Cortex-A8处理器memcpy的优化方案
Posted kerneler_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Cortex-A8处理器memcpy的优化方案相关的知识,希望对你有一定的参考价值。
公司产品涉及到视频编解码和人脸识别,但是出现帧率太低的现象,同事做了一些测试,最后问题定位到应用程序中memcpy慢,特别是由uncached区域(视频采集buf,使用mmap对/dev/mem映射到用户空间)到cached区域(用户空间malloc),因此需要想办法进行下优化。
首先交代下设备处理器背景,处理器是公司自研,使用ARM Cortex-A8处理器核,CPU为800MHZ,SAXI总线为533MHZ。后续一系列测试都是在相同的clk下进行,保证测试数据的硬件环境一致,有可对比性。
同事对系统下各种场景的memcpy进行一系列测试。测试数据如下。
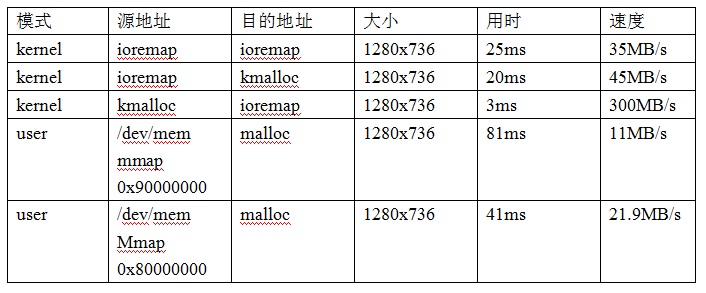
对这个表的测试方法进行下说明,kernel和user空间下分别使用do_gettimeofday和gettimeofday获取时间,公司SOC的地址空间中0x80000000开始是ddr空间,kernel的cmdline中mem=256MB,因此0x80000000-0x90000000为lowmem。
mmap映射/dev/mem可以完成整个4G空间的映射(关于mem驱动的原理,可以看我的另一篇学习powerpc /dev/mem的博文,http://blog.csdn.net/skyflying2012/article/details/47611399),但是具体访问权限以及属性还需要看mem驱动中mmap函数的实现。
公司设备的应用场景是从物理地址0x90000000的uncached区域到cached区域进行memcpy,测试速度仅有11MB/s,这对于1080P的人脸识别完全不够,优化是必须的。
仔细对比分析这组测试数据,我有以下几个疑问。
1 用户空间mmap mem的uncached区域(mem驱动中映射页表属性默认是uncached)向malloc出来的cached缓冲区拷贝,0x80000000区域为什么比0x90000000区域的拷贝快?
2 kernel下ioremap的uncached区域向kmalloc的cached区域拷贝,为什么比用户空间的快很多?
3 kmalloc的cached区域向ioremap的uncached区域拷贝,为什么比kernel下ioremap的uncached区域向kmalloc的cached区域拷贝要慢很多?
3个问题逐步递进,都分析明白解决了,特别是第2点,内核memcpy远快于用户空间,就能找到一些对用户空间memcpy的优化方法。
那我们就来逐步的分析下这3个问题。
1 用户空间mmap mem的uncached区域向malloc出来的cached缓冲区拷贝,0x80000000区域为什么比0x90000000区域的拷贝快?
