哈希表——swift字典的实现原理
Posted 3行代码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈希表——swift字典的实现原理相关的知识,希望对你有一定的参考价值。
我们先看看维基百科的介绍
散列表(Hash table,也叫哈希表),是根据关键字(Key value)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
一个通俗的例子是,为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表(即建立人名 到首字母
到首字母 的一个函数关系),在首字母为W的表中查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,“取首字母”是这个例子中散列函数的函数法则
的一个函数关系),在首字母为W的表中查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,“取首字母”是这个例子中散列函数的函数法则 ,存放首字母的表对应散列表。关键字和函数法则理论上可以任意确定。
,存放首字母的表对应散列表。关键字和函数法则理论上可以任意确定。
目录
基本概念
- 若关键字为
 ,则其值存放在
,则其值存放在 的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系
的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系 为散列函数,按这个思想建立的表为散列表。
为散列函数,按这个思想建立的表为散列表。
- 对不同的关键字可能得到同一散列地址,即
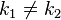 ,而
,而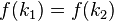 ,这种现象称为冲突(英语:Collision)。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数和处理冲突的方法将一组关键字映射到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便称为散列表,这一映射过程称为散列造表或散列,所得的存储位置称散列地址。
,这种现象称为冲突(英语:Collision)。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数和处理冲突的方法将一组关键字映射到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便称为散列表,这一映射过程称为散列造表或散列,所得的存储位置称散列地址。
- 若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数(Uniform Hash function),这就是使关键字经过散列函数得到一个“随机的地址”,从而减少冲突。
构造散列函数
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快定位。
- 直接定址法:取关键字或关键字的某个线性函数值为散列地址。即
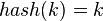 或
或 ,其中
,其中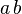 为常数(这种散列函数叫做自身函数)
为常数(这种散列函数叫做自身函数) - 数字分析法:假设关键字是以r为基的数,并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
- 平方取中法:取关键字平方后的中间几位为哈希地址。通常在选定哈希函数时不一定能知道关键字的全部情况,取其中的哪几位也不一定合适,而一个数平方后的中间几位数和数的每一位都相关,由此使随机分布的关键字得到的哈希地址也是随机的。取的位数由表长决定。
- 折叠法:将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。
- 随机数法
- 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即
 ,
,
 。不仅可以对关键字直接取模,也可在折叠法、平方取中法等运算之后取模。对p的选择很重要,一般取素数或m,若p选择不好,容易产生冲突。
。不仅可以对关键字直接取模,也可在折叠法、平方取中法等运算之后取模。对p的选择很重要,一般取素数或m,若p选择不好,容易产生冲突。
处理冲突
为了知道冲突产生的相同散列函数地址所对应的关键字,必须选用另外的散列函数,或者对冲突结果进行处理。而不发生冲突的可能性是非常之小的,所以通常对冲突进行处理。常用方法有以下几种:
- 开放定址法(open addressing):
 ,
,
 ,其中
,其中 为散列函数,
为散列函数, 为散列表长,
为散列表长,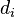 为增量序列,
为增量序列, 为已发生冲突的次数。增量序列可有下列取法:
为已发生冲突的次数。增量序列可有下列取法:
 称为
线性探测(Linear Probing);即
