LDA主题模型三连击-入门/理论/代码
Posted 猪的饲养员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LDA主题模型三连击-入门/理论/代码相关的知识,希望对你有一定的参考价值。
本文将从三个方面介绍LDA主题模型——整体概况、数学推导、动手实现。
关于LDA的文章网上已经有很多了,大多都是从经典的《LDA 数学八卦》中引出来的,原创性不太多。
本文将用尽量少的公式,跳过不需要的证明,将最核心需要学习的部分与大家分享,展示出直观的理解和基本的数学思想,避免数学八卦中过于详细的推导。最后用python 进行实现。
概况
第一部分,包括以下四部分。
- 为什么需要
- LDA是什么
- LDA的应用
- LDA的使用
为什么需要
挖掘隐含语义信息。一个经典的例子是
“乔布斯离我们而去了。”
“苹果价格会不会降?”
上面这两个句子没有共同出现的单词,但这两个句子是相似的,如果按传统的方法判断这两个句子肯定不相似。
所以在判断文档相关性的时候需要考虑到文档的语义,而语义挖掘的利器是主题模型,LDA就是其中一种比较有效的模型。
LDA是什么
LDA主题模型,首先是在文本分类领域提出来的,它的本意是挖掘文本中的隐藏主题。它将文本看作是词袋模型(文章中的词之间没有关联)产生的过程看成 先选一堆主题,再在主题中选择词,以此构建了一篇文章。
\\(d\\)是文章
\\(z_1 ... z_n\\)是主题
\\(w\\) 是单词
\\(\\theta_{mk}\\)是文档选择主题的概率。
\\(\\varphi_{kt}\\)是主题选择词的概率。
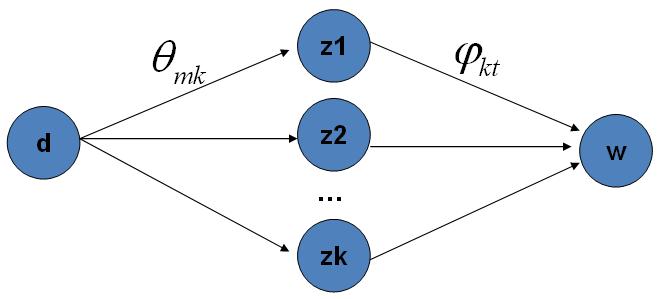
这里新手比较困惑的一点是选来选取,变量是什么?
你可以这样理解,先不要管狄利克雷分布,明确是从topic分布上选取topic,得到各topic的概率,然后再去另一个词的分布上选取刚才得到topic对应的词。

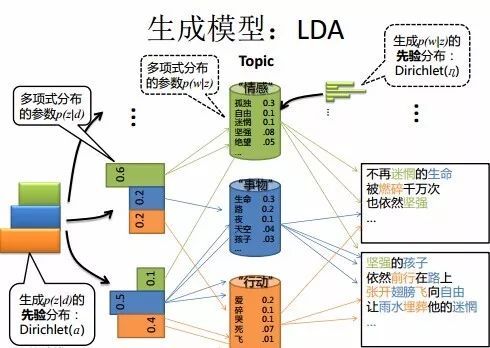
注意:此时不用想这两个分布怎么来的,只要把这个过程能想明白即可。LDA产生文档的过程。
选主题分布->选主题
设置狄利克雷分布参数α->生成主题分布:
设置狄利克雷分布参数β->生成主题的词分布:
生成主题分布->选取主题t:
生成主题t的词分布->生成词:
选取主题t->生成主题t的词分布:
LDA的应用
通过隐含语义找到关联项。
相似文档发现;
推荐商品;将该商品归属的主题下其他商品推荐给用户
主题评分;分析文档主题倾向,看哪个主题比重大
gensim应用
import jieba
import gensim
def load_stop_words(file_path):
stop_words = []
with open(file_path,encoding=\'utf8\') as f:
for word in f:
stop_words.append(word.strip())
return stop_words
def pre_process(data):
# jieba 分词
cut_list = list(map(lambda x: \'/\'.join(jieba.cut(x,cut_all=True)).split(\'/\'), data))
# 加载停用词 去除 "的 了 啊 "等
stop_words = load_stop_words(\'stop_words.txt\')
final_word_list = []
for cut in cut_list:
# 去除掉空字符和停用词
final_word_list.append(list(filter(lambda x: x != \'\' and x not in stop_words, cut)))
print(final_word_list)
word_count_dict = gensim.corpora.Dictionary(final_word_list)
