CentOS7.5之spark2.3.0安装
Posted Frankdeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CentOS7.5之spark2.3.0安装相关的知识,希望对你有一定的参考价值。
一 使用IDEA开发Spark程序
1、打开IDEA的官网地址,地址如下:http://www.jetbrains.com/idea/
2、点击DOWNLOAD,按照自己的需求下载安装,我们用免费版即可。
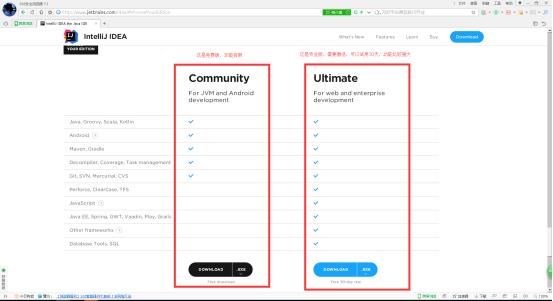
3、双击ideaIU-15.0.2.exe安装包,点击Next。
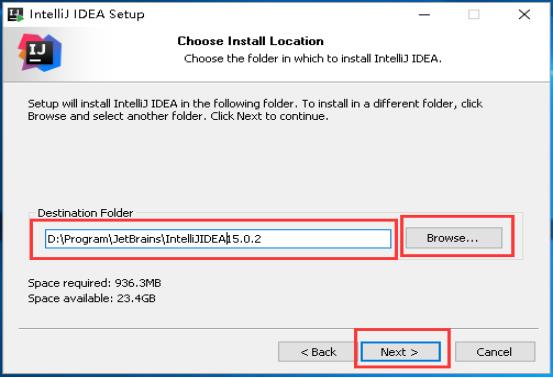
4、选择安装路径,点击Next。
5、可以选择是否创建桌面快捷方式,然后点击Next。
6、点击Install。
7、安装过程
8、点击Finish,安装成功
9、双击IntelliJ IDEA 15.0.2的图标,打开IntelliJ IDEA。

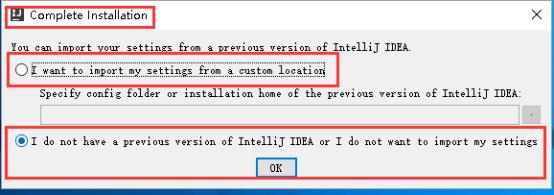
10、可以导入自己的设置,没有就选择下面的即可,然后点击OK。
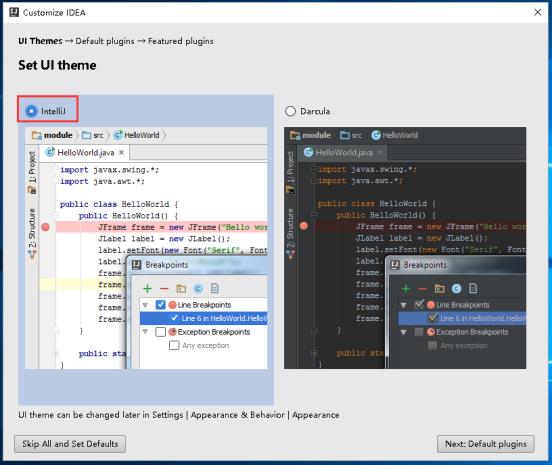
11、选择自己喜欢的风格
(1) 风格1
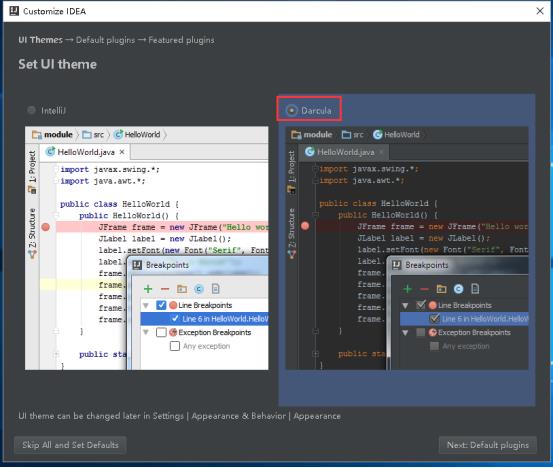
(2) 风格2