这2者都是在用户空间进行测试,测试代码完全一致,统计方法也都一致,memcpy都是使用的libc库的实现。为什么memcpy速度不一样,想来想去也只有可能是这2个区域的页表属性不一样,有可能一个cached一个uncached,这个需要从mem驱动的实现下手。
公司kernel版本是3.4.55。mem实现在kernel的driver/char/mem.c中,找到mem的mmap实现,如下
static int mmap_mem(struct file *file, struct vm_area_struct *vma)
{
size_t size = vma->vm_end - vma->vm_start;
if (!valid_mmap_phys_addr_range(vma->vm_pgoff, size))
return -EINVAL;
if (!private_mapping_ok(vma))
return -ENOSYS;
if (!range_is_allowed(vma->vm_pgoff, size))
return -EPERM;
if (!phys_mem_access_prot_allowed(file, vma->vm_pgoff, size,
&vma->vm_page_prot))
return -EINVAL;
vma->vm_page_prot = phys_mem_access_prot(file, vma->vm_pgoff,
size,
vma->vm_page_prot);
/* Remap-pfn-range will mark the range VM_IO and VM_RESERVED */
if (remap_pfn_range(vma,
vma->vm_start,
vma->vm_pgoff,
size,
vma->vm_page_prot)) {
return -EAGAIN;
}
return 0;
}mmap_mem开始会进行映射区域的一些检查,然后设置映射属性,最后调用remap_pfn_range建立真正的页表。我们所关心的是映射属性,就是phys_mem_access_prot的实现。该函数在mem.c中有一个实现,对于ARM架构来说,phys_mem_access_prot默认设置属性位uncached。
但是由于公司设备在menuconfig时定义了CONFIG_ARM_DMA_MEM_BUFFERABLE(该选项使DMA一致性映射时属性为bufferable而不是uncached,但是发现一致性映射工作正常,很奇怪为什么选这个),phys_mem_access_prot的实现在arch/arm/mm/mmu.c中,如下。
#ifdef CONFIG_ARM_DMA_MEM_BUFFERABLE
pgprot_t phys_mem_access_prot(struct file *file, unsigned long pfn,
unsigned long size, pgprot_t vma_prot)
{
if (!pfn_valid(pfn))
{
return pgprot_noncached(vma_prot);
}
else if (file->f_flags & O_SYNC)
{
return pgprot_writecombine(vma_prot);
}
return vma_prot;
}
EXPORT_SYMBOL(phys_mem_access_prot);
#endif应用程序测试代码中mem设备open时设置了属性O_SYNC,因此主要看pfn_valid实现了,看字面意思,该pfn页有效,则属性为bufferable,反之为uncached。pfn_valid在arch/arm/mm/init.c中,如下。
#ifdef CONFIG_HAVE_ARCH_PFN_VALID
int pfn_valid(unsigned long pfn)
{
return memblock_is_memory(__pfn_to_phys(pfn));
}
EXPORT_SYMBOL(pfn_valid);memblock_is_memory实现在/mm/memblock.c中,该函数实现这里不详细说了,后续在我的内存管理学习笔记专栏里会详细学习。
这里简单说明下,memblock.c中维护了memblock.memory(可用)和memblock.reserve(保留)2个链表,arm-linux启动中,在paging_init建立页表前,会调用arm_memblock_init对memblock链表进行初始化,arm_memblock_init中会将cmdline中指定的lowmem调用memblock_add添加到memblock.memory链表中(公司kernel没有配置CONFIG_HIGHMEM)。
而memblock_is_memory是在memblock.memory链表中搜索是否有该物理页。
因此pfn_valid对于lowmem(0x80000000-0x90000000)返回ture,对于其他物理地址则返回false。
返回上级函数phys_mem_access_prot,一目了然,该函数的逻辑是对于mmap映射lowmem(0x80000000-0x90000000)区域,页表映射属性prot配置为bufferable,其他区域页表属性配置为uncached。
这样第一个问题就解决了,对于公司设备的kernel,用户空间mmap mem驱动,物理地址在0x80000000-0x90000000区域内,为bufferable,其他区域为uncached(这样reg空间也可以映射出来访问,实现用户空间驱动)。所以映射lowmem区域的拷贝速度要快于其他区域。
不过要说明下的是,这个问题是因为该kernel配置了CONFIG_ARM_DMA_MEM_BUFFERABLE,使用了arm特定的phys_mem_access_prot实现。
如果不配置该选项,则mmap_mem使用了mem.c中的phys_mem_access_prot实现。该实现中如果open时指定了O_SYNC或者O_DSYNC,则所有空间的映射属性都配置为uncached。
2 kernel下ioremap的uncached区域向kmalloc的cached区域拷贝,为什么比用户空间uncached到cached区域拷贝要快很多?