称为
线性探测(Linear Probing);即 ,或者为其他线性函数。相当于逐个探测存放地址的表,直到查找到一个空单元,把散列地址存放在该空单元。
,或者为其他线性函数。相当于逐个探测存放地址的表,直到查找到一个空单元,把散列地址存放在该空单元。
 称为
平方探测(Quadratic Probing)。相对线性探测,相当于发生冲突时探测间隔
称为
平方探测(Quadratic Probing)。相对线性探测,相当于发生冲突时探测间隔 个单元的位置是否为空,如果为空,将地址存放进去。
个单元的位置是否为空,如果为空,将地址存放进去。 伪随机数序列,称为
伪随机探测。
伪随机数序列,称为
伪随机探测。
显示线性探测填装一个散列表的过程:
- 关键字为{89,18,49,58,69}插入到一个散列表中的情况。此时线性探测的方法是取。并假定取关键字除以10的余数为散列函数法则。
| 散列地址 | 空表 | 插入89 | 插入18 | 插入49 | 插入58 | 插入69 |
|---|---|---|---|---|---|---|
| 0 | 49 | 49 | 49 | |||
| 1 | 58 | 58 | ||||
| 2 | 69 | |||||
| 3 | ||||||
| 4 | ||||||
| 5 | ||||||
| 6 | ||||||
| 7 | ||||||
| 8 | 18 | 18 | 18 | 18 | ||
| 9 | 89 | 89 | 89 | 89 | 89 |
- 第一次冲突发生在填装49的时候。地址为9的单元已经填装了89这个关键字,所以取
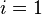 ,往下查找一个单位,发现为空,所以将49填装在地址为0的空单元。第二次冲突则发生在58上,取
,往下查找一个单位,发现为空,所以将49填装在地址为0的空单元。第二次冲突则发生在58上,取 ,往下查找两个单位,将58填装在地址为1的空单元。69同理。
,往下查找两个单位,将58填装在地址为1的空单元。69同理。
- 表的大小选取至关重要,此处选取10作为大小,发生冲突的几率就比选择质数11作为大小的可能性大。越是质数,mod取余就越可能均匀分布在表的各处。
聚集(Cluster,也翻译做“堆积”)的意思是,在函数地址的表中,散列函数的结果不均匀地占据表的单元,形成区块,造成线性探测产生一次聚集(primary clustering)和平方探测的二次聚集(secondary clustering),散列到区块中的任何关键字需要查找多次试选单元才能插入表中,解决冲突,造成时间浪费。对于开放定址法,聚集会造成性能的灾难性损失,是必须避免的。
- 双散列。
 ,
,
 。
。 是一些散列函数。即在上次散列计算发生冲突时,利用该次冲突的散列函数地址产生新的散列函数地址,直到冲突不再发生。这种方法不易产生“
是一些散列函数。即在上次散列计算发生冲突时,利用该次冲突的散列函数地址产生新的散列函数地址,直到冲突不再发生。这种方法不易产生“- 建立一个公共溢出区
例程
- 开放定址法:
HashTable
InitializeTable( int TableSize )
{
HashTable H;
int i;
/* 为散列表分配空间。 */
/* 有些编译器不支持为 struct HashTable 分配空间,声称这是一个不完全的结构, */
/* 可使用一个指向 HashTable 的指针为之分配空间。 */
/* 如:sizeof( Probe ),Probe 作为 HashTable 在 typedef 定义的指针。 */
H = malloc( sizeof( struct HashTable ) );
/* 散列表大小为一个质数。 */
H->TableSize = Prime;
/* 分配表所有地址的空间。 */
H->Cells = malloc( sizeof( Cell ) * H->TableSize );
/* 地址初始为空。 */
for( i = 0; i < H->TableSize; i++ )
H->Cells[i].info = Empty;
return H;
}
查找空单元并插入:
Position
Find( ElementType Key, HashTable H )
{
Position Current;
int CollisionNum;
/* 冲突次数初始为0。 */
/* 通过表的大小对关键字进行处理。 */
CollisionNum = 0;
Current = Hash( Key, H->TableSize );
/* 不为空时进行查找。 */
while( H->Cells[Current].info != Empty &&
H->Cells[Current].Element != Key )
{
Current = ++CollosionNum * ++CollisionNum;
/* 向下查找超过表范围时回到表开头。 */
if( Current >= H->TableSize )
Current -= H->TableSize;
}
return Current;
}
- 分离链接法
查找效率