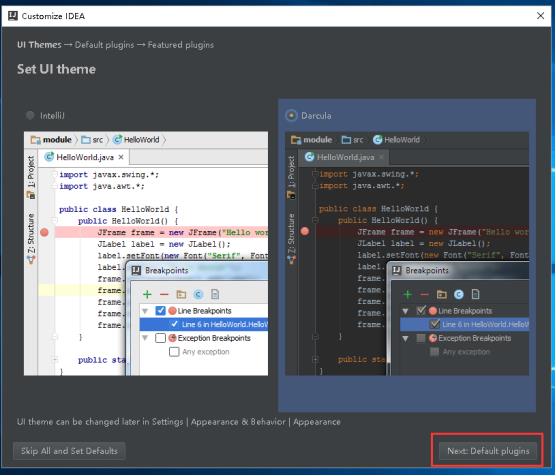
12、选择完风格后,点击Next Default plugins
13、点击Next Featured plugins
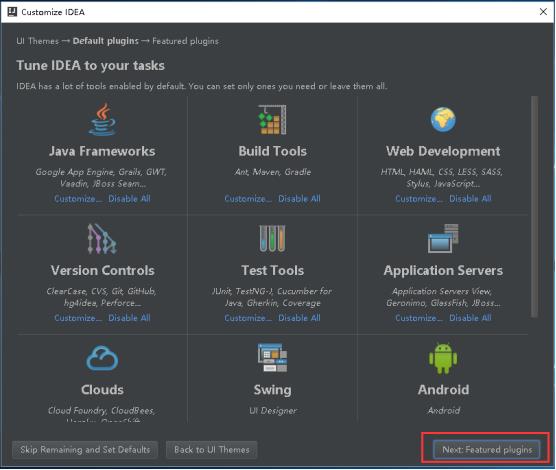
14、点击Scala Custom Languages 下面的Install
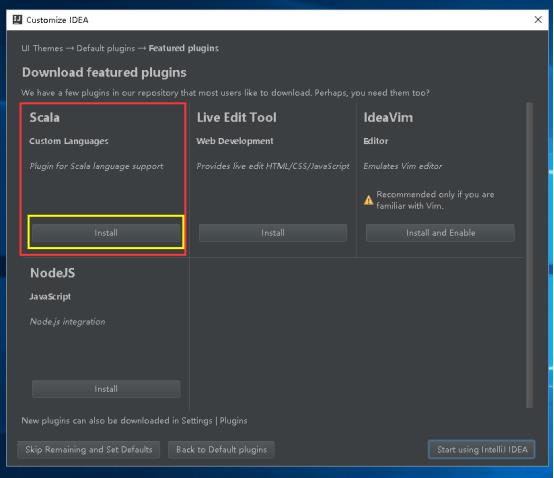
15、安装过程
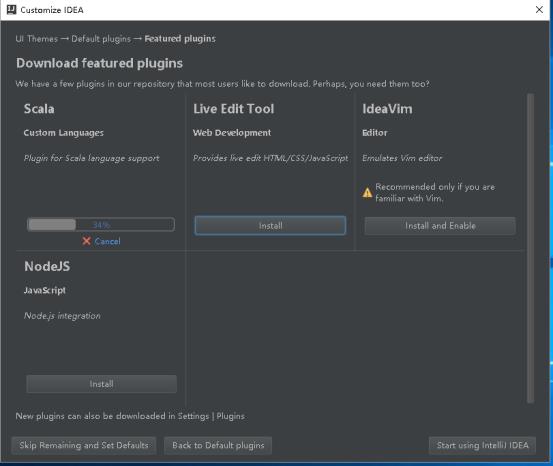
16、显示Installed就代表安装成功了,然后点击Start using IntelliJ IDEA。
17、点击Create New Project,创建新工程。
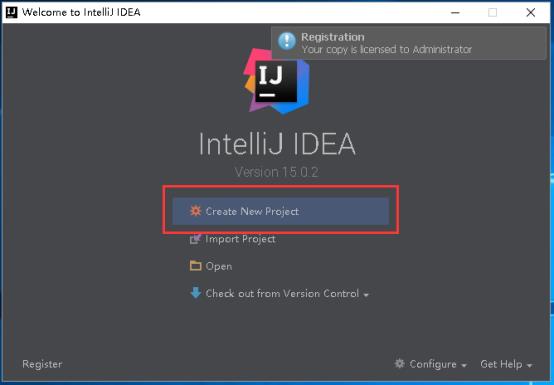
18、选择Scala,点击Next。
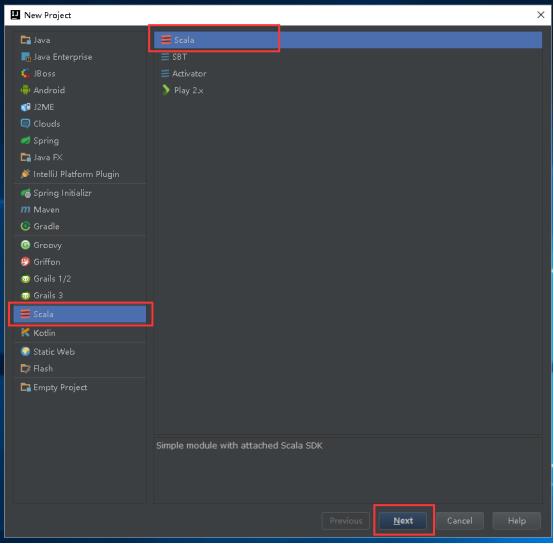
19、填写Project name和Project location。
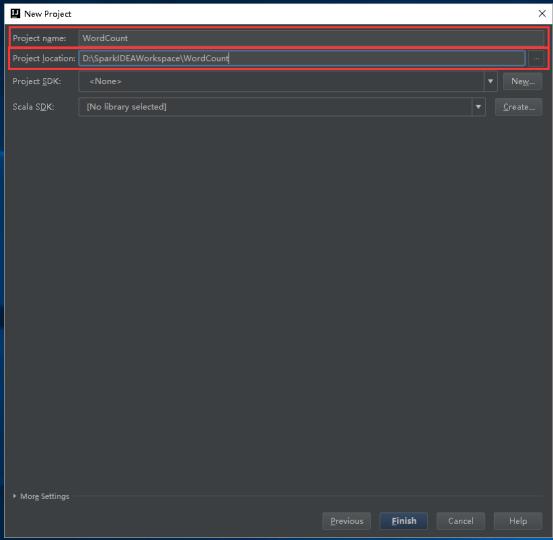
20、设置Project SDK,点击New。
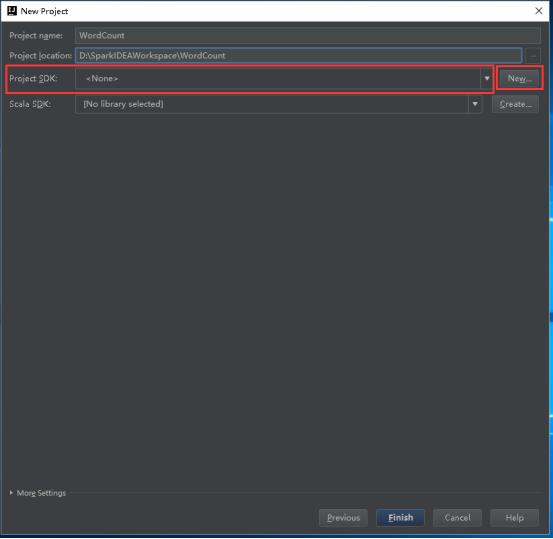
21、点击New打开的小窗口里点击JDK。
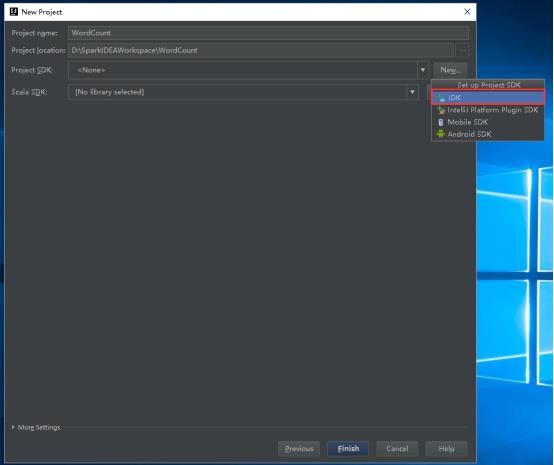