这个问题如果解决,对于优化用户空间memcpy会很有帮助,对于同事测试的数据,我从以下3个方面进行了分析调试。
(1)统计时间的准确性不一致,需要修改。
kernel下使用do_gettimeofday获取时间,kernel下是没有调度的(进程调度发生在由内核态返回时,检查是否有就绪进程,然后调度。内核态下即使发生中断,都还只是内核态下的相互切换,不会有调度),但是用户空间有进程调度(中断 系统调用等异常,导致陷入内核态,再返回时产生调度),进程调度对时间统计准确性有影响,一是会导致gettimeofday时间统计没有内核态下那么准确(有部分时间是其他进程的开销),二是进程调度还需要切换进程的页表(每个进程独立拥有16KB内存页表),进程调度导致页表切换,MMU需要重新读入TLB,我想也会对性能有所影响吧。
因此要想办法统一时间统计方法,使应用程序暂时不再调度。我的解决方法如下。
a 保证应用程序不产生调度
在应用程序中将处理器的寄存器空间mmap出来,在开始测试前配置中断寄存器将中断全部mask,测试结束再unmask,保证没有中断产生而陷入内核态,
再对malloc区域提前访问,保证页表提前建立,不会产生缺页异常(malloc缓冲区在访问时才缺页异常建立页表)。
不使用gettimeofday系统调用,二是直接读取timer计数,利用计数来计算用时。
b 对于内核测试代码,也不使用do_gettimeofday,直接读取timer计数,计算用时,与应用程序统一。
对应用程序进行修改后,再次测试1MB数据从uncached区域到cached区域拷贝,计算用时是68ms,速度为14.7MB/s。相比于同事的测试数据的确有所提升,这说明用户空间进程调度对时间统计是有些影响,但是排除进程调度影响后的测试速度跟内核的速度还是相差很大。看来根本原因还没有找到。
(2)memcpy实现不一致。
kernel不依赖于任何库,自己实现memcpy,应用程序的memcpy是依赖于libc中的实现,这2者实现可能有差异。
这个的解决方法就简单粗暴了,对比memcpy的实现呗。
kernel的memcpy实现在arch/arm/lib/memcpy.S中,是汇编代码,粗略看了下实现。
主要是使用PLD指令(armv5以上支持)进行数据预取,并且使用stmia/ldmia进行数据的32 bytes批量读写。
而对于应用程序的memcpy实现,如果去找libc的实现,要麻烦些,需要顺着所使用的编译器一步步的找相应的版本,
这里想了一个懒办法。就是将应用程序静态编译,然后反汇编找memcpy实现,在反汇编文件中找到memcpy实现,如下:
00014104 <memcpy>:
14104: e3520003 cmp r2, #3 ; 0x3
14108: e92d07f0 push {r4, r5, r6, r7, r8, r9, sl}
1410c: 8a000009 bhi 14138 <memcpy+0x34>
14110: e3520000 cmp r2, #0 ; 0x0
14114: 0a000005 beq 14130 <memcpy+0x2c>
14118: e3a0c000 mov ip, #0 ; 0x0
1411c: e7d1300c ldrb r3, [r1, ip]
14120: e7c0300c strb r3, [r0, ip]
14124: e28cc001 add ip, ip, #1 ; 0x1
14128: e152000c cmp r2, ip
1412c: 8afffffa bhi 1411c <memcpy+0x18>
14130: e8bd07f0 pop {r4, r5, r6, r7, r8, r9, sl}
14134: e12fff1e bx lr
14138: e3100003 tst r0, #3 ; 0x3
1413c: e0809002 add r9, r0, r2
14140: 01a0c000 moveq ip, r0
14144: 01a04001 moveq r4, r1
14148: 0a000005 beq 14164 <memcpy+0x60>
1414c: e1a0c000 mov ip, r0
14150: e4d13001 ldrb r3, [r1], #1
14154: e4cc3001 strb r3, [ip], #1
14158: e31c0003 tst ip, #3 ; 0x3
1415c: 1afffffb bne 14150 <memcpy+0x4c>
14160: e1a04001 mov r4, r1
14164: e2117003 ands r7, r1, #3 ; 0x3
14168: 0a00001c beq 141e0 <memcpy+0xdc>
1416c: e06ca009 rsb sl, ip, r9
14170: e2672000 rsb r2, r7, #0 ; 0x0
14174: e35a0003 cmp sl, #3 ; 0x3
14178: e7916002 ldr r6, [r1, r2]
1417c: da00000d ble 141b8 <memcpy+0xb4>
14180: e2673004 rsb r3, r7, #4 ; 0x4
14184: e0815002 add r5, r1, r2
14188: e1a08183 lsl r8, r3, #3
1418c: e1a0100a mov r1, sl
14190: e1a07187 lsl r7, r7, #3
14194: e5b52004 ldr r2, [r5, #4]!
