python学习之路-1 python基础操作
Posted 奋斗中的码农
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python学习之路-1 python基础操作相关的知识,希望对你有一定的参考价值。
本篇所涉及的内容
变量
常量
字符编码
用户交互input
格式化字符串
python的缩进规则
注释
初始模块
条件判断
循环
变量
变量的概念基本上和初中代数的方程变量是一致的,只是在计算机程序中,变量不仅可以是数字,还可以是任意数据类型。
变量在程序中就是用一个变量名表示了,变量名必须是大小写英文、数字和_的组合,且不能用数字开头。
1 2 3 4 5 | 例如: x = 100 # 变量x是一个整数 name = \'zhangcong\' # 变量name是一个字符串 Answer = True # 变量v是一个布尔值 _name = \'xxxxx\' # 以下划线开头也是可以的,但是不建议 |
常量
常量就是不能变的变量,比如常用的数学常数π就是一个常量。在Python中,通常用全部大写的变量名表示常量
1 2 | 例如: PI = 3.14159265359 # 但事实上PI仍然是一个变量,Python根本没有任何机制保证PI不会被改变,所以,用全部大写的变量名表示常量只是一个习惯上的用法,如果你一定要改变变量PI的值,也没人能拦住你。 |
字符编码
一、字符编码介绍:
计算机最早在设计时采用8个比特(bit)作为一个字节(byte),所以一个字节能表示的最大整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
计算机是美国人发明的,因此最早只有127个字符编码到计算机里,也就是大小写字母、数字和一些符号,这个编码被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。

如果需要处理中文一个自己肯定是不够的,至少需要两个字节,而且还不能够和ASCII编码冲突,所以中国制定了GB2312编码,用来把中文编进去。可想而知,全世界有上百种语言,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode就出现了,Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:http://i.imgur.com/0CLhcC1.png

二、字符编码工作方式
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件: http://i.imgur.com/crZJaOo.png
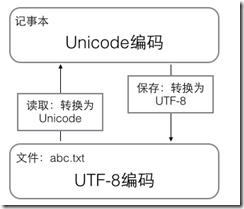
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:

对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:

如果知道字符的整数编码,还可以用十六进制这么写str,两种写法完全是等价的:

由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
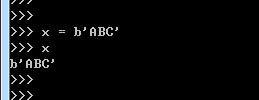
要注意区分’ABC’和b’ABC’,前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:

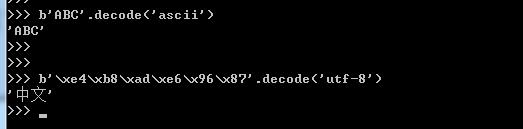
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
可以用len()函数来计算str包含多少个字符:

len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
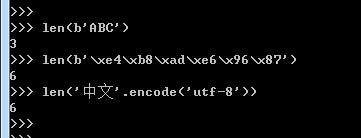
可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
12#!/usr/bin/env python3 # 告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;# -*- coding: utf-8 -*- # 告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。在windows中申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
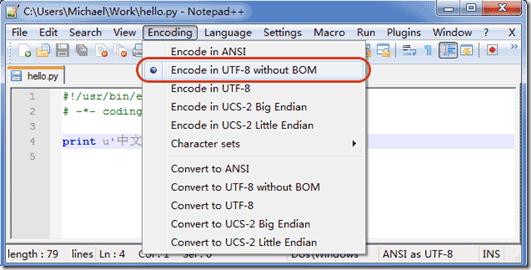
如果.py文件本身使用UTF-8编码,并且也申明了# -- coding: utf-8 --,打开命令提示符测试就可以正常显示中文,创建一个名为hello.py的文件并执行:
123#!/usr/bin/env python3coding: utf-8print(\'中文测试\')
{kind=link}
用户交互input
在程序设计的时候,往往希望通过获取用户输入的一些值,然后将获取到的值进行一些处理,例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | #!/usr/bin/env python# -*- coding: utf-8 -*-\'\'\'需求:要求用户输入姓名,年龄,工作,然后输出用户的姓名,在哪年出生,用户的工作:\'\'\'year = 2016 # 定义当前年份name = input(\'请输入你的姓名:\')age = input(\'请输入你的年龄:\')job = input(\'请输入你的工作:\')year_of_birth = year - int(age) # 出生年份print(\'\'\'姓名:%s出生年份:%s工作:%s\'\'\' % (name, year_of_birth, job)) # 输出:请输入你的姓名:阿聪请输入你的年龄:24请输入你的工作:IT姓名:阿聪出生年份:1992工作:IT |
格式化字符串
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
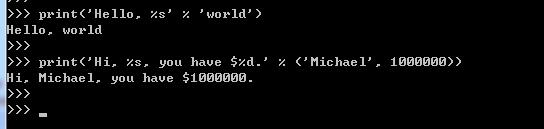
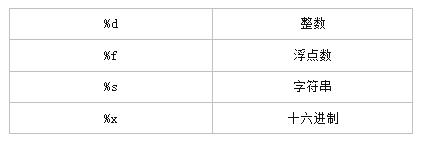
%运算符就是用来格式化字符串的。在字符串内部:%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
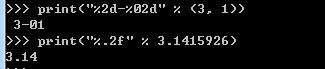
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:

有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:

Python的缩进规则
Python是强制缩进的语言,它通过缩进来确定一个新的逻辑层次的开始和结束,这也是python语言的最重要的特色之一
同一逻辑层次级别的代码缩进必须保持一致
顶层逻辑级别的代码必须不能有缩进(新行的开始不能有空格)
整个程序的缩进风格应保持一致,一般为4个空格或2个空格,官方的推荐是用4个空格,当然用tab键也可以,但是在Windows上的tab键和Linux上的不一致,会导致你在Windows上开发的程序copy到Linux上后运行出错,所以还是建议用4个空格。
注释
单行注释
12单行注释以#开头,例如:print(\'my name is zhangcong\')# 这里是注释,python解释器会直接忽略#后面的多行注释
1234567多行注释用三个引号\' 或 "将注释引起来,例如:\'\'\'这里是多行注释python解释器会忽略掉以三个单引号或双引号开头,三个单引号或双引号结尾的代码单引号和双引号成对出现,要么是一对三个单引,要么是一对三个双引\'\'\'
模块初识
Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持,以后的课程中会深入讲解常用到的各种库,现在,我们先来象征性的学2个简单的。
12345678910111213141516171819202122232425262728293031323334353637### sys 模块#!/usr/bin/env python# -*- coding: utf-8 -*-importsysprint(sys.argv)# 输出$ python test.py helo world[\'test.py\',\'helo\',\'world\']#把执行脚本时传递的参数获取到了### getpass 模块#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangcong# Mail:zc_92@sina.comimportgetpassusername=input("username:")password=getpass.getpass("password:")print(username,password)# 执行脚本后,输入密码的时候,密码那块是不显示的### os模块#!/usr/bin/env python`# -*- coding: utf-8 -*-`importosos.system(``"df -h"``)` `#调用系统命令`跟sys模块结合一下importos, sysos.system(\'\'.join(sys.argv[1:]))#把用户的输入的参数当作一条命令交给os.system来执行`
条件判断
在生活中,一件事情面临着很多选择,比如吃饭的时候,会考虑吃什么,盖饭?面条?火锅?,如果选择吃盖饭,那吃什么盖饭,尖椒肉丝?鱼香肉丝?。。。可以用python来完成上面描述的事情:
123456789input_value=input("请问想吃点什么,盖饭、面条、火锅:")ifinput_value==\'盖饭\':print("您选择的是%s!"%input_value)elifinput_value==\'面条\':print("您选择的是%s!"%input_value)elifinput_value==\'火锅\':print("您选择的是%s!"%input_value)else:print("您选的%s本店没有,谢谢光临!"%input_value)elif是else if的缩写,完全可以有多个elif,所以if语句的完整形式就是:
12345678if<条件判断1>:<执行1>elif<条件判断2>:<执行2>elif<条件判断3>:<执行3>else:<执行4>if语句执行有个特点,它是从上往下判断,如果在某个判断上是True,把该判断对应的语句执行后,就忽略掉剩下的elif和else
流程图:
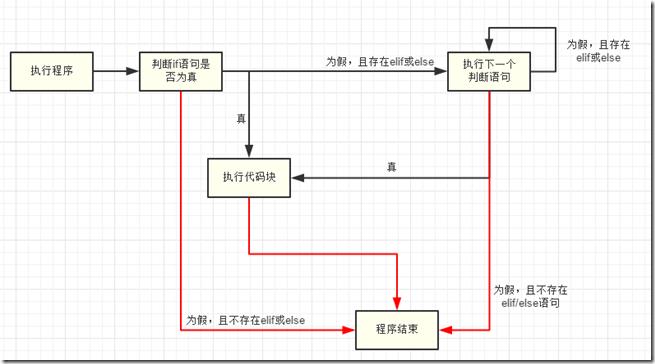
循环
python中循环有两种,分别是for循环和while循环,循环可以将序列的数据进行迭代处理:
1、for循环
for循环依次把list、tuple或字符串中的每个元素迭代出来,例如:
123456names = ["zhangcong","alex","pangzhiguo"]fornameinnames: print name# 输出zhangcongalexpangzhiguo所以for x in … 循环就是把每个元素赋值给变量x,然后执行缩进的语句 。
例:需要计算出1-10
12345678numbers=[1,2,3,4,5,6,7,8,9,10]sum=0foriinnumbers:sum+=i# sum += i == sum = sum + i 这里只是简写而已printsum# 输出55这里列表还可以用range来代替,range()函数可以生成一个整数序列,比如range(5)生成的序列是从0开始小于5的整数:
1234567891011121314151617sum=0foriinrange(1,11):sum+=iprintsum# 输出55官方是这么解释range的range(...)range(stop)->listof integersrange(start, stop[, step])->listof integersReturn alistcontaining an arithmetic progression of integers.# 返回一个包含一个等差数列的整数列表。range(i, j) returns [i, i+1, i+2, ..., j-1]; start (!) defaults to0.When stepisgiven, it specifies the increment (ordecrement).For example,range(4) returns [0,1,2,3]. The end pointisomitted!These are exactly the valid indicesforalistof4elements.
2、while循环
只要满足条件就不断循环,一般用死循环的时候会用到,比如我们要计算100以内所有奇数之和,可以用while循环实现:
1234567# 在循环内部变量n不断自减,直到变为-1时,不再满足while条件,循环退出sum=0n=99whilen >0:sum=sum+nn=n-2printsumbreak:跳出当前循环,循环结束。例如:打印1-100,当i > 50的时候退出循环
123456789101112131415161718i=1whileTrue:ifi >50: breakprint ii+=1# 输出:12345678......474849continue:跳出本次循环,进行下一次循环。例如:打印1-10,但是不包含5
123456789101112131415foriinrange(11):ifi==5:continueprinti# 输出123以上是关于python学习之路-1 python基础操作的主要内容,如果未能解决你的问题,请参考以下文章