散列表的查找过程基本上和造表过程相同。一些关键码可通过散列函数转换的地址直接找到,另一些关键码在散列函数得到的地址上产生了冲突,需要按处理冲突的方法进行查找。在介绍的三种处理冲突的方法中,产生冲突后的查找仍然是给定值与关键码进行比较的过程。所以,对散列表查找效率的量度,依然用平均查找长度来衡量。
查找过程中,关键码的比较次数,取决于产生冲突的多少,产生的冲突少,查找效率就高,产生的冲突多,查找效率就低。因此,影响产生冲突多少的因素,也就是影响查找效率的因素。影响产生冲突多少有以下三个因素:
- 散列函数是否均匀;
- 处理冲突的方法;
- 散列表的载荷因子(英语:load factor)。
载荷因子
散列表的载荷因子定义为: = 填入表中的元素个数 / 散列表的长度
= 填入表中的元素个数 / 散列表的长度
是散列表装满程度的标志因子。由于表长是定值,与“填入表中的元素个数”成正比,所以,越大,表明填入表中的元素越多,产生冲突的可能性就越大;反之,越小,标明填入表中的元素越少,产生冲突的可能性就越小。实际上,散列表的平均查找长度是载荷因子的函数,只是不同处理冲突的方法有不同的函数。
对于开放定址法,荷载因子是特别重要因素,应严格限制在0.7-0.8以下。超过0.8,查表时的CPU缓存不命中(cache missing)按照指数曲线上升。因此,一些采用开放定址法的hash库,如Java的系统库限制了荷载因子为0.75,超过此值将resize散列表。
举例:Linux内核的bcache
Linux操作系统在物理文件系统与块设备驱动程序之间引入了“缓冲区缓存”(Buffer Cache,简称bcache)。当读写磁盘文件的数据,实际上都是对bcache操作,这大大提高了读写数据的速度。如果要读写的磁盘数据不在bcache中,即缓存不命中(miss),则把相应数据从磁盘加载到bcache中。一个缓存数据大小是与文件系统上一个逻辑块的大小相对应的(例如1KiB字节),在bcache中每个缓存数据块用struct buffer_head记载其元信息:
struct buffer_head {
char * b_data; //指向缓存的数据块的指针
unsigned long b_blocknr; //逻辑块号
unsigned short b_dev; //设备号
unsigned char b_uptodate; //缓存中的数据是否是最新的
unsigned char b_dirt; //缓存中数据是否为脏数据
unsigned char b_count; //这个缓存块被引用的次数
unsigned char b_lock; //b_lock表示这个缓存块是否被加锁
struct task_struct * b_wait; //等待在这个缓存块上的进程
struct buffer_head * b_prev; //指向缓存中相同hash值的下一个缓存块
struct buffer_head * b_next; //指向缓存中相同hash值的上一个缓存块
struct buffer_head * b_prev_free; //缓存块空闲链表中指向下一个缓存块
struct buffer_head * b_next_free; //缓存块空闲链表中指向上一个缓存块
};
整个bcache以struct buffer_head为基本数据单元,组织为一个封闭定址(close addressing,即“单独链表法”解决冲突)的散列表struct buffer_head * hash_table[NR_HASH]; 散列函数的输入关键字是b_blocknr(逻辑块号)与b_dev(设备号)。计算hash值的散列函数表达式为:
- (b_dev ^ b_blocknr) % NR_HASH
其中NR_HASH是散列表的条目总数。发生“ 冲突”的struct buffer_head,以b_prev与b_next指针组成一个双向(不循环)链表。bcache中所有的struct buffer_head,包括使用中不空闲与未使用空闲的struct buffer_head,以b_prev_free和b_next_free指针组成一个双向循环链表free_list,其中未使用空闲的struct buffer_head放在该链表的前部。
那么swift里面
Swift中字典具有以下特点:
- 字典由两种范型类型组成,分别是Key(必须实现
Hashable协议)和Value - 提供一组Key和Value,可以向字典中插入一条新的数据
- 如果Key已经被插入字典,则可以通过Key获取到Value
- 可以通过Key删除一条字典中的数据
- 每个Key对应,且唯一对应字典中的一个Value
有很多种方式可以用于存储这些Key-Value对,Swift中字典采用了使用线性探测的开放寻址法。
我们知道,哈希表不可避免会出现的问题是哈希值冲突,也就是两个不同的Key可能具有相同的哈希值。线性探测是指,如果出现第二个Key的哈希值和第一个Key的哈希值冲突,则会检查第一个Key对应位置的后一个位置是否可用,如果可用则把第二个Key对应的Value放在这里,否则就继续向后寻找。
一个容量为8的字典,它实际上只能存储7个Key-Value对,这是因为字典需要至少一个空位置作为插入和查找过程中的停止标记。我们把这个位置称为“洞”。
举个例子,假设Key1和Key2具有相同的哈希值,它们都存储在字典中。现在我们查找Key3对应的值。Key3的哈希值和前两者相同,但它不存在于字典中。查找时,首先从Key1所在的位置开始比较,因为不匹配所以比较Key2所在的位置,而且从理论上来说只用比较这两个位置即可。如果Key2的后面是一个洞,就表示查找到此为止,否则还得继续向后查找。