# 转成词袋模型 每篇文章由词字典中的序号构成
bag_of_words_corpus = [word_count_dict.doc2bow(pdoc) for pdoc in final_word_list]
print(bag_of_words_corpus)
#返回 词袋库 词典
return bag_of_words_corpus, word_count_dict
def train_lda(bag_of_words_corpus, word_count_dict):
# 生成lda model
lda_model = gensim.models.LdaModel(bag_of_words_corpus, num_topics=10, id2word=word_count_dict)
return lda_model
# 新闻地址 http://news.xinhuanet.com/world/2017-12/08/c_1122082791.htm
train_data = [u"中方对我们的建交国同台湾开展正常经贸和民间往来不持异议,但坚决反对我们的建交国同台湾发生任何形式的官方往来或签署任何带有主权意涵的协定或合作文件",
u"湾与菲律宾签署了投资保障协定等7项合作文件。菲律宾是台湾推动“新南向”政策中首个和台湾签署投资保障协定的国家。",
u"中方坚决反对建交国同台湾发生任何形式的官方往来或签署任何带有主权意涵的协定或合作文件,已就此向菲方提出交涉"]
processed_train_data = pre_process(train_data)
lda_model = train_lda(*processed_train_data)
lda_model.print_topics(10)
数学原理
通过上节内容,在工程上基本可以用起来了。但是大家都是有追求的,不仅满足使用。这节简单介绍背后的数学原理。只会将核心部分的数学知识拿出来,不会面面俱到(我觉得这部分理解就足够了)
(详尽内容推荐去看《数学八卦》)
LDA认为各个主题的概率和各个主题下单词的概率不是固定不变的(比如通过设定3个主题的抽取概率为0.3 0.4 0.3 就一直这么用),而是由先验和样本共同通过贝叶斯计算得到的一个分布,同时还会依据不断新增加的样本进行调整。pLSA(LDA的前身) 看待分布情况就是固定的,求完就求完了,而LDA看待分布情况是 不断依据先验和样本调整。
预备知识
下面我们来介绍一下贝叶斯公式
\\(P(θ|X) = \\frac{P(X|θ)P(θ)}{P(X)}\\)
其中
后验概率 \\(P(θ|X)\\) 就是说在观察到X个样本情况下,θ的概率
先验概率 \\(P(θ)\\) 人们历史经验,比如硬币正反概率0.5 骰子每个面是1/6
似然函数 \\(P(X|θ)\\) 在\\(θ\\)下,观察到X个样本的概率
贝叶斯估计简单来说
先验分布 + 数据的知识 = 后验分布(严格的数学推导请看数学八卦)
\\begin{equation}
Beta(p|\\alpha,\\beta) + Count(m_1,m_2) = Beta(p|\\alpha+m_1,\\beta+m_2)
\\end{equation}
对于选主题,选单词这个过程,LDA将其主题,单词的分布看作是两个后验概率来求解。因为这两个过程每次的结果都和骰子类似,有多种情况,因此是一个多项式分布对应抽样分布\\(P(\\theta)\\),对于多项式为抽样分布来说,狄利克雷分布是它的共轭分布。
先验分布反映了某种先验信息,后验分布既反映了先验分布提供的信息,又反映了样本提供的信息。若先验分布和抽样分布决定的后验分布与先验分布是同类型分布,则称先验分布为抽样分布的共轭分布。当先验分布与抽样分布共轭时,后验分布与先验分布属于同一种类型,这意味着先验信息和样本信息提供的信息具有一定的同一性。
- Beta的共轭分布是伯努利分布;
- 多项式分布的共轭分布是狄利克雷分布;
- 高斯分布的共轭分布是高斯分布。
那么狄利克雷分布什么样子?
