bulong_filter
Posted youbingchen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了bulong_filter相关的知识,希望对你有一定的参考价值。
存在这样一个问题:判断一个函数是否已经在集合中,最常见的是用散列表实现集合,然后遇到一个新元素时,在散列表中查找,如果能找到则意味着存在于集合当中,反之不存在,但是散列表有一个弊端,它耗费的空间太大了—布隆过滤器
布隆过滤器
布隆过滤器是一种空间效率很高的随机数据结构,它可以看成是对位图的扩展。其结构是长度为n(如何设计最优的n)的位数组,初始化为0,当一个元素加入这个集合中,通过k个散列函数将这个元素映射成一个数组中的k个点。并将这k个点全部设置为1。
在检索这个元素是否在一个集合当中,我们只要看看这个元素被映射成位阵列的k个点是不是都是1:如果这k个点中有任何一个点为0,则被检索元素在集合中一定不存在;如果这k个点都是1,则被检索元素很可能在集合中。
布隆过滤器的缺点:它有一定的误判率–判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误判为属于这个集合。因此,它不适用于那些“零误判”的场合
布隆过滤器的算法

如上图所示:
布隆过滤器是一个包含m位的位数组,每一位位置都是0。
对于这样一个n个元素的集合,布隆过滤器使用k个相互独立的散列函数分别将集合
中的每一个元素映射到{1,…,m}的范围中。对于任意一个元素x,第i个散列函数的位置就会被置为1(1<=i<=k)。
如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果
两个典型的使用案例
no1.寻找通过的URL
给定A和B两个文件,各放50亿条URL,每一条URL占用64字节,内存限制是4GB,请找出A和B两个文件的共同的URL。
分析:如果允许有一定的误判率,可以使用布隆过滤器,4GB内存大概可以表示340亿位,然后挨个读取另外一个文件的URL使用布隆过滤器映射到这340亿位,然后挨个读取另外一个文件中的URL,检查这两个URL是否相同,如果是,那么该URL应该是共同的URL。
no2.垃圾邮件过滤
使用布隆过滤器,解决存储的问题,可以利用贝叶斯分类鉴别一份邮件是否为垃圾邮件,减少误判率。
位图
所谓位图,就是一个用位来标记某个元素对应的值,而键就是该元素,由于采用了位为单位来存储数据,因此可以大大节省存储空间。
位图通过使用数组位来表示某些元素是否存在,可进行数据的快速查找、判重、删除
2.5亿个整数的去重
采用2位图(每个数分配2位,00表示不存在,01表示出现一次,10表示出现多次,11无意义),然后扫描这2.5亿个整数,查看位图中相对应的位,如果是00就变为01,如果是01变为10,如果是10就保持不变。扫描之后,查看位图,把对应位是01的整数输出即可。也可以先划分成小文件,然后小文件中找出不重复的整数,并排序,最后归并,归并的同时去除重复的数
整数的快速查询
给定40亿不重复的没排过序的unsigned int型整数,然后再给定一个数,如何快速判断这个数是否在这40亿个整数当中?
可以用位图的方法,申请512MB的内存,一个位代表一个unsigned int型的值。读入40亿个数,设置相应的位,读入查询的数,查看相应位是否为1,如果为1表示存在,如果为0表示不存在。
Trie树
Trie数,即字典树,又称单词查找树或键数,是一种树形结构,常用于统计和排序大量字符串等场景,且经常被搜索引擎用于文本词频统计,他的优点是最大限度地减少无谓的字符串比较,查询效率比较高。
Trie树的核心思想是以空间换时间,利用字符串的公共前缀来降低查询时间的开销,以达到提高效率的目的。
它以下有三个基本性质
