正则表达式快速入门
Posted Dokio
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式快速入门相关的知识,希望对你有一定的参考价值。
在说正则表达式前先看一道题:
问题描述:
在给定字符串中找出单词
( “单词”由大写字母和小写字母字符构成,其他非字母字符视为单词的间隔,
如空格、问号、数字等等;另外单个字母不算单词);找到单词后,按照长度进行降序排序,
(排序时如果长度相同,则按出现的顺序进行排列),然后输出到一个新的字符串中;
如果某个单词重复出现多次,则只输出一次;如果整个输入的字符串中没有找到单词,
请输出空串。输出的单词之间使用一个“空格”隔开。
示例:
输入:”some local buses, some1234123drivers” ,
输出:”drivers local buses some”
输入:”%A^123 t 3453i*()”
输出:charoutput[]=”“
这是一道有关字符串操作的题目,看到题目中的“按照长度进行降序排序" " 重复出现多次,则只输出一次"这样的关键字,我的第一反应是可以用python中的集合去重以及sort()函数来实现。
开始的思路是可以用字符串操作函数吧给定的单词提取出来,放在集合里,用集合的set()函数进行去重然后用sort()函数来进行排序,最后输出。
由于作者是初学python,对python的这些语法函数也只是有一个印象,知道有这些东西,因此还有很多东西要学习,比如:
1.怎样让sort()函数按我们想要的方式来排序(按照长度,降序排序)当然你如果有兴趣可以看我发表的第一篇关于sort()函数的博客。
2怎样把单词提取出来,我的思路是第一个与最后一个单独提取,中间的用于查找空格或逗号等其他字符find()函数……总之非常麻烦。
因此,可以尝试用正则表达式来解决这题
正则表达式(regular expression简称RE):
RE是由一些字符和特殊字符组成的字符串,它们描述了这些字符和字符的某种重复方式。
它的作用是匹配,搜索-替代文本中的某些模式。
正则表达式可以用于“ 过滤”在文本中提取你想要的信息,也可以用于修改,使文本格式符合你的要求。
例如:
最普通平凡的正则表达式就是一个字符串如“goodmorning”它用于匹配 字符串“goodmorning”,“abc123”用于匹配”abc123”
而复杂的正则表达式在于用字符和特殊字符组成的字符串来配对你要的字符串,由具体变为抽象,如“\\w+@\\w+.com”可以用来匹配所有的xxx@yyy.com格式的邮箱。
因此首先介绍这些特殊的符号的含义:
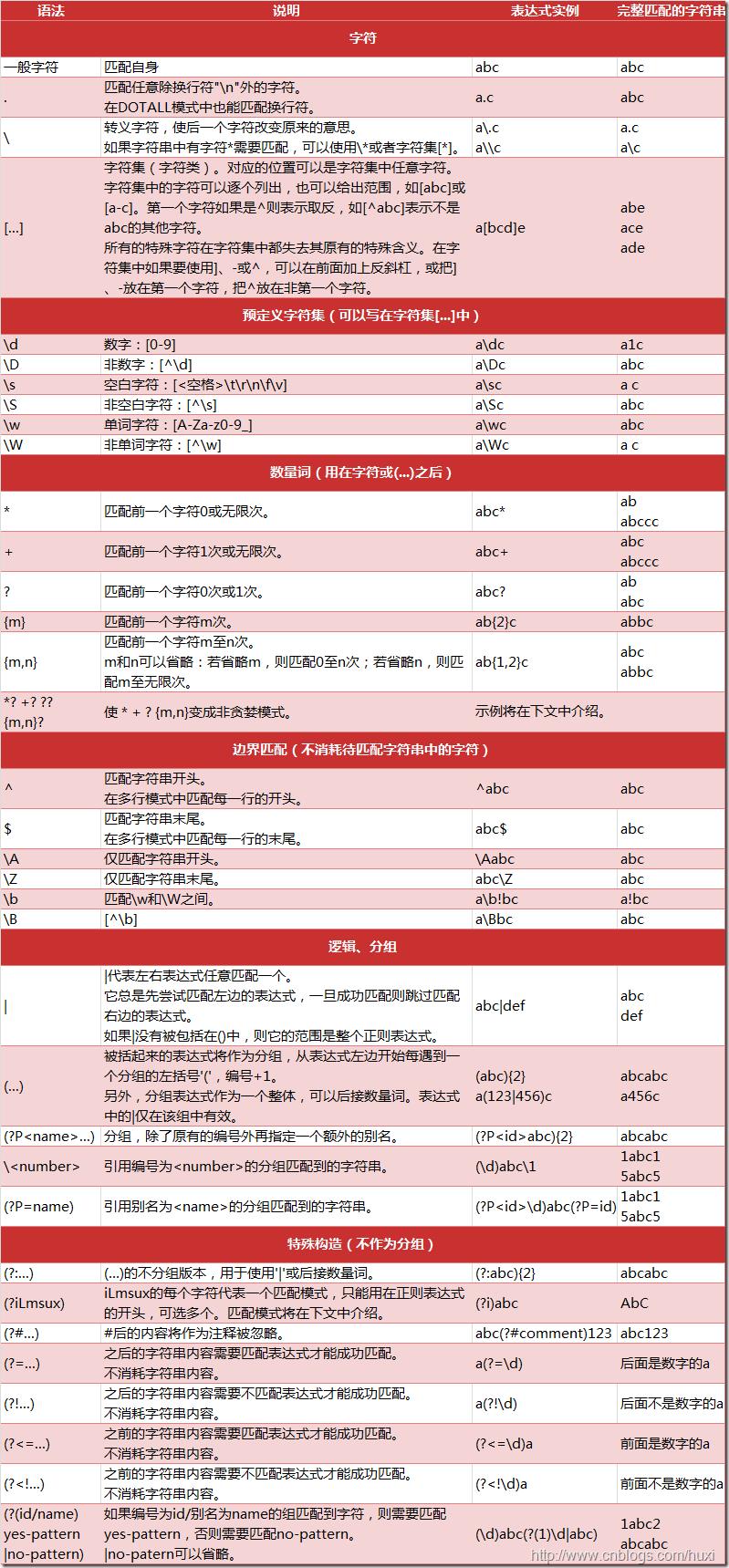
下面结合RE中的函数具体讲解其中的重要部分,先介绍两个重要函数:
1.re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string)