22、选择安装JDK的路径,点击OK
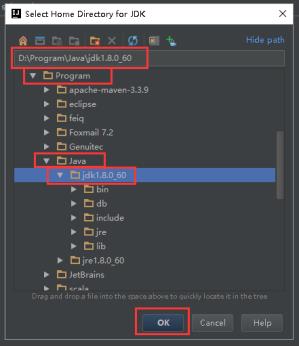
23、Project SDK会变成如下面图所示,是你安装的JDK版本
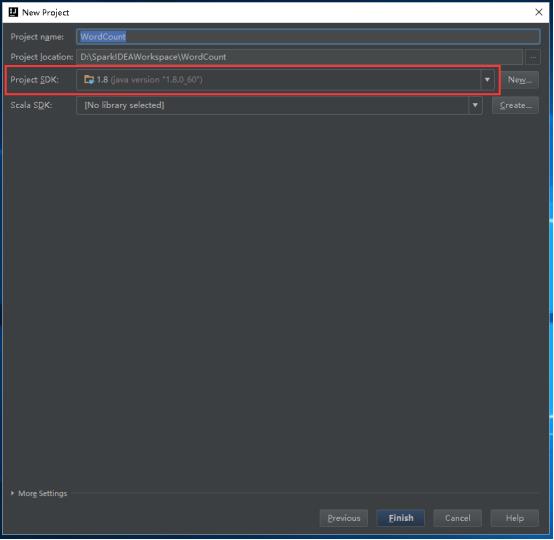
24、设置Scala SDK,点击Create。
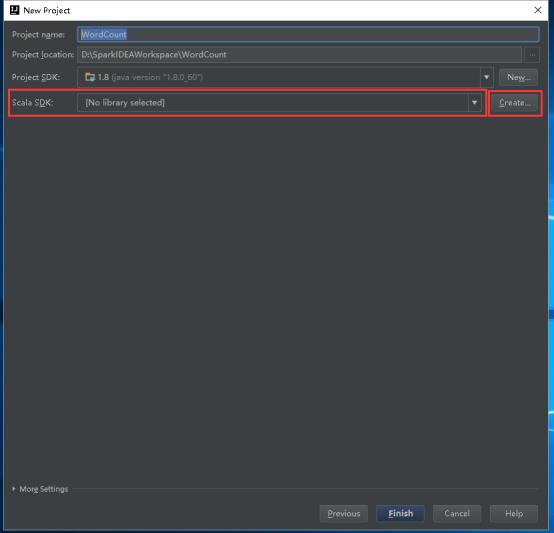
25、选择这台机器安装的2.10.x版本,然后点击OK。
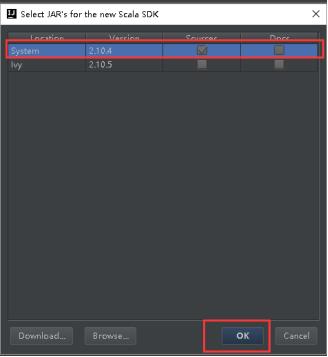
26、然后就变成如图所示,然后点击Finish。
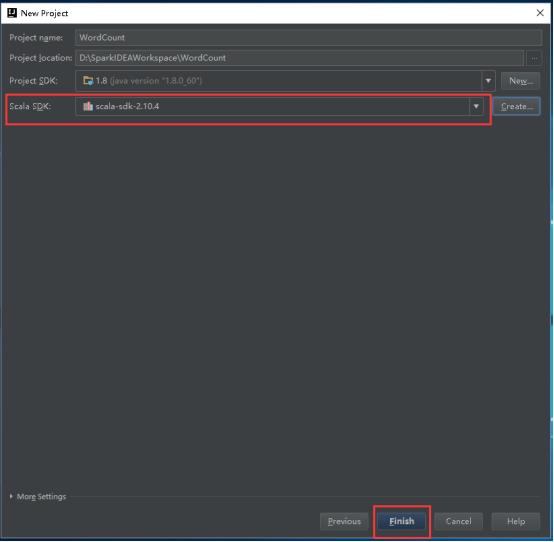
27、出现这个提示,直接点击OK。
28、出现这个窗口,把Show Tips on Startup勾掉,点击Close即可。
29、项目创建成功以后的目录如下:
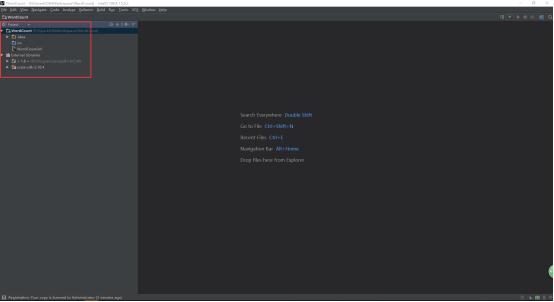
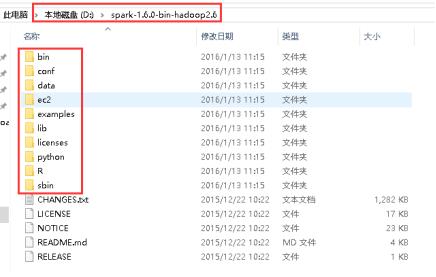
30、下载spark-1.6.0-bin-hadoop2.6.tgz,解压spark-1.6.0-bin-hadoop2.6.tgz,解压以后目录如下:
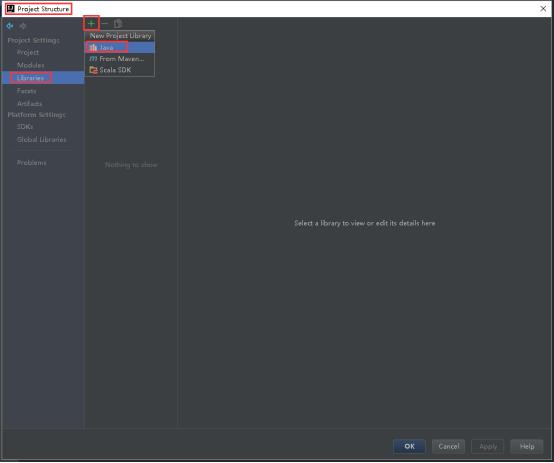
31、添加Spark的jar依赖,File-> Project Structure -> Libraries,点击号,选择Java。