在实际内存中,它的布局看上去是这样的:

创建字典时会分配一段连续的内存,其大小很容易计算:
size = capacity * (sizeof(Bitmap) + sizeof(Keys) + sizeof(Values))
从逻辑上来看,字典的组成结构如下:

其中每一列称为一个bucket,其中存储了三样东西:位图的值,Key和Value。bucket的概念其实已经有些类似于我们实际使用字典时,Key-Value对的概念了。
bucket中位图的值用于表示这个bucket中的Key和Value是否是已初始化且有效的。如果不是,那么这个bucket就是一个洞。
介绍完以上基本概念后,我们由底层向高层介绍字典的实现原理:
_HashedContainerStorageHeader(结构体)

这个结构体是字典所使用内存的头部,它有三个成员变量:
- capacity:字典的容量,表示字典当前最多可以存储多少Key-Value对
- count:字典中元素数量,表示字典当前实际存储的Key-Value对的数量
- maxLoadFactorInverse:当字典需要扩容时使用到的因子,新的capacity是旧的capacity乘以这个因子。
_NativeDictionaryStorageImpl<Key, Value>(类)
这个类是ManagedBuffer<_HashedContainerStorageHeader, UInt8>的子类。
这个类的作用是为字典分配需要使用的内存,并且返回指向位图、Key和Value数组的指针。比如:
internal var _values: UnsafeMutablePointer<Value> {
@warn_unused_result
get {
let start = UInt(Builtin.ptrtoint_Word(_keys._rawValue)) &+
UInt(_capacity) &* UInt(strideof(Key.self))
let alignment = UInt(alignof(Value))
let alignMask = alignment &- UInt(1)
return UnsafeMutablePointer<Value>(
bitPattern:(start &+ alignMask) & ~alignMask)
}
}由于位图、Key和Value数组所在的内存是连续分配的,所以Value数组的指针values_pointer等于keys_pointer + capacity * keys_pointer。
分配字典所用内存的函数和下面的知识关系不大,所以这里略去不写,有兴趣的读者可以在原文中查看。
在分配内存的过程中,位图数组中所有的元素值都是0,这就表示所有的bucket都是洞。另外需要强调的一点是,到目前为止(分配字典所用内存)范型Key不必实现Hashable协议。
目前,字典的结构组成示意图如下:

_NativeDictionaryStorage<Key : Hashable, Value>(结构体)
这个结构体将_NativeDictionaryStorageImpl结构体封装为自己的buffer属性,它还提供了一些方法将实际上有三个连续数组组成的字典内存转换成逻辑上的bucket数组。而且,这个结构体将bucket数组中的第一个bucket和最后一个bucket在逻辑上链接起来,从而形成了一个bucket环,也就是说当你到达bucket数组的末尾并且调用next方法时,你又会回到bucket数组的开头。
在进行插入或查找操作时,我们需要算出这个Key对应哪个bucket。由于Key实现了Hashable,所以它一定实现了hashValue方法并返回一个整数值。但这个哈希值可能比字典容量还大,所以我们需要压缩这个哈希值,以确保它属于区间[0, capacity):
@warn_unused_result
internal func _bucket(k: Key) -> Int {
return _squeezeHashValue(k.hashValue, 0..<capacity)
}通过_next和_prev函数,我们可以遍历整个bucket数组,这里虽然使用了溢出运算符,但实际上并不会发生溢出,个人猜测是为了性能优化:
internal var _bucketMask: Int {
return capacity &- 1
}
@warn_unused_result
internal func _next(bucket: Int) -> Int {
return (bucket &+ 1) & _bucketMask
}
@warn_unused_result
internal func _prev(bucket: Int) -> Int {
return (bucket &- 1) & _bucketMask
}字典容量capacity一定可以表示为2的多少次方,因此_bucketMask这个属性如果用二进制表示,则一定全部由1组成。举个例子体验一下,假设capacity = 8:
- bucket = 6,调用_next方法,返回值为 7 & 7,也就是7.