先介绍\\(\\Gamma\\)函数和\\(B\\)函数
狄利克雷分布为下图,其中\\(\\alpha_1 ... \\alpha_n\\)就是每个类型的伪先验(按照历史经验和常识,比如骰子每个面都出现10次)
抽取模型
介绍完了基础的数学知识,现在来看下如何得到LDA模型。
因为LDA是词袋模型,各个主题,各个词之间并没有关联,因此我们对于M篇文章,K个主题,可以两次抽取,第一次抽取M个 topics 生成概率,第二次获取K个主题的词生成概率
主题生成概率
\\(\\vec{\\mathbf{z}}\\)是topic主题向量
\\(\\vec{\\alpha}\\)是在训练时指定的参数
根据贝叶斯参数估计,可以得到主题的分布概率如下
\\(\\begin{align} p(\\vec{\\mathbf{z}} |\\vec{\\alpha}) & = \\prod_{m=1}^M p(\\vec{z}_m |\\vec{\\alpha}) \\notag \\\\ &= \\prod_{m=1}^M \\frac{\\Delta(\\vec{n}_m+\\vec{\\alpha})}{\\Delta(\\vec{\\alpha})}\\quad\\quad (*) \\end{align}\\)
词生成概率
\\(p(\\vec{\\mathbf{w}}|\\vec{\\mathbf{z}},\\vec{\\mathbf{\\beta}})\\) 是在指定的主题\\(z\\)和给定的参数\\(\\beta\\)下词生成概率 \\(z\\) 就是上一步得到的主题
\\(\\begin{align} p(\\overrightarrow{\\mathbf{w}} |\\overrightarrow{\\mathbf{z}},\\overrightarrow{\\beta}) &= p(\\overrightarrow{\\mathbf{w}}\' |\\overrightarrow{\\mathbf{z}}\',\\overrightarrow{\\beta}) \\notag \\\\ &= \\prod_{k=1}^K p(\\overrightarrow{w}_{(k)} | \\overrightarrow{z}_{(k)}, \\overrightarrow{\\beta}) \\notag \\\\ &= \\prod_{k=1}^K \\frac{\\Delta(\\overrightarrow{n}_k+\\overrightarrow{\\beta})}{\\Delta(\\overrightarrow{\\beta})} \\quad\\quad (**) \\end{align}\\)
模型
综合主题模型和词模型得到下面公式,就是LDA模型的分布
在\\(\\alpha,\\beta\\)参数下,依据抽取主题->抽取词过程可以得到下面的分布,这个分布就是LDA模型的分布
\\(\\begin{align}
p(\\overrightarrow{\\mathbf{w}},\\overrightarrow{\\mathbf{z}} |\\overrightarrow{\\alpha}, \\overrightarrow{\\beta}) &=
p(\\overrightarrow{\\mathbf{w}} |\\overrightarrow{\\mathbf{z}}, \\overrightarrow{\\beta}) p(\\overrightarrow{\\mathbf{z}} |\\overrightarrow{\\alpha}) \\notag \\\\
&= \\prod_{k=1}^K \\frac{\\Delta(\\overrightarrow{n}_k+\\overrightarrow{\\beta})}{\\Delta(\\overrightarrow{\\beta})}
\\prod_{m=1}^M \\frac{\\Delta(\\overrightarrow{n}_m+\\overrightarrow{\\alpha})}{\\Delta(\\overrightarrow{\\alpha})} \\quad\\quad (***)
\\end{align}\\)
样本生成
虽然我们得到了模型的分布,但是如何获取到符合这个分布的样本(一个具体的实例)?