14198: e2411004 sub r1, r1, #4 ; 0x4
1419c: e1a03812 lsl r3, r2, r8
141a0: e1833736 orr r3, r3, r6, lsr r7
141a4: e3510003 cmp r1, #3 ; 0x3
141a8: e48c3004 str r3, [ip], #4
141ac: e2844004 add r4, r4, #4 ; 0x4
141b0: e1a06002 mov r6, r2
141b4: cafffff6 bgt 14194 <memcpy+0x90>
141b8: e159000c cmp r9, ip
141bc: 83a02000 movhi r2, #0 ; 0x0
141c0: 9affffda bls 14130 <memcpy+0x2c>
141c4: e7d43002 ldrb r3, [r4, r2]
141c8: e7cc3002 strb r3, [ip, r2]
141cc: e2822001 add r2, r2, #1 ; 0x1
141d0: e08c3002 add r3, ip, r2
141d4: e1590003 cmp r9, r3
141d8: 8afffff9 bhi 141c4 <memcpy+0xc0>
141dc: eaffffd3 b 14130 <memcpy+0x2c>
141e0: e06c6009 rsb r6, ip, r9
141e4: e356003f cmp r6, #63 ; 0x3f
141e8: da000026 ble 14288 <memcpy+0x184>
141ec: e1a05006 mov r5, r6
141f0: e5943000 ldr r3, [r4]
141f4: e2455040 sub r5, r5, #64 ; 0x40
141f8: e58c3000 str r3, [ip]
141fc: e5942004 ldr r2, [r4, #4]
14200: e355003f cmp r5, #63 ; 0x3f
14204: e58c2004 str r2, [ip, #4]
14208: e5941008 ldr r1, [r4, #8]
1420c: e1a06005 mov r6, r5
14210: e58c1008 str r1, [ip, #8]
14214: e594300c ldr r3, [r4, #12]
14218: e58c300c str r3, [ip, #12]
1421c: e5942010 ldr r2, [r4, #16]
14220: e58c2010 str r2, [ip, #16]
14224: e5943014 ldr r3, [r4, #20]
14228: e58c3014 str r3, [ip, #20]
1422c: e5942018 ldr r2, [r4, #24]
14230: e58c2018 str r2, [ip, #24]
14234: e594301c ldr r3, [r4, #28]
14238: e58c301c str r3, [ip, #28]
1423c: e5942020 ldr r2, [r4, #32]
14240: e58c2020 str r2, [ip, #32]
14244: e5943024 ldr r3, [r4, #36]
14248: e58c3024 str r3, [ip, #36]
1424c: e5942028 ldr r2, [r4, #40]
14250: e58c2028 str r2, [ip, #40]
14254: e594302c ldr r3, [r4, #44]
14258: e58c302c str r3, [ip, #44]
1425c: e5942030 ldr r2, [r4, #48]
14260: e58c2030 str r2, [ip, #48]
14264: e5943034 ldr r3, [r4, #52]
14268: e58c3034 str r3, [ip, #52]
1426c: e5942038 ldr r2, [r4, #56]
14270: e58c2038 str r2, [ip, #56]
14274: e594303c ldr r3, [r4, #60]
14278: e2844040 add r4, r4, #64 ; 0x40
1427c: e58c303c str r3, [ip, #60]
14280: e28cc040 add ip, ip, #64 ; 0x40
14284: caffffd9 bgt 141f0 <memcpy+0xec>
14288: e356000f cmp r6, #15 ; 0xf
1428c: da00000e ble 142cc <memcpy+0x1c8>
14290: e06c1009 rsb r1, ip, r9
14294: e5943000 ldr r3, [r4]
14298: e2411010 sub r1, r1, #16 ; 0x10
1429c: e58c3000 str r3, [ip]
142a0: e5942004 ldr r2, [r4, #4]
142a4: e351000f cmp r1, #15 ; 0xf
142a8: e58c2004 str r2, [ip, #4]
142ac: e5943008 ldr r3, [r4, #8]
142b0: e1a06001 mov r6, r1
142b4: e58c3008 str r3, [ip, #8]
142b8: e594200c ldr r2, [r4, #12]
142bc: e2844010 add r4, r4, #16 ; 0x10
142c0: e58c200c str r2, [ip, #12]
142c4: e28cc010 add ip, ip, #16 ; 0x10
142c8: cafffff1 bgt 14294 <memcpy+0x190>
142cc: e3560003 cmp r6, #3 ; 0x3
