RF内置库-----内置库的学习过程总结
Posted loleina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RF内置库-----内置库的学习过程总结相关的知识,希望对你有一定的参考价值。
前段时间充忙的学习RF,系统学习完之后就开始动手做各种接口的测试,虽然各类的接口测试基本能跑通了,但是重复造车的问题存在太明显。RF本身内置库就已经比较丰富,比如不需要import直接就加载到内存的BuiltIn库,还有需要import的常用模块String,Collections,XML库。在前面的接口测试中,使用最多的就是这几个内置库,接口返回的数据基本都是xml格式的居多,然后自己也重复造车了,为此特地花了几天时间去学习了下内置库,主要还是学了下XML库,以下的分享都是基于XML库。
学习XML内置库,我认为需要掌握以下几个知识点:
第一:内置库的概念?有哪些内置库,大概都有什么关键字?有区分版本吗?跟RF版本有关么?为什么内置库有些需要import,有些不需要import?
第二:XML内置库使用的是python的哪个标准库?对这个标准库需要有哪些基本的了解?
第三:内置库是怎么构建起来的?基本关键字是否能灵活的使用?
第四:有时候可能需要稍微修改下内置库,比如增加一些关键字等,该怎么修改?
从网上和官网(http://robotframework.org)上搜到一些资料,整理如下:
第一:内置库的基本概念?
内置库实际在官网称为standard library,就是标准库。常见的其他库比如Request,SeleniumLibrary库,官网称之为external library,就是外部库,也称第三方库。标准库和外部库首先要正确的进行区分,对于标准库,这些库是直接绑定在RF内的,在
不同版本的RF,支持不同的内置库而且相同的内置库里的关键字可能也是不一样的,以RF3.0(使用命令robot --version查看RF版本)为例,3.0是目前最新的RF的版本,支持很多的内置库,查看D:\\Python27\\Lib\\site-packages\\robot下的py文件,可以看到:
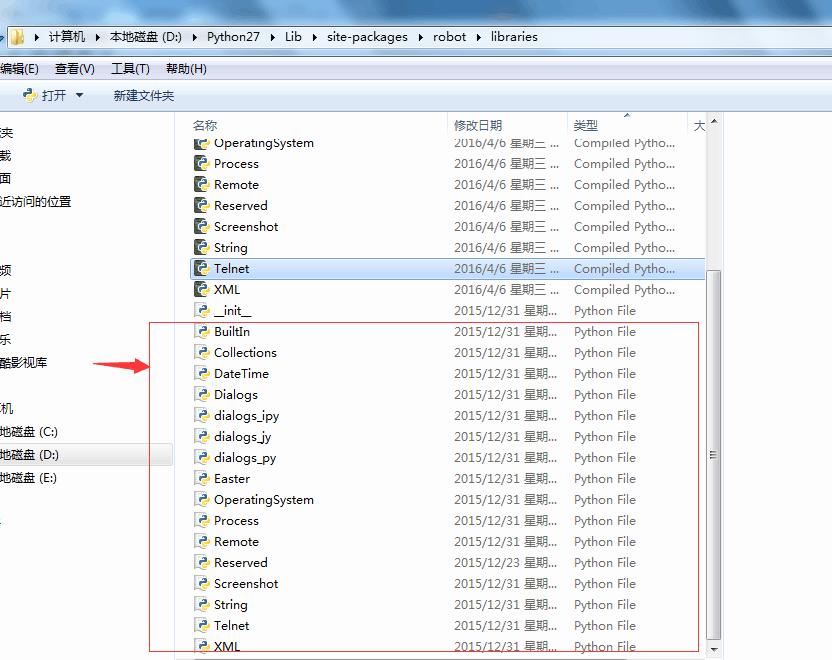
基本官网写的10个标准库都能在这里面找到相应的py文件。BuiltIn,Collections,DateTime,Dialogs,Process,OperatingSystem,Remote(没有关键字,暂时不算在内),Screenshot,String,Telnet,XML.这11个库,有些是在RF2.0的时候就已经有了的,最晚的DateTime,Process,XML是在RF2.8之后才内置的,也就是说如果当前使用的是RF2.8之前的版本,内置库是无法直接import XML就是使用的,需要下载安装才能使用,这点需要注意下,不同的RF版本,相同的标准库之间也是会细微的区别,这需要仔细的去查看保准库内每个版本的使用文档。
10个标准库,又都是做什么用的呢,这还真需要了解,而且还需要多花时间去了解每个标准库里面的关键字,这10个标准库,介绍如下:

这个表的来源是来自官网的,官网的用户手册文档已经描述的非常详细了。学习的时候可以详细的查看官网的相关文档。
第二:XML内置库的学习。
从内置库的XML的源码可以看出,RF使用的是ETree来对xml进行解析的,部分源码如下:
import copy import re import os try: from lxml import etree as lxml_etree except ImportError: lxml_etree = None from robot.api import logger from robot.libraries.BuiltIn import BuiltIn from robot.utils import (asserts, ET, ETSource, is_string, is_truthy, plural_or_not as s) from robot.version import get_version should_be_equal = asserts.assert_equal should_match = BuiltIn().should_match class XML(object): ROBOT_LIBRARY_SCOPE = \'GLOBAL\' ROBOT_LIBRARY_VERSION = get_version() _xml_declaration = re.compile(\'^<\\?xml .*\\?>\')