函数参数说明:
参数 描述
pattern 匹配的正则表达式
string 要匹配的字符串。
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
如:
import re
m=re.match("foo","food")
print(m)
print(m.group())结果为
<_sre.SRE_Match object; span=(0, 3), match='foo'>
foo其中,第一行是提示信息,表示在“food”中找到了“foo”
第二行是group()函数找到的相匹配的字符串
下面是一个反例:
import re
m=re.match("foo","foggh")
print(m)
print(m.group())结果为:
None
File “C:/Users/DELL/PycharmProjects/untitled1/python.py”, line 60, in
print(m.group())
AttributeError: ‘NoneType’ object has no attribute ‘group’`
在“foggh”中没有找到“foo”,因此match()函数返回了None,而group函数引发了一个AttributeError。
2.re.search函数
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string)
函数参数说明:
参数 描述
pattern 匹配的正则表达式
string 要匹配的字符串。
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
例如:
import re
m=re.search("foo","dddfood")
print(m)
print(m.group())结果为:
<_sre.SRE_Match object; span=(3, 6), match='foo'>
foo
反例是:
import re
m=re.search("foo","fdfoggh")
print(m)
print(m.group())
结果是
Traceback (most recent call last):
File "C:/Users/DELL/PycharmProjects/untitled1/python.py", line 60, in <module>
print(m.group())
None
AttributeError: 'NoneType' object has no attribute 'group're.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
接下来介绍重要的字符:
1. “.”