142d0: daffffb8 ble 141b8 <memcpy+0xb4>
142d4: e06c2009 rsb r2, ip, r9
142d8: e2422004 sub r2, r2, #4 ; 0x4
142dc: e4943004 ldr r3, [r4], #4
142e0: e3520003 cmp r2, #3 ; 0x3
142e4: e48c3004 str r3, [ip], #4
142e8: cafffffa bgt 142d8 <memcpy+0x1d4>
142ec: eaffffb1 b 141b8 <memcpy+0xb4>libc中的memcpy实现中循环批量的使用ldr/str指令进行一次4bytes的数据读写。这么看来的确是不如kernel下的memcpy更加高效。那就想办法将kernel下的memcpy应用在用户程序中。
为了首先验证下kernel下的memcpy是否能提高应用程序的拷贝速度,直接将kernel下编译生成的memcpy.o与我的应用程序静态链接,为了确保的确是链接了memcpy.o中的memcpy,而不是libc库的。将静态链接的程序反汇编进行检查,的确是使用的memcpy.o中的memcpy实现。然后进行对比拷贝测试,结果如下。
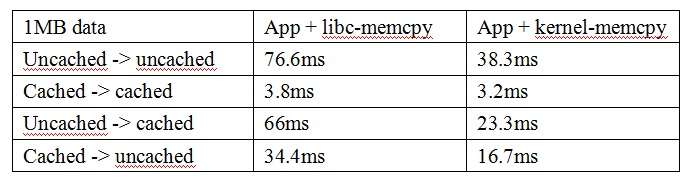
可以看出,对于有uncache区域参与的memcpy,拷贝速度提高1倍左右。
但是对于cached到cached区域的memcpy,仅仅提升15%左右。
这说明PLD预取对拷贝影响更大,cached区域相互拷贝,cache控制器会预取cache line(32bytes)进来,因此再使用PLD预取不会再起很大作用,而仅仅是stmia/ldmia指令相较于str/ldr指令速度再略有提升。
我的理解,可以粗略估计,uncached区域性能提升1倍,PLD预取起了85%的效果,stmia/ldmia起了15%效果。
不管怎么说,总算是找到了memcpy这个可以优化的点了。
(3)页表映射的属性是否一致。
能影响访问速度的页表属性我所知道的只有cached/uncached。我的理解不管内核还是用户空间,从uncached到cached拷贝,只要是页表建立,属性确定,那么访问速度就应该是一样的。如果还不一样,看来是有别的页表属性对访问速度有影响?
即使使用kernel的memcpy,应用程序的拷贝还是比kernel的慢一些,现在能想到的不一致因素都已经保证一致了,也只有考虑页表的属性了。对于这个问题的解决,还是结合第三个疑问来一起分析。
3 kmalloc的cached区域向ioremap的uncached区域拷贝,为什么比kernel下ioremap的uncached区域向kmalloc的cached区域拷贝要慢很多?
这个问题其实是一个数据流方向问题,根据同事的测试数据可以看出,从uncached区域读取比向uncached区域写入的拷贝要慢很多。那就直接测试下uncached区域的读写。
为了保证读写的可比性 透明性,都是用嵌入式汇编编写。
读取测试代码如下。
asm(
"mov r0, %0\\n"
"add r1, r0, #0x100000\\n"
"1: ldr r2, [r0], #4\\n"
"cmp r0, r1\\n"
"bne 1b\\n"
:
:"r"(addr_nc)
:"r0", "r1", "r2"
);写入测试代码如下。
asm(
"mov r0, %0\\n"
"add r1, r0, #0x100000\\n"
"ldr r3, =0x12345678\\n"
"2: str r3, [r0], #4\\n"
"cmp r0, r1\\n"
"bne 2b\\n"
:
:"r"(addr_nc)
:"r0", "r1", "r3"
);将应用程序编译后再反汇编查看,保证对于循环的读写没有进行优化。
测试发现,写入1MB数据使用4.7ms,读取1MB数据使用36.8ms。相差了近8倍!。
在uboot以及应用程序中也加入该汇编代码进行测试,并且让IC验证工程师对读写汇编代码进行了FPGA仿真,将memcpy测试数据加进来,测试结果如下。
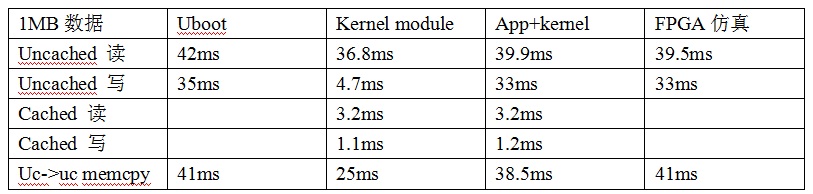
uboot和FPGA下关闭了dcached,因此没有测试cached操作数据。
可以看出cached区域内的拷贝读写,kernel app都是一致的,但是uncached参与的拷贝读写kernel跟uboot app就有差别了。uboot app中的读写速度跟FPGA仿真接近。
IC工程师在查看仿真波形后,解释说读比写多出来的时间是CPU内部的时间,而不是总线上的时间。这也就说明FPGA仿真出来,读比写慢30%是Cortex-A8处理器核的问题。这个不是软件上能解决的了。
根据测试数据表,可以看出kernel下的memcpy快跟uncached写快是有关系的。
实在没有别的办法,只能将用户空间映射的uncached区域和kernel下映射的uncached区域的页表属性都打印出来进行对比。
对于用户空间映射的页表属性,在/driver/char/mem.c的mmap_mem中加在phys_mem_access_prot之后,将vma->vm_page_prot打印出来。值为0x103
对于内核空间映射的页表属性,内核模块使用ioremap映射的uncached区域,在ioremap中的__arm_ioremap_pfn_caller中将type->prot_pte打印出来。值为0x653
这个prot值是linux页表的属性值,这里需要知道的是linux为了保证兼容性,分别建立了linux二级页表和硬件二级页表,各占2KB,一起占用4KB一个页。这里的原理在我的内存管理学习笔记再详细说明。
linux二级页表是供linux系统进行页表管理,而硬件二级页表则是供处理器MMU进行读取。
linux二级页表的位定义在/arch/arm/include/asm/pgtable-2level.h中,如下。
/*
* "Linux" PTE definitions.