- bucket = 7,调用_next方法,返回值为 8 & 7,二进制表示为1000 & 0111,因此返回值为0。也就是返回了数组的起始位置。
- bucket = 0,调用_prev方法,返回值为 -1 & 7,二进制表示为1…1111 & 0…0111,因此返回值为111,也就是7,回到了数组的结束位置。
在插入一个键值对时,我们首先计算出Key对应哪个bucket,然后调用下面的方法把Key和Value写入到bucket中,同时把位图的值设置为true:
@_transparent
internal func initializeKey(k: Key, value v: Value, at i: Int) {
_sanityCheck(!isInitializedEntry(i))
(keys + i).initialize(k)
(values + i).initialize(v)
initializedEntries[i] = true
_fixLifetime(self)
}另一个需要重点介绍的函数是_find:
_find函数用于找到Key对应的bucket- 需要指定需要指定从哪个bucket开始寻找,因此需要
_buckey(key)函数的配合 - 如果参数key和某个bucket中的Key匹配,则返回这个bucket的位置
- 如果没有找到,则返回接下来的第一个洞,表示key可以插入到这里
- 通过位图判断当前bucket是不是一个洞
- 这种算法被称为线性探测
@warn_unused_result
internal
func _find(key: Key, _ startBucket: Int) -> (pos: Index, found: Bool) {
var bucket = startBucket
while true {
let isHole = !isInitializedEntry(bucket)
if isHole {
return (Index(nativeStorage: self, offset: bucket), false)
}
if keyAt(bucket) == key {
return (Index(nativeStorage: self, offset: bucket), true)
}
bucket = _next(bucket)
}
}- 一般来说,
_squeezeHashValue函数的返回值就是Key对应的bucket的下标,不过需要考虑不同的Key哈希值冲突的情况。 - 在这种情况下,
_find函数会找到下一个可用的洞,以便插入数据。
hashValue优化
_squeezeHashValue函数的本质是对Key的哈希值再次求得哈希值,而一个优秀的哈希函数是提高性能的关键。_squeezeHashValue函数基本上符合要求,不过目前惟一的缺点是哈希变换的种子还是一个占位常量,有兴趣的读者可以阅读完整的函数实现,其中的seed就是一个值为0xff51afd7ed558ccd的常量:
func _squeezeHashValue(hashValue: Int, _ resultRange: Range<UInt>) -> UInt {
let mixedHashValue = UInt(bitPattern: _mixInt(hashValue))
let resultCardinality: UInt = resultRange.endIndex - resultRange.startIndex
if _isPowerOf2(resultCardinality) {
return mixedHashValue & (resultCardinality - 1)
}
return resultRange.startIndex + (mixedHashValue % resultCardinality)
}
func _mixUInt64(value: UInt64) -> UInt64 {
// Similar to hash_4to8_bytes but using a seed instead of length.
let seed: UInt64 = _HashingDetail.getExecutionSeed()
let low: UInt64 = value & 0xffff_ffff
let high: UInt64 = value >> 32
return _HashingDetail.hash16Bytes(seed &+ (low << 3), high)
}
static func getExecutionSeed() -> UInt64 {
// FIXME: This needs to be a per-execution seed. This is just a placeholder
// implementation.
let seed: UInt64 = 0xff51afd7ed558ccd
return _HashingDetail.fixedSeedOverride == 0 ? seed : fixedSeedOverride
}
static func hash16Bytes(low: UInt64, _ high: UInt64) -> UInt64 {
// Murmur-inspired hashing.
let mul: UInt64 = 0x9ddfea08eb382d69
var a: UInt64 = (low ^ high) &* mul
a ^= (a >> 47)
var b: UInt64 = (high ^ a) &* mul
b ^= (b >> 47)
b = b &* mul
return b
}目前,字典的结构总结如下:

_NativeDictionaryStorageOwner(类)
这个类被用于管理字典的引用计数,以支持写时复制(COW)特性。由于Dictionary和DictionaryIndex都会引用实际存储区域,所以引用计数为2。不过写时复制的唯一性检查不考虑由DictionaryIndex导致的引用,所以如果字典通过引用这个类的实例对象来管理引用计数值,问题就很容易处理。
/// This class is an artifact of the COW implementation. This class only
/// exists to keep separate retain counts separate for:
/// - `Dictionary` and `NSDictionary`,
/// - `DictionaryIndex`.
///
/// This is important because the uniqueness check for COW only cares about
/// retain counts of the first kind.
/// 这个类用于区分以下两种引用:
/// - `Dictionary` and `NSDictionary`,
/// - `DictionaryIndex`.