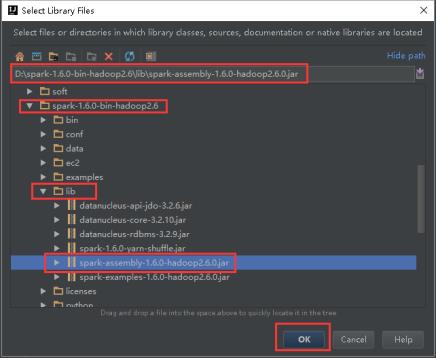
32、进入到解压以后的spark-1.6.0-bin-hadoop2.6的lib目录下,选择spark-assembly-1.6.0-hadoop2.6.0.jar,如下图所示,然后点击OK。
33、点击OK。
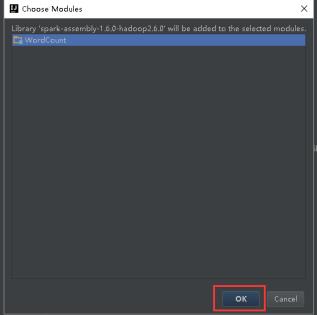
34、如下图所示,然后点击OK。
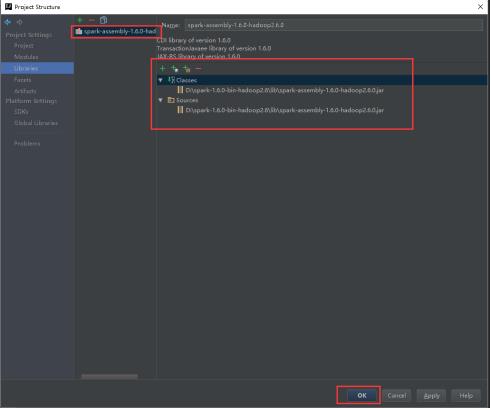
35、项目会变成如下图所示。
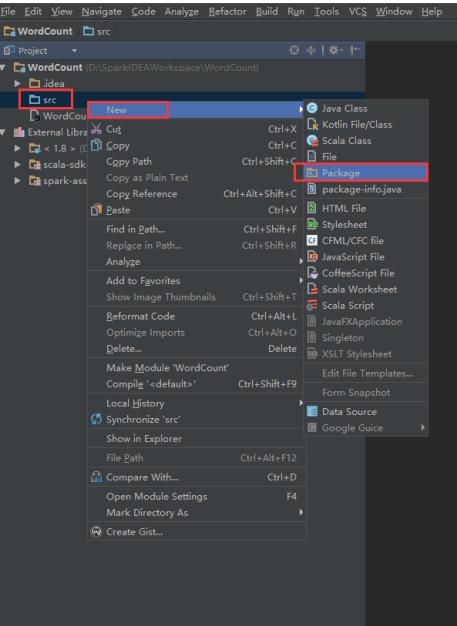
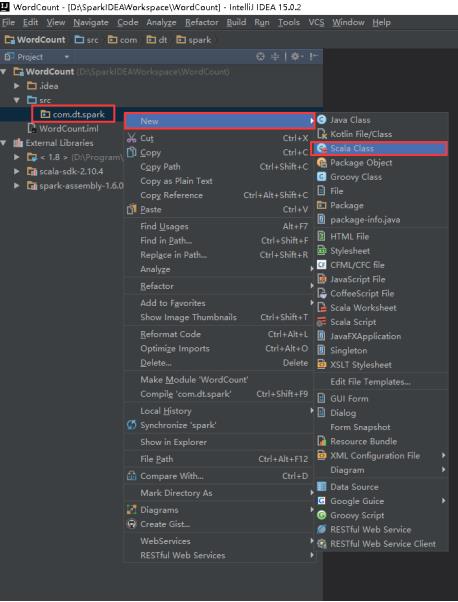
36、右击src -> New -> Package。
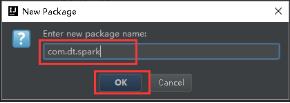
37、填写好包名,点击OK。
38、右击com.dt.spark -> New -> Scala Class。
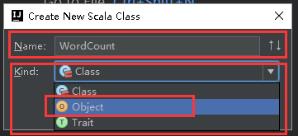
39、Name填写WordCount,Kind里选择Object,点击OK。
40、WordCount里添加main方法,如下图。
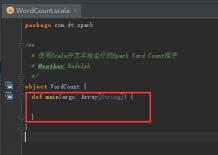
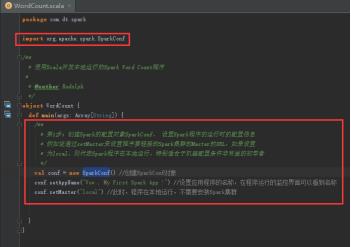