*
* We keep two sets of PTEs - the hardware and the linux version.
* This allows greater flexibility in the way we map the Linux bits
* onto the hardware tables, and allows us to have YOUNG and DIRTY
* bits.
*
* The PTE table pointer refers to the hardware entries; the "Linux"
* entries are stored 1024 bytes below.
*/
#define L_PTE_PRESENT (_AT(pteval_t, 1) << 0)
#define L_PTE_YOUNG (_AT(pteval_t, 1) << 1)
#define L_PTE_FILE (_AT(pteval_t, 1) << 2) /* only when !PRESENT */
#define L_PTE_DIRTY (_AT(pteval_t, 1) << 6)
#define L_PTE_RDONLY (_AT(pteval_t, 1) << 7)
#define L_PTE_USER (_AT(pteval_t, 1) << 8)
#define L_PTE_XN (_AT(pteval_t, 1) << 9)
#define L_PTE_SHARED (_AT(pteval_t, 1) << 10) /* shared(v6), coherent(xsc3) */
/*
* These are the memory types, defined to be compatible with
* pre-ARMv6 CPUs cacheable and bufferable bits: XXCB
*/
#define L_PTE_MT_UNCACHED (_AT(pteval_t, 0x00) << 2) /* 0000 */
#define L_PTE_MT_BUFFERABLE (_AT(pteval_t, 0x01) << 2) /* 0001 */
#define L_PTE_MT_WRITETHROUGH (_AT(pteval_t, 0x02) << 2) /* 0010 */
#define L_PTE_MT_WRITEBACK (_AT(pteval_t, 0x03) << 2) /* 0011 */
#define L_PTE_MT_MINICACHE (_AT(pteval_t, 0x06) << 2) /* 0110 (sa1100, xscale) */
#define L_PTE_MT_WRITEALLOC (_AT(pteval_t, 0x07) << 2) /* 0111 */
#define L_PTE_MT_DEV_SHARED (_AT(pteval_t, 0x04) << 2) /* 0100 */
#define L_PTE_MT_DEV_NONSHARED (_AT(pteval_t, 0x0c) << 2) /* 1100 */
#define L_PTE_MT_DEV_WC (_AT(pteval_t, 0x09) << 2) /* 1001 */
#define L_PTE_MT_DEV_CACHED (_AT(pteval_t, 0x0b) << 2) /* 1011 */
#define L_PTE_MT_MASK (_AT(pteval_t, 0x0f) << 2)根据linux页表的位定义,0x653和0x103都是配置为uncached,其他位看字面含义也不会对uncached写入速度有影响。
只能采取测试的方法,将页表属性中配置有差别的置位在mem.c中的mmap_mem函数中进行测试。
我在mem.c中建立sys文件入口prot,可以在应用中动态修改mem驱动中的prot值,一位一位的修改,测试哪一位会对uncached写入速度有影响。
测试中果然发现,在置位L_PTE_MT_DEV_SHARED也就是bit4后,mmap /dev/mem的uncached区域的写入以及拷贝速度瞬间提升,uncached区域写入1MB数据耗时4.8ms,跟kernel下的测试接近!
ioremap以及mmap中计算的prot属性值是填写在linux软件页表中,如果要搞清楚L_PTE_MT_DEV_SHARED位为什么会影响写入速度,我们需要搞清楚L_PTE_MT_DEV_SHARED位对应于硬件页表是哪一位,以及硬件页表中该位是起了什么作用。
公司处理器是armV7架构,使用两级页表。不管上层调用如何进行软件操作,硬件页表的填写是在linux最底层页表配置函数cpu_v7_set_pte_ext中。其中会首先配置linux软件二级页表,然后根据linux二级页表的位定义来配置相应的硬件页表。
该函数是arch/arm/mm/proc-v7-2level.S中,如下
/*
* cpu_v7_set_pte_ext(ptep, pte)
*
* Set a level 2 translation table entry.