/// 这是因为写时复制的唯一性检查只考虑第一种引用现在,字典的结构变得有些复杂,难以理解了:

_VariantDictionaryStorage<Key : Hashable, Value> (枚举)
这个枚举类型中有两个成员,它们各自具有自己的关联值,分别表示Swift原生的字典和Cocoa的字典:
case Native(_NativeDictionaryStorageOwner<Key, Value>)
case Cocoa(_CocoaDictionaryStorage)这个枚举类型的主要功能是:
- 根据字典的不同类型(原生 or Cocoa)执行对应的增删改查函数
- 如果字典已经满了,则扩容
-
更新或初始化Key-Value对:
internal mutating func nativeUpdateValue( value: Value, forKey key: Key ) -> Value? { var (i, found) = native._find(key, native._bucket(key)) let minCapacity = found ? native.capacity : NativeStorage.getMinCapacity( native.count + 1, native.maxLoadFactorInverse) let (_, capacityChanged) = ensureUniqueNativeStorage(minCapacity) if capacityChanged { i = native._find(key, native._bucket(key)).pos } let oldValue: Value? = found ? native.valueAt(i.offset) : nil if found { native.setKey(key, value: value, at: i.offset) } else { native.initializeKey(key, value: value, at: i.offset) native.count += 1 } return oldValue } -
如果移除某个Key-Value对,就会在原地留下一个洞。下一次线性查找时有可能会提前停止,为了解决这个问题,我们需要在移除Key-Value对后,移动另一个Key-Value对补上这个洞,源码如下:
/// - parameter idealBucket: The ideal bucket for the element being deleted. /// - parameter offset: The offset of the element that will be deleted. /// Requires an initialized entry at offset. internal mutating func nativeDeleteImpl( nativeStorage: NativeStorage, idealBucket: Int, offset: Int ) { _sanityCheck( nativeStorage.isInitializedEntry(offset), "expected initialized entry") // remove the element nativeStorage.destroyEntryAt(offset) nativeStorage.count -= 1 // If we‘ve put a hole in a chain of contiguous elements, some // element after the hole may belong where the new hole is. var hole = offset // Find the first bucket in the contiguous chain var start = idealBucket while nativeStorage.isInitializedEntry(nativeStorage._prev(start)) { start = nativeStorage._prev(start) } // Find the last bucket in the contiguous chain var lastInChain = hole var b = nativeStorage._next(lastInChain) while nativeStorage.isInitializedEntry(b) { lastInChain = b b = nativeStorage._next(b) } // Relocate out-of-place elements in the chain, repeating until // none are found. while hole != lastInChain { // Walk backwards from the end of the chain looking for // something out-of-place. var b = lastInChain while b != hole { let idealBucket = nativeStorage._bucket(nativeStorage.keyAt(b)) // Does this element belong between start and hole? We need // two separate tests depending on whether [start,hole] wraps // around the end of the buffer let c0 = idealBucket >= start let c1 = idealBucket <= hole if start <= hole ? (c0 && c1) : (c0 || c1) { break // Found it } b = nativeStorage._prev(b) } if b == hole { // No out-of-place elements found; we‘re done adjusting break } // Move the found element into the hole nativeStorage.moveInitializeFrom(nativeStorage, at: b, toEntryAt: hole) hole = b } }
这段代码理解起来可能比较费力,我想举一个例子来说明就比较简单了,假设一开始有8个bucket,bucket中的value就是bucket的下标,最后一个bucket是洞:
Bucket数组中元素下标: {0, 1, 2, 3, 4, 5, 6, 7(Hole)}
bucket中存储的Value: {0, 1, 2, 3, 4, 5, 6, null}接下来我们删除第五个bucket,这会在原地留下一个洞:
Bucket数组中元素下标: {0, 1, 2, 3, 4(Hole), 5, 6, 7(Hole)}
bucket中存储的Value: {0, 1, 2, 3, , 5, 6 }为了补上这个洞,我们把最后一个bucket中的内容移到这个洞里,现在第五个bucket就不是洞了:
Bucket数组中元素下标: {0, 1, 2, 3, 4, 5, 6(Hole), 7(Hole)}
bucket中存储的Value: {0, 1, 2, 3, 6, 5, , }
字典的完整结构
Dictionary结构体持有一个_VariantDictionaryStorage类型的枚举,作为自己的成员属性,所以整个字典完整的组成结构如下图所示:

以上是关于哈希表——swift字典的实现原理的主要内容,如果未能解决你的问题,请参考以下文章