“.”可以代替任何的单个的字符(换行符\\n除外),正则表达式写为“.s”
例:
import re
RE=".end"
m=re.match(RE,"bend")
if m is not None:
print(m.group())结果是
bend
2.”|”
正则表达式写为“ s1|s2|s3” ,表示字符串s在s1或者s2或者s3中匹配
例:
import re
RE="bat|bet|bit"
m=re.match(RE,"bit")
if m is not None:
print(m.group())结果为
bit
3.”[ ] “
使用方括号的正则表达式会匹配方括号中的任意一个字符
import re
RE="[cr][23][dp][o2]"
m=re.match(RE,"c3po")
if m is not None:
print(m.group())结果为:
c3po
此外,你还可以写[A-Z],表示为匹配字母A到字母Z中的任意一个字符,同理还有[a-z],[0-9]甚至是[A-Za-z0-9]
还有更简单的方式,例如,[A-Za-z0-9]可以用“\\w”代替,它代表的是字符数字的字符集,[0-9]可以用“\\d”表示。更多的特殊字符可以参照上面表格给出的信息。
表示重复次数的特殊符号:
正则表达式中还有可以表示重复次数的特殊符号,为了介绍它,我们先看一个例子
import re
RE="\\w+@\\w+\\.com"
m=re.match(RE,"110471959@qq.com")
if m is not None:
print(m.group())它的结果是
110471959@qq.com 这段代码中的正则表达式“\\w+@\\w+.com”是可以用来匹配所有的xxx@yyy.com格式的邮箱。
我们谈到过\w是字符数字的字符集,“+”的含义是表示左边的“\w”可以重复一次或者多次,因此它可以匹配一长串数子1104471959,也可以匹配一长串字符(也就是字符串),而“.”前面的”\\“是一个转义字符,我们知道”.“可以代表一个字符,那如果我们只是想匹配”.“本身怎么办呢?只需在”.“前面加上转义字符”\\“就可以了
相似的有
”*“表示重复它左边的字符零次或多次,
”?“表示重复它左边的字符零次或一次。
一定要注意的是它们只代表他们左边那一个字符的重复次数,如果你像要表示重复多个字符的话,只需加上()即可
正则表达式中括号的用法:
实际上,()不仅可以让你在重复多个字符中使用,还有更多的用法
我们先看一段代码:
import re
RE="(\\w{3})-(\\d{3})"
m=re.match(RE,"abc-123456")
if m is not None:
print(m.group())
print(m.group(0))
print(m.group(1))
print(m.group(2))
print(m.groups())其结果是:
abc-123
abc-123
abc
123
('abc', '123'){3}的含义是重复左边的"\w"三次,我们用了括号将正则表达式分组,这样当我们在使用group()函数时加上参数就可以把这些提取出来的,它的用法你一看便知
我们最后再介绍一个重要函数
1.sub()函数
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, max=0)
返回的字符串是在字符串中用 RE 最左边不重复的匹配来替换。如果模式没有发现,字符将被没有改变地返回。
可选参数 count 是模式匹配后替换的最大次数;count 必须是非负整数。缺省值是 0 表示替换所有的匹配。
我们用sub()函数将字符串的格式或者内容变为我们想要的,通常我们只需用到sub()中的三个参数,sub(s1,s2,s),你可以记为,将s中的s1用s2替换,当然,s1是一个正则表达式。
例如:
import re
RE1="\\d"
s="h1e2l3l4o5 w6o7r8l9d"
print(re.sub(RE1," ",s))结果是
h e l l o w o r l d如你所见,这段代码的作用是将字符串”h1e2l3l4o5 w6o7r8l9d”中的数字用空格来替换。
还有一个叫subn()的函数,与sub()不同的是它返回的是一个元组,元组里面的元素是替换后的字符串与改变的次数
例如;
import re
RE1="\\d"
s="h1e2l3l4o5 w6o7r8l9d"
print(re.subn(RE1," ",s))结果是:
('h e l l o w o r l d', 9)
2.split()函数
举一个例子,你一看便知:
import re
RE=":"
print(re.split(RE,"a:b:c:d"))结果是
['a', 'b', 'c', 'd']
同字符串中的split()函数类似,它可以分割字符串,最后返回一个列表。
最后的最后,我们来用正则表达式来解决开始那道题
直接上代码:
import re
s=input("input the string:")
RE1="[^A-Za-z\\s]"
s1=re.sub(RE1," ",s) #将字符串s中所有除字母与空格的字符替换为空格
RE2="\\s+"
s2=re.sub(RE2," ",s1) #将多个连在一起的空格替换为一个空格
RE3=" "
s3=re.split(RE3,s2) #按照空格进行分割,得到又单词组成的列表
s4=set(s3) #用set()函数去重
s5=list(s4) #把集合类型转换为列表类型
s5.sort(key=len,reverse=True)
s6=""
for i in s5: #最后把列表变为字符串
s6=s6+i+" "
print(s6)结果:
input the string:some local buses,some1234123drivers
drivers local buses some 以上是关于正则表达式快速入门的主要内容,如果未能解决你的问题,请参考以下文章