这里就涉及到采样的知识了,也就是马尔科夫/Gibbs等知识。
简单来说,马尔科夫链中当前状态仅与前一个状态有关,而与其他状态无关
同时对于大部分有转移矩阵P的马氏链(非周期),从任何一个状态转移,最终都会收敛到一个状态
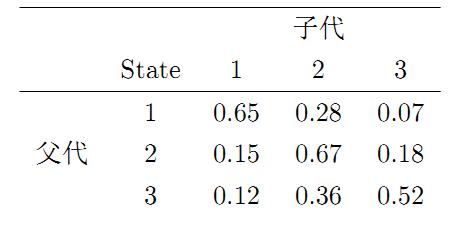
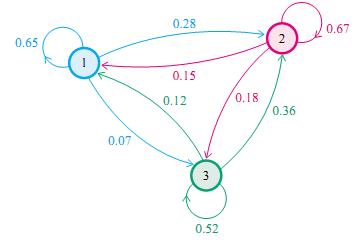

在这里的思路是,构造一个马氏链让其的转移概率等于我们需要的LDA分布。
Gibbs就是一个效率很高的满足这样方式的一个算法。
这块的推导公式可以看数学八卦,不过理解到对其采样即可。
关于Gibbs采样大家可以参考
计算流程为
具体Gibbs采样方程为
\\(\\begin{equation} p(z_i = k|\\overrightarrow{\\mathbf{z}}_{\\neg i}, \\overrightarrow{\\mathbf{w}}) \\propto \\frac{n_{m,\\neg i}^{(k)} + \\alpha_k}{\\sum_{k=1}^K (n_{m,\\neg i}^{(k)} + \\alpha_k)} \\cdot \\frac{n_{k,\\neg i}^{(t)} + \\beta_t}{\\sum_{t=1}^V (n_{k,\\neg i}^{(t)} + \\beta_t)} \\end{equation}\\)
有了公式后,算法流程为


代码编写
运行代码前先设置一下train_file.txt 文件,安装numpy
得到了Gibbs计算公式后,对于每个单词来说(每个单词对应一个主题,就是一个(topic,word)元组) 通过每次去除该词topic和词本身在分布中的计数得到了条件分布\\(P(z=k,w=t|z_{\\neg k},w_{\\neg t})\\)
然后计算得到本次的topic,在放入计算矩阵doc_word_topic中。
以下为代码,注释详尽
#-*- coding:utf-8 -*-
import random
import codecs
import os
import numpy as np
from collections import OrderedDict
import sys
print(sys.stdin.encoding)
train_file = \'train_file.txt\'
bag_word_file = \'word2id.txt\'
# save file
# doc-topic
phi_file = \'phi_file.txt\'
# word-topic
theta_file = \'theta_file.txt\'
############################
alpha = 0.1
beta = 0.1
topic_num = 10
iter_times = 100
##########################
class Document(object):
def __init__(self):
self.words = []
self.length = 0
class DataDict(object):
def __init__(self):
self.docs_count = 0
self.words_count = 0
self.docs = []
self.word2id = OrderedDict()
def add_word(self, word):
if word not in self.word2id:
self.word2id[word] = self.words_count
self.words_count += 1
return self.word2id[word]
def add_doc(self, doc):
self.docs.append(doc)
self.docs_count += 1
def save_word2id(self, file):
with codecs.open(file, \'w\',\'utf-8\') as f:
for word,id in self.word2id.items():
f.write(word +"\\t"+str(id)+"\\n")
class DataClean(object):
def __init__(self, train_file):
self.train_file = train_file
self.data_dict = DataDict()
\'\'\'
input: text-word matrix
\'\'\'
def process_each_doc(self):
for text in self.texts:
doc = Document()
for word in text:
word_id = self.data_dict.add_word(word)
doc.words.append(word_id)
doc.length = len(doc.words)
self.data_dict.add_doc(doc)
def clean(self):
with codecs.open(self.train_file, \'r\',\'utf-8\') as f:
self.texts = f.readlines()
self.texts = list(map(lambda x: x.strip().split(), self.texts))
assert type(self.texts[0]) == list , \'wrong data format, texts should be two dimension\'
self.process_each_doc()
class LDAModel(object):
def __init__(self, data_dict):
self.data_dict = data_dict
#
# 模型参数
# 主题数topic_num
# 迭代次数iter_times,
# 每个类特征词个数top_words_num
# 超参数alpha beta
#
self.beta = beta
self.alpha = alpha
self.topic_num = topic_num
self.iter_times = iter_times
# p,概率向量 临时变量
self.p = np.zeros(self.topic_num)
# word-topic_num: word-topic matrix 一个word在不同topic的数量
# topic_word_sum: 每个topic包含的word数量
# doc_topic_num: doc-topic matrix 一篇文档在不同topic的数量
# doc_word_sum: 每篇文档的词数
self.word_topic_num = np.zeros((self.data_dict.words_count, \\