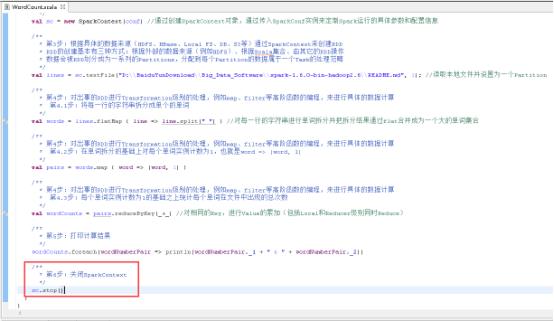
41、开始编写Spark WordCount项目,创建SparkConf,设置conf的参数,设置应用程序名称,使用local模式执行,图里的第1步。
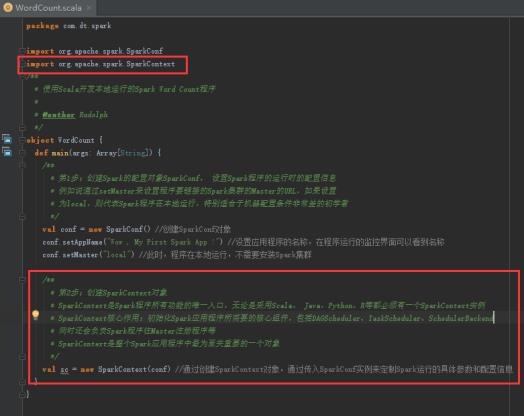
42、创建SparkContext对象,图里第2步。
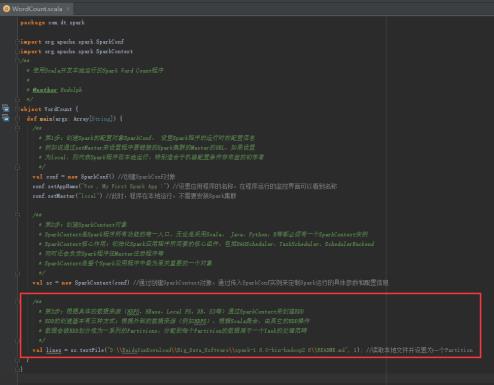
43、读取本地文件,图里的第3步。
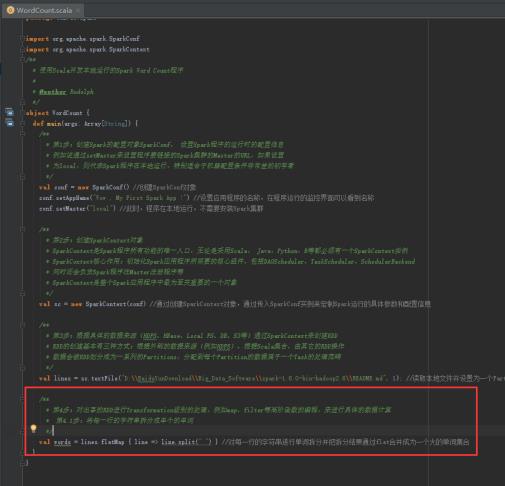
44、将每一行的字符串拆分成单个的单词,图里的第4.1步。
45、在单词拆分的基础上对每个单词实例计数为1,也就是word => (word, 1),图里4.2步。
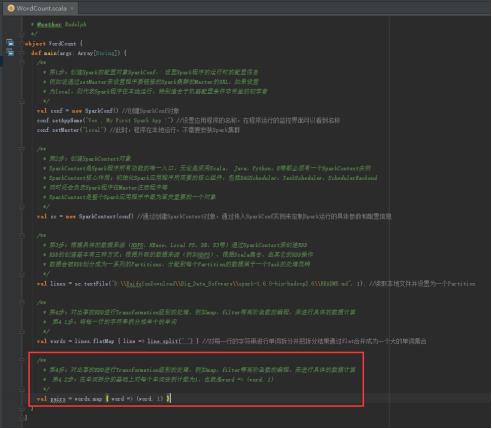
46、每个单词实例计数为1的基础之上统计每个单词在文件中出现的总次数,图里4.3步。
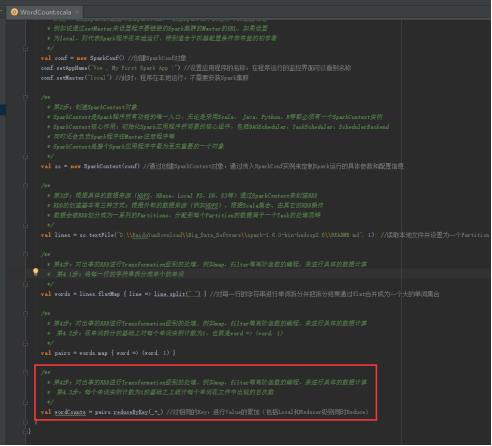
47、打印计算结果,图里的第5步。
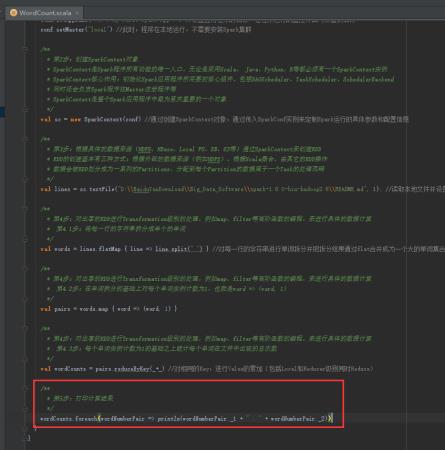
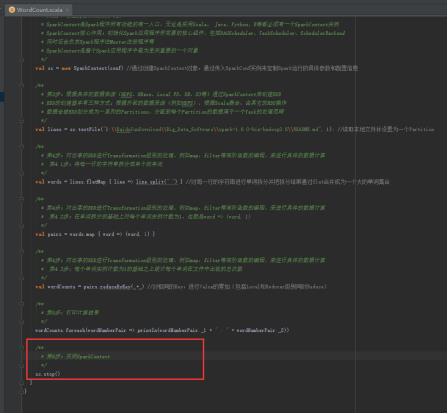
48、关闭SparkContext,图里的第6步。
49、运行开发的项目,右击WorkCount.scala文件 -> Run ‘Word Count’。