+ 根节点不包含字符,除根节点外每一个节点都只包含一个字符
+ 从根节点到某一个节点的路径经过的字符串连接起来,即为该节点对应的字符串
+ 每个结点的所有子节点所包含的字符不同
Trie树的创建
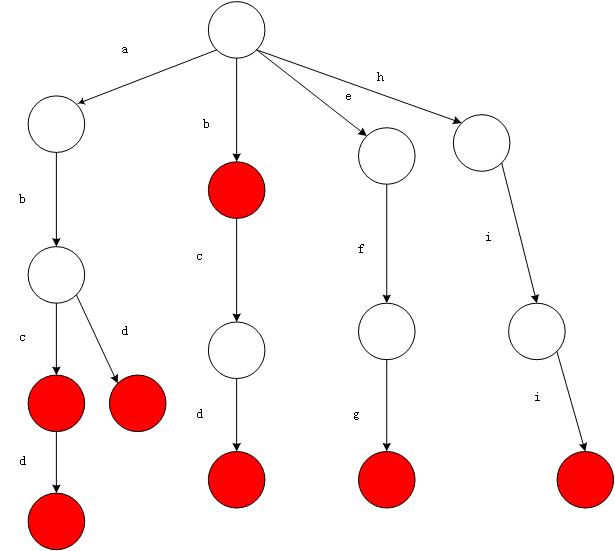
如上图,如果现在有b,abc,abd,bcd,abcd,efg和hii这六个单词,可以构建一个图Trie数
从根节点遍历到每一个节点的路径就是一个单词,如果某个节点被标记成红色,就表示这个单词存在,否则就是不存在。那么对于一个单词,只要顺着它从根节点走到相对应的节点,再看这个结点是否被标记为红色就可以知道它是否出现过,把这个节点标记成红色,相当于插入这个单词,这样一来,查询和插入可以一起完成,所用的时间仅仅就是单词的长度
查询
Trie 树是简单且实用的数据结构,通常用于字典查询,本质上,Trie树是一棵存储多个字符串的树,相邻的节点间则代表完整的字符串。和普通树不同的是,相同的字符串前缀共享同一分支
10个频繁出现的词
在一个文本文件中大约有1万行吗,每行一个词,要求统计出其中出现次数最频繁的10个词
用Trie树统计每个词出现的次数,时间复杂度是O(nl)(l表示单词的平均长度),最终找出最频繁的前10个词(可用堆来实现,时间复杂度为O(nlog10))
寻找热门查询
搜索引擎会通过日志文件将每次用户检索使用的所有查询串都记录下来,每个查询串长度为1~255字节,假设目前只有1000万条记录(因为查询字符串的重复度比较高,虽然有1000万,但是如果去除重复,不超过300万个),请统计最热门的10个查询串,要求内存不能超过1GB(一个字符串的重复度越高,说明查询它的用户就会越多,也就越热门)
利用Trie树,观察关键字在该查询串的出现次数,若没有出现规则为0,最后利用10个元素的最小堆来对出现频率进行排序。
二叉查找树(二叉排序树)
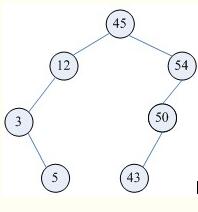
二叉查找树是一种动态查找表(图a),具有这些性质:
(1)若它的左子树不为空,则左子树上的所有节点的值都小于它的根节点的值;
(2)若它的右子树不为空,则右子树上所有节点的值都大于它的根节点的值;
(3)其他的左右子树也分别为二叉查找树;
(4)二叉查找树是动态查找表,在查找的过程中可见添加和删除相应的元素,在这些操作中需要保持二叉查找树的以上性质。
平衡二叉树(AVL树)
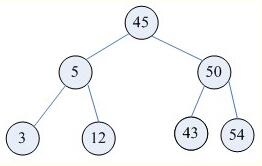
含有相同节点的二叉查找树可以有不同的形态,而二叉查找树的平均查找长度与树的深度有关,所以需要找出一个查找平均长度最小的一棵,那就是平衡二叉树(图b),具有以下性质:
(1)要么是棵空树,要么其根节点左右子树的深度之差的绝对值不超过1;
(2)其左右子树也都是平衡二叉树;
(3)二叉树节点的平衡因子定义为该节点的左子树的深度减去右子树的深度。则平衡二叉树的所有节点的平衡因子只可能是-1,0,1。
红黑树
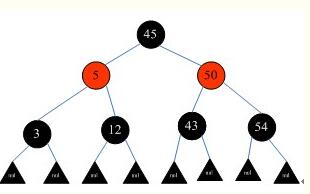
红黑树是一种自平衡二叉树,在平衡二叉树的基础上每个节点又增加了一个颜色的属性,节点的颜色只能是红色或黑色。具有以下性质:
(1)根节点只能是黑色;
(2)红黑树中所有的叶子节点后面再接上左右两个空节点,这样可以保持算法的一致性,而且所有的空节点都是黑色;
(3)其他的节点要么是红色,要么是黑色,红色节点的父节点和左右孩子节点都是黑色,及黑红相间;
(4)在任何一棵子树中,从根节点向下走到空节点的路径上所经过的黑节点的数目相同,从而保证了是一个平衡二叉树。
B-树
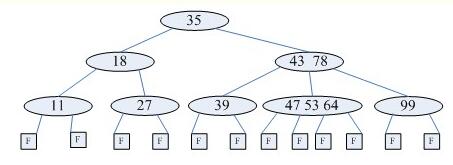
B-树是一种平衡多路查找树,它在文件系统中很有用。一棵m阶B-树(图d为4阶B-树),具有下列性质:
(1)树中每个节点至多有m棵子树;
(2)若根节点不是叶子节点,则至少有2棵子树;
(3)除根节点之外的所有非终端节点至少
⌈m2⌉
有棵子树;
(4)每个节点中的信息结构为(A0,K1,A1,K2……Kn,An),其中n表示关键字个数,Ki为关键字,Ai为指针;
(5)所有的叶子节点都出现在同一层次上,且不带任何信息,也是为了保持算法的一致性。
B+树
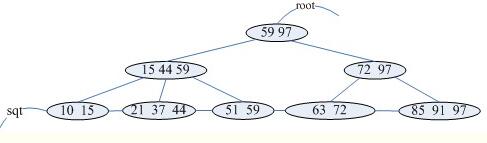
B+数是B-树的一种变形,它与B-树的差别在于(图e为3阶B+树):
(1)有n棵子树的节点含有n个关键字;
(2)所有的叶子节点包含了全部关键字的信息,及指向这些关键字记录的指针,且叶子节点本身按关键字大小自小到大顺序链接;
(3)所有非终端节点可以看成是索引部分,节点中仅含有其子树(根节点)中最大(或最小)关键字,所有B+树更像一个索引顺序表;
(4)对B+树进行查找运算,一是从最小关键字起进行顺序查找,二是从根节点开始,进行随机查找。
应用场景
AVL早期有应用在linux内核上,后来被RBtree代替了,具体是用在哪个模块上,两者都保持log(n)的插入与查询,是平衡的BST,不会出现(n2)的糟糕情况,那为什么linux内核要用RBtree替代AVL呢,从原理上看,个人猜想是AVL需要大量的旋转来保持平衡,而RBtree的旋转调节可能会少些。
而 B B+则运用在file system database这类持续存储结构,同样能保持lon(n)的插入与查询,也需要额外的平衡调节。像mysql的数据库定义是可以指定B+ 索引还是hash索引。
trie树大都用在word的匹配,但单纯的trie内存消耗很大,建trie树也需要些时间,通常用在带词典的机械分词,jieba分词就是建立在trie上匹配的,trie有其他变体可以压缩空间,像double array trie这类比较老且经典的压缩方法,也有其他比较新的压缩方式,看论文时有看过,没自己实现过所以不断言了,其实面对多模匹配trie没有其变体aho-corasick来得理想,另外aho-corasick也是可以用巧妙的方法来进行压缩空间,这里不再展开,毕竟手机码字,同时想基数树与其也类似,在nginx上有应用,说到aho-corasick其实早期的入侵检测工具snort也有应用实现,但如今改成wu-menber了,具体记不清了,其实trie还是挺有用的,Tengine也用trie实现了了匹配模块。但要是用在大量单词的匹配上确实吃力
AVL是一种高度平衡的二叉树,所以通常的结果是,维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树。当然,如果场景中对插入删除不频繁,只是对查找特别有要求,AVL还是优于红黑的。
红黑树的应用就很多了,除了上面同学提到的STL,还有
著名的linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块
epoll在内核中的实现,用红黑树管理事件块
nginx中,用红黑树管理timer等
Java的TreeMap实现
B和B+主要用在文件系统以及数据库中做索引等,比如Mysql:B-Tree Index in MySql
trie 树的一个典型应用是前缀匹配,比如下面这个很常见的场景,在我们输入时,搜索引擎会给予提示
相比其它算法,trie的思想简单、直接,但实际应用的不多,这里结合自己的工作聊下trie。
trie很适合路由时ip地址的最长前缀匹配,特别是mtrie最长前缀匹配性能无敌。但mtrie缺点嘛就是算法比较复杂、需要btrie辅助,同时内存消耗量大。
以上是关于bulong_filter的主要内容,如果未能解决你的问题,请参考以下文章