use_lxml = is_truthy(use_lxml)
if use_lxml and lxml_etree:
self.etree = lxml_etree
self.modern_etree = True
self.lxml_etree = True
else:
self.etree = ET
self.modern_etree = ET.VERSION >= \'1.3\'
self.lxml_etree = False
if use_lxml and not lxml_etree:
logger.warn(\'XML library reverted to use standard ElementTree \'
\'because lxml module is not installed.\')
def parse_xml(self, source, keep_clark_notation=False):
with ETSource(source) as source:
tree = self.etree.parse(source)
if self.lxml_etree:
strip = (lxml_etree.Comment, lxml_etree.ProcessingInstruction)
lxml_etree.strip_elements(tree, *strip, **dict(with_tail=False))
root = tree.getroot()
if not is_truthy(keep_clark_notation):
NameSpaceStripper().strip(root)
return root
python提供了几个标准库都可以对xml进行解析,之前我使用的是DOM,基于RF使用的是ETree,便开始学习了下ETree的开发文档。学习对XML文件的操作,那肯定也得对XML本身有最基本的了解,比如XML的用途,树结构,节点类型(DOM),带命名空间的xml。下面是部分的知识点的总结:
xml是一种可扩展的标记语言。要求标记需要成对的出现(有时候会进行简写<b/>)。一个典型的xml文档如下所示:
<example> <first id="1">text</first> <second id="2"> <child/> </second> <third> <child>more text</child> <second id="child"/> <child><grandchild/></child> </third> </example>
A. 整个xml文档是一个文档节点,属于根节点,比如上述文档的<example>节点就是一个根节点,一个xml文件只能有一个根节点,否则解析的时候胡报错的
B.每个 XML 标签是一个元素节点,比如<first> 和<second>, <third>都属于元素节点,却属于<example>的子节点。
C.attribute值:表示节点元素的属性值,比如first 有一个属性id,属性值为1;second也有id属性,属性值为2,而third没有属性。
D.Text值:表示元素中的文本内容。比如:first 的text值就为1;second没有,third也没有;
一个xml还包含其他的内容:比如处理指令和一些注释;在python的etree标准库解析的过程中,是直接把这二个给剔除掉了。有兴趣的可以根据官网给出的开发文档,把常用的一些方法都敲一遍,主要的还是使用2个类 Element Objects和ElementTree Objects。
第三:RF中XML库的学习。
在使用sudslibrary做soap协议的测试时,返回的xml是带命名空间的,之前一直不理解,对XML库进行整体的学习之后就有了很大的理解。
XML库主要有以下几个作用(翻译于原文手册):