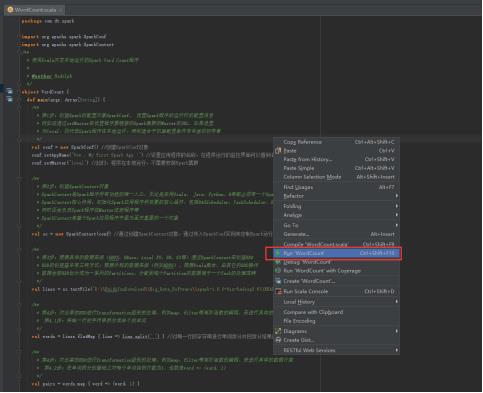
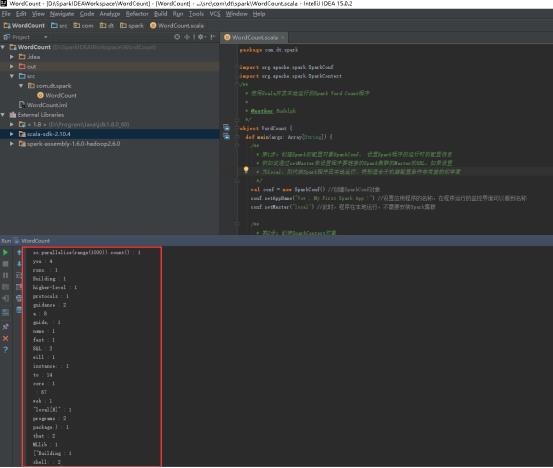
50、看见这样的结果,就代表成功了。
二 使用Scala IDE 开发Spark程序
1、打开Scala IDE for Eclipse的官网,官网地址:http://scala-ide.org/
2、点击Download IDE。
3、下载对应的版本。
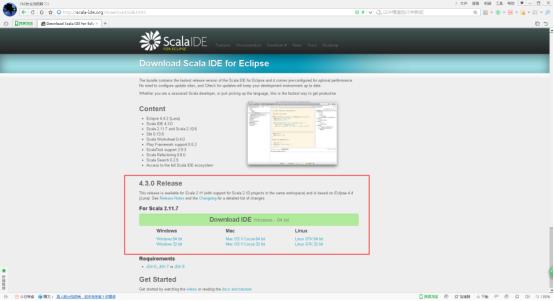
4、scala-SDK-4.3.0-vfinal-2.11-win32.win32.x86_64.zip为例,解压缩。
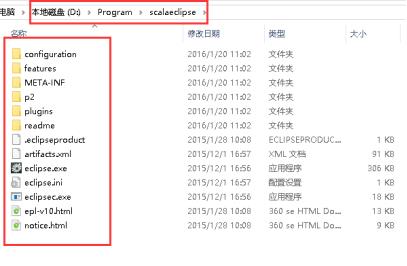
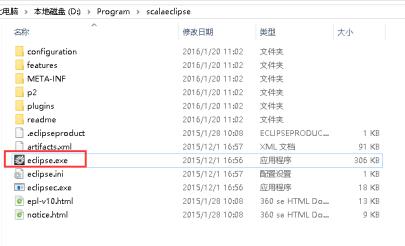
5、双击打开eclipse.exe。
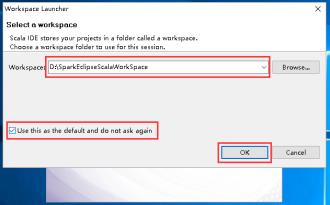
6、选择一个工作目录,然后点击OK。
7、在打开的窗口中,File -> New -> Scala Project。
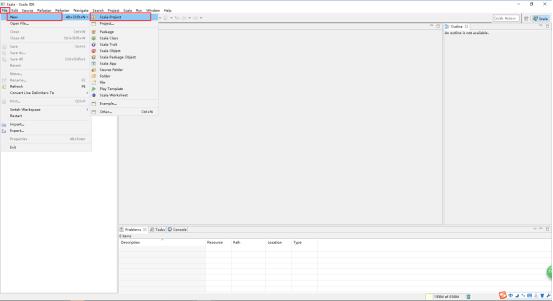
8、写好Project name,点击Next。
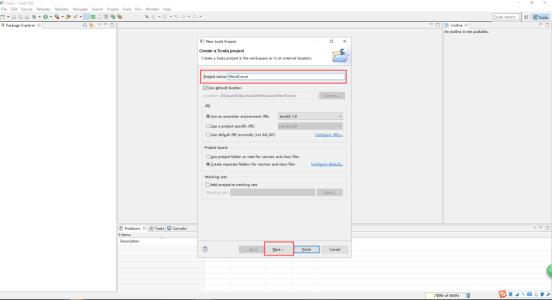
9、点击Finish。