*
* - ptep - pointer to level 2 translation table entry
* (hardware version is stored at +2048 bytes)
* - pte - PTE value to store
* - ext - value for extended PTE bits
*/
ENTRY(cpu_v7_set_pte_ext)
#ifdef CONFIG_MMU
str r1, [r0] @ linux version
bic r3, r1, #0x000003f0
bic r3, r3, #PTE_TYPE_MASK
orr r3, r3, r2
orr r3, r3, #PTE_EXT_AP0 | 2
tst r1, #1 << 4
orrne r3, r3, #PTE_EXT_TEX(1)
eor r1, r1, #L_PTE_DIRTY
tst r1, #L_PTE_RDONLY | L_PTE_DIRTY
orrne r3, r3, #PTE_EXT_APX
tst r1, #L_PTE_USER
orrne r3, r3, #PTE_EXT_AP1
#ifdef CONFIG_CPU_USE_DOMAINS
@ allow kernel read/write access to read-only user pages
tstne r3, #PTE_EXT_APX
bicne r3, r3, #PTE_EXT_APX | PTE_EXT_AP0
#endif
tst r1, #L_PTE_XN
orrne r3, r3, #PTE_EXT_XN
tst r1, #L_PTE_YOUNG
tstne r1, #L_PTE_PRESENT
moveq r3, #0
ARM( str r3, [r0, #2048]! )
THUMB( add r0, r0, #2048 )
THUMB( str r3, [r0] )
mcr p15, 0, r0, c7, c10, 1 @ flush_pte
#endif
mov pc, lr
ENDPROC(cpu_v7_set_pte_ext)该汇编函数首先将linux软件页表(r1参数1即为软件页表值)存入低2KB页内,然后根据软件页表值来配置硬件页表值,最后将硬件页表值写入高2KB内。
其中使用的硬件二级页表位定义在/arch/arm/include/asm/pgtable-2level-hwdef.h中,如下。
/*
* + Level 2 descriptor (PTE)
* - common
*/
#define PTE_TYPE_MASK (_AT(pteval_t, 3) << 0)
#define PTE_TYPE_FAULT (_AT(pteval_t, 0) << 0)
#define PTE_TYPE_LARGE (_AT(pteval_t, 1) << 0)
#define PTE_TYPE_SMALL (_AT(pteval_t, 2) << 0)
#define PTE_TYPE_EXT (_AT(pteval_t, 3) << 0) /* v5 */
#define PTE_BUFFERABLE (_AT(pteval_t, 1) << 2)
#define PTE_CACHEABLE (_AT(pteval_t, 1) << 3)
/*
* - extended small page/tiny page
*/
#define PTE_EXT_XN (_AT(pteval_t, 1) << 0) /* v6 */
#define PTE_EXT_AP_MASK (_AT(pteval_t, 3) << 4)
#define PTE_EXT_AP0 (_AT(pteval_t, 1) << 4)
#define PTE_EXT_AP1 (_AT(pteval_t, 2) << 4)
#define PTE_EXT_AP_UNO_SRO (_AT(pteval_t, 0) << 4)
#define PTE_EXT_AP_UNO_SRW (PTE_EXT_AP0)
#define PTE_EXT_AP_URO_SRW (PTE_EXT_AP1)
#define PTE_EXT_AP_URW_SRW (PTE_EXT_AP1|PTE_EXT_AP0)
#define PTE_EXT_TEX(x) (_AT(pteval_t, (x)) << 6) /* v5 */
#define PTE_EXT_APX (_AT(pteval_t, 1) << 9) /* v6 */
#define PTE_EXT_COHERENT (_AT(pteval_t, 1) << 9) /* XScale3 */
#define PTE_EXT_SHARED (_AT(pteval_t, 1) << 10) /* v6 */
