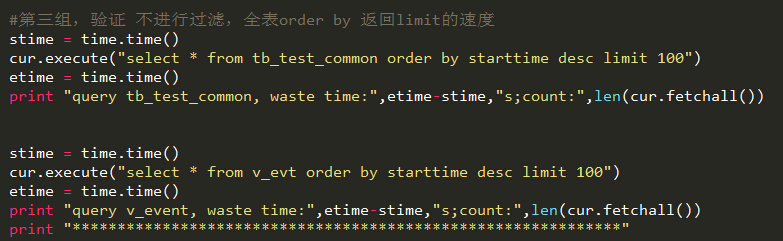
#第三组,验证 不进行过滤,全表order by 返回limit的速度
stime = time.time()
cur.execute("select * from tb_test_common order by starttime desc limit 100")
etime = time.time()
print "query tb_test_common, waste time:",etime-stime,"s;count:",len(cur.fetchall())
stime = time.time()
cur.execute("select * from v_evt order by starttime desc limit 100")
etime = time.time()
print "query v_event, waste time:",etime-stime,"s;count:",len(cur.fetchall())
print "*************************************************************"
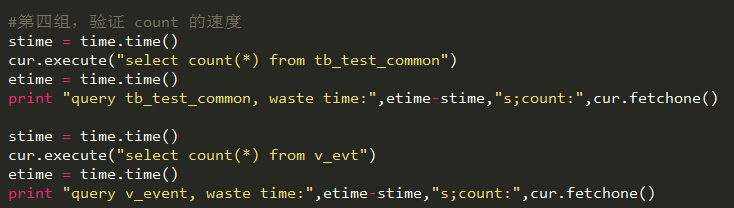
#第四组,验证 count 的速度
stime = time.time()
cur.execute("select count(*) from tb_test_common")
etime = time.time()
print "query tb_test_common, waste time:",etime-stime,"s;count:",cur.fetchone()
stime = time.time()
cur.execute("select count(*) from v_evt")
etime = time.time()
print "query v_event, waste time:",etime-stime,"s;count:",cur.fetchone()
cur.close()
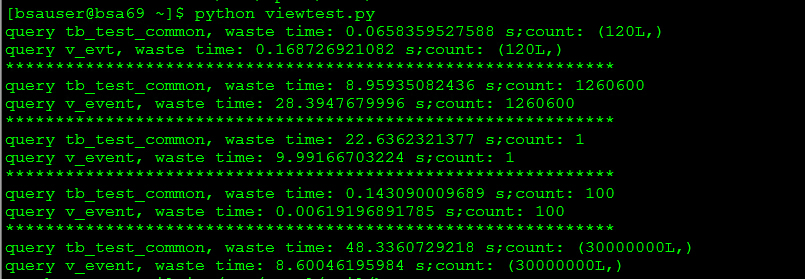
conn.close()另外附一张二次查询的结果,可以看到视图的查询性能提升明显(因为查询规划被缓存了)
以上是关于视图与冗余物理表的查询性能测试的主要内容,如果未能解决你的问题,请参考以下文章