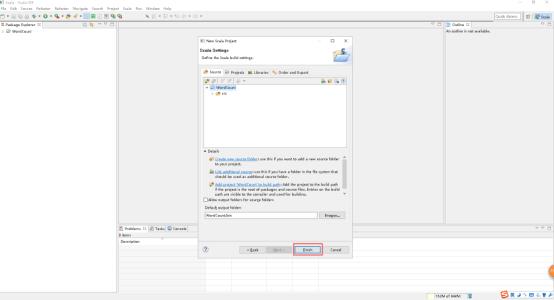
10、修改JRE System Library。
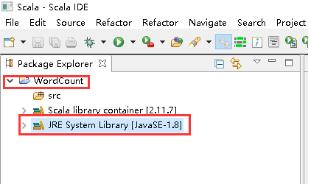
11、右击JRE System Library -> Build Path -> Configure Build Path...。
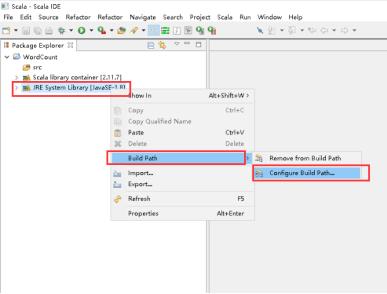
12、点击JRE System Library -> Edit。
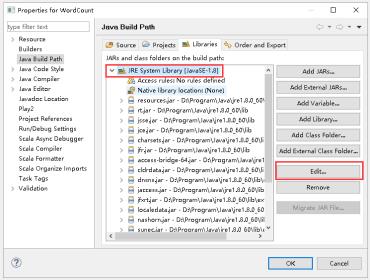
13、选择Alternate JRE -> Installed JREs...。
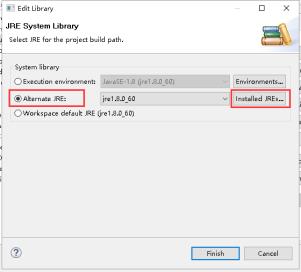
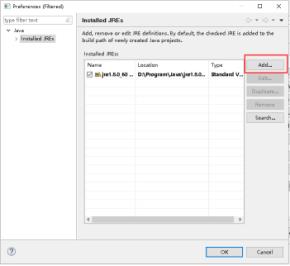
14、点击Add...。
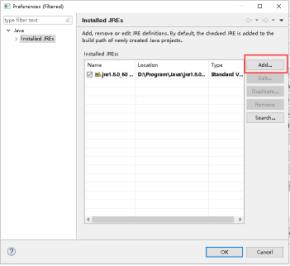
15、选择Standard VM,点击Next。
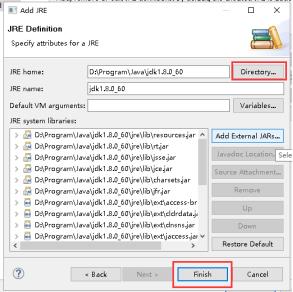
16、点击Directory...,选择本地文件安装JDK的安装目录,点击Finish。
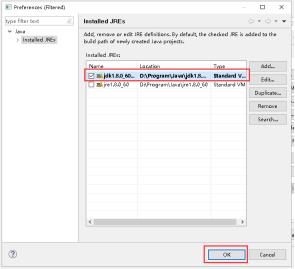
17、选择刚才加入的JDK,点击OK。
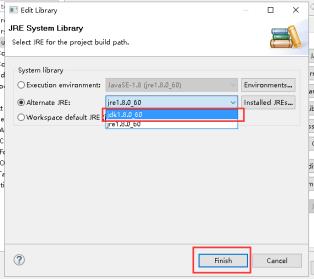