A. 解析一个XML文件,或一个包含XML的字符串,在一个XML元素结构中,并从中寻找某些元素,用于进一步分析 (e.g. Parse XML and Get Element keywords).
B. 获取元素的文本或属性(e.g. Get Element Text and Get Element Attribute).
C. 直接验证文本、属性或全部元素 (e.g Element Text Should Be and Elements Should Be Equal).
D. 修改和保存它(e.g. Set Element Text, Add Element and Save XML).
下面按照关键字的类型大致做了以下的学习:解析的xml都是前面的xml例子
A.最常用关键字的学习:

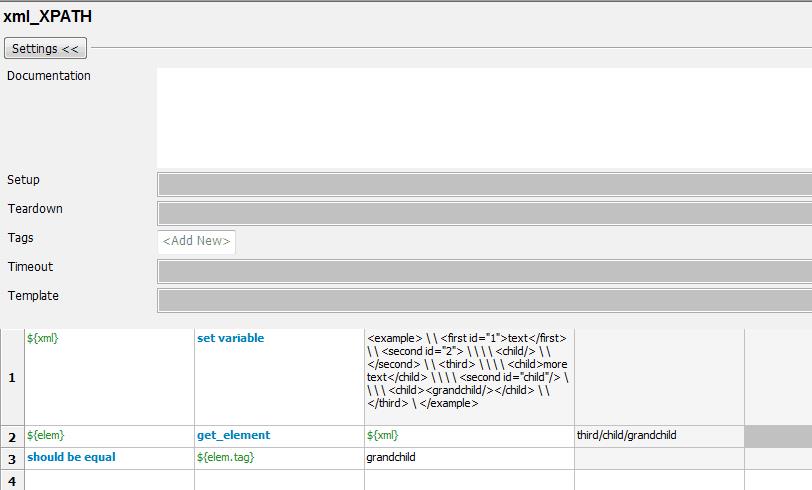
B. 通过xpath来搜素子节点。
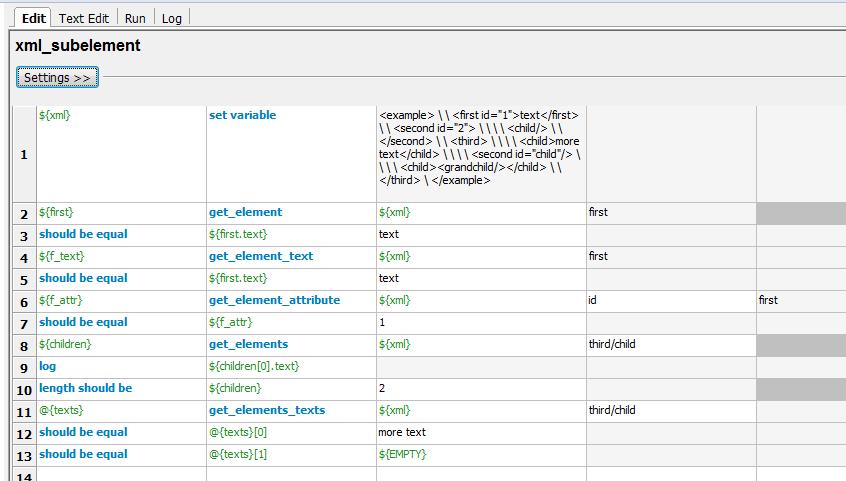
C. 简单的带命名空间的xml的解析
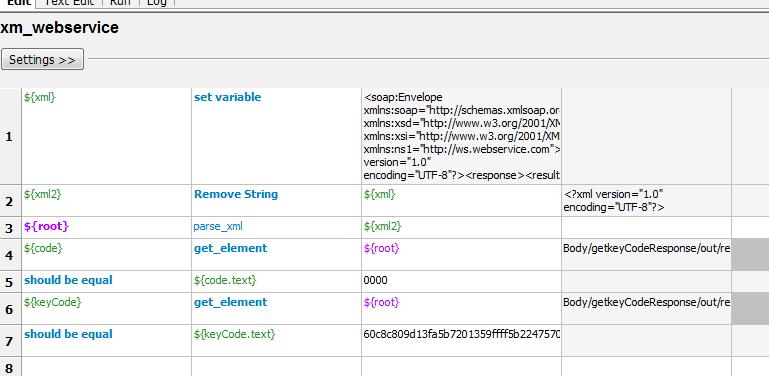
D. 复杂的命名空间的xml解析(之前soap协议返回的xml的解析部分补充)
以上是关于RF内置库-----内置库的学习过程总结的主要内容,如果未能解决你的问题,请参考以下文章