#define PTE_EXT_NG (_AT(pteval_t, 1) << 11) /* v6 */cpu_v7_set_pte_ext中根据软件页表的bit4来配置硬件页表的代码如下。
tst r1, #1 << 4
orrne r3, r3, #PTE_EXT_TEX(1)如果软件页表中置位bit4,则硬件页表中置位bit6。也就是说硬件页表中置位bit6,使uncached的写入拷贝速度提升
那么bit6到底是干啥的呢,这涉及到armv7处理器的MMU,需要看armv7架构处理器的datasheet了。
我在arm以及armv7架构的datasheet中的确是找到了一些关于bit6的说明,如下。


ARM处理器核的官方datasheet下载链接如下:http://download.csdn.net/detail/skyflying2012/9530439
ARMV7架构处理器的官方datasheet下载链接如下:http://download.csdn.net/detail/skyflying2012/9530443
bit6是硬件页表的TEX[2:0]的最低位,根据上图的说明,访问区域属性的确是由TEX[2:0]以及cached/bufferable 2位一起来控制。但是我还没有找到具体的说明TEX[2:0]对读写影响的说明,后续搞明白后再来补上。
mem.c中置位L_PTE_MT_DEV_SHARED,并且链接kernel的memcpy.o,应用程序对读写拷贝进行测试,跟kernel下的测试速度基本一致了,相较于以前有了大幅提升。
到这里算是解决了我的后2个疑问了。
kernel下ioremap的uncached区域向kmalloc的cached区域拷贝比用户空间的快,原因有2个。
(1)kernel的memcpy比应用程序的效率更高
(2)kernel下建立的软件页表置位了L_PTE_MT_DEV_SHARED,对应于硬件页表的bit6,测试发现可以大幅提升uncached写入速度,从而是memcpy性能再度提升。
kmalloc的cached区域向ioremap的uncached区域拷贝,比kernel下ioremap的uncached区域向kmalloc的cached区域拷贝要慢很多,也是因为软件页表的了L_PTE_MT_DEV_SHARED位。
解决了我对测试数据的3个疑问,对于公司cortex-A8处理器memcpy的优化也就有了几点方法,如下。
(1)使用kernel的memcpy,将kernel下的memcpy抠出来,单独编译成一个库使用。(代码我后续上传到我的资源中)
(2)在mem.c驱动的mmap_mem函数中,置位L_PTE_MT_DEV_SHARED。不过由于还未搞懂其真正含义,不知其有无其他影响,该方法谨慎使用
(3)对于涉及malloc区域的memcpy,提前访问缓冲区,建立页表。该点对于提高memcpy效率有点效果,但是对于程序整体效率无作用(因为缺页异常是必须的)
最后我对采用该优化方案的memcpy进行了一组对比试验,测试拷贝1MB数据的耗时,统计时间还是采用关中断
读timer计数的方式,数据如下。
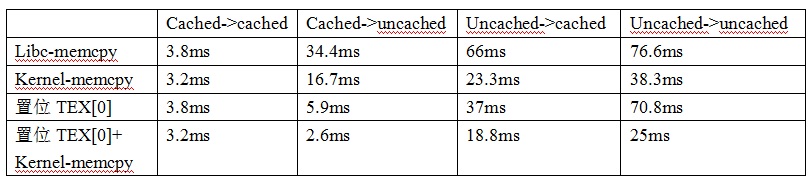
可以看出,对于有uncached区域参与的memcpy,优化后性能提升明显,
uncached->uncached提升3倍,uncached->cached提升3.5倍,cached->uncached提升13.2倍!
cached->uncached提升最多,我的理解是因为置位L_PTE_MT_DEV_SHARED对写入速度提升最为明显导致的。
但是对于cached内部的memcpy,速度提升不明显。看来置位L_PTE_MT_DEV_SHARED对cached区域无影响,而cached区域本身就有cache line的预取,因此memcpy的PLD预取也没有起作用,只有stmia/ldmia的32bytes批量操作相比与str/ldr的4bytes操作有一点性能的提升。
对于公司设备memcpy的优化记录到这里。最后需要说明的也是最重要的一点,
我的以上优化方法,都在armv7架构的cortex-a8处理器下进行的,pld预取以及硬件页表的bit6置位都需要特定处理器的支持。这都是针对Cortex-A8处理器的优化,并且对于有uncached区域参与的拷贝提升明显,cached区域内拷贝效果不是很明显。
我测试过arm9处理器的memcpy,发现arm9的读写拷贝性能都很均衡,不会出现armv7这种写比读快很多的情况,这些都是跟特定处理器的特定配置是有关系的。
因此朋友们照搬我这套优化方案,有可能是没有效果的,我这里更多的是提供给大家这一套优化的思路供选择。
以上是关于Cortex-A8处理器memcpy的优化方案的主要内容,如果未能解决你的问题,请参考以下文章
ARM中Cortex-A8,Cortex-M0,Cortex-M3 他们的区别在哪?