self.topic_num),dtype="int")
self.topic_word_sum = np.zeros(self.topic_num,dtype="int")
self.doc_topic_num = np.zeros((self.data_dict.docs_count, \\
self.topic_num),dtype="int")
self.doc_word_sum = np.zeros(data_dict.docs_count,dtype="int")
# doc_word_topic 每篇文章每个词的类别 size: len(docs),len(doc)
# theta 文章->类的概率分布 size: len(docs), topic_num
# phi 类->词的概率分布 size: topic_num, len(doc)
self.doc_word_topic = \\
np.array([[0 for y in range(data_dict.docs[x].length)] \\
for x in range(data_dict.docs_count)])
self.theta = np.array([[0.0 for y in range(self.topic_num)] \\
for x in range(self.data_dict.docs_count)])
self.phi = np.array([[0.0 for y in range(self.data_dict.words_count)] \\
for x in range(self.topic_num)])
#随机分配类型
for doc_idx in range(len(self.doc_word_topic)):
for word_idx in range(self.data_dict.docs[doc_idx].length):
topic = random.randint(0,self.topic_num - 1)
self.doc_word_topic[doc_idx][word_idx] = topic
# 对应矩阵topic内容增加
word = self.data_dict.docs[doc_idx].words[word_idx]
self.word_topic_num[word][topic] += 1
self.doc_topic_num[doc_idx][topic] += 1
self.doc_word_sum[doc_idx] += 1
self.topic_word_sum[topic] += 1
def sampling(self, doc_idx, word_idx):
topic = self.doc_word_topic[doc_idx][word_idx]
word = self.data_dict.docs[doc_idx].words[word_idx]
# Gibbs 采样,是去除上一次原本情况的采样
self.word_topic_num[word][topic] -= 1
self.doc_topic_num[doc_idx][topic] -= 1
self.topic_word_sum[topic] -= 1
self.doc_word_sum[doc_idx] -= 1
# 构造计算公式
Vbeta = self.data_dict.words_count * self.beta
Kalpha = self.topic_num * self.alpha
self.p = (self.word_topic_num[word] + self.beta) / \\
(self.topic_word_sum + Vbeta) * \\
(self.doc_topic_num[doc_idx] + self.alpha) / \\
(self.doc_word_sum[doc_idx] + Kalpha)
for k in range(1,self.topic_num):
self.p[k] += self.p[k-1]
# 选取满足本次抽样的topic
u = random.uniform(0,self.p[self.topic_num - 1])
for topic in range(self.topic_num):
if self.p[topic] > u:
break
# 将新topic加回去
self.word_topic_num[word][topic] += 1
self.doc_topic_num[doc_idx][topic] += 1
self.topic_word_sum[topic] += 1
self.doc_word_sum[doc_idx] += 1
return topic
def _theta(self):
for i in range(self.data_dict.docs_count):
self.theta[i] = (self.doc_topic_num[i]+self.alpha)/ \\
(self.doc_word_sum[i]+self.topic_num * self.alpha)
def _phi(self):
for i in range(self.topic_num):
self.phi[i] = (self.word_topic_num.T[i] + self.beta)/ \\
(self.topic_word_sum[i]+self.data_dict.words_count * self.beta)
def train_lda(self):
for x in range(self.iter_times):
for i in range(self.data_dict.docs_count):
for j in range(self.data_dict.docs[i].length):
topic = self.sampling(i,j)
self.doc_word_topic[i][j] = topic
print("迭代完成。")
print("计算文章-主题分布")
self._theta()
print("计算词-主题分布")
self._phi()
def main():
data_clean = DataClean(train_file)
data_clean.clean()
data_dict = data_clean.data_dict
data_dict.save_word2id(bag_word_file)
lda = LDAModel(data_dict)
lda.train_lda()
if __name__ == \'__main__\':
main()
以上是关于LDA主题模型三连击-入门/理论/代码的主要内容,如果未能解决你的问题,请参考以下文章