18、下拉列表里选择刚才加入的JDK,点击Finish。
19、点击OK。
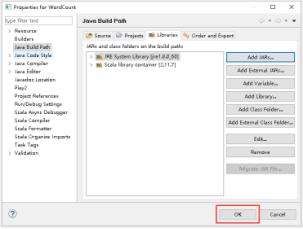
20、设置Scala library container。
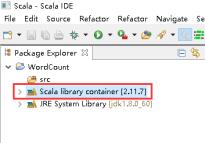
21、项目上有右击 -> Properties。
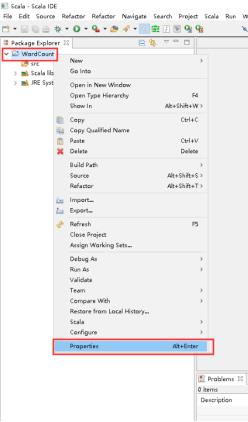
22、打开的窗口点击Scala Compiler。
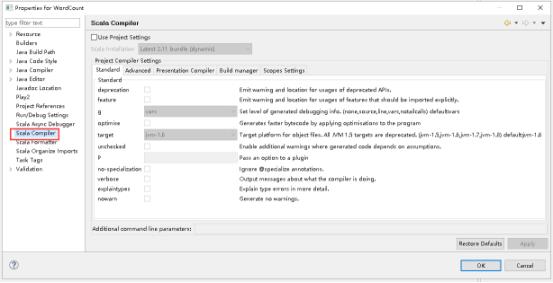
23、Use Project Settings打钩,打开Scala Installation下拉列表,选择Latest 2.10 bundle(dynamic),点击OK。
24、点击OK。
25、下载spark-1.6.0-bin-hadoop2.6.tgz,解压spark-1.6.0-bin-hadoop2.6.tgz,解压以后目录如下:
26、添加Spark的jar依赖,项目右击 -> Build Path -> Configure Build Path...。
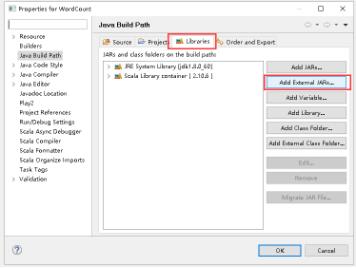
27、点击Libraries -> Add External JARs...。
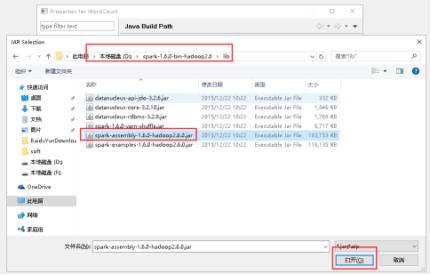
28、选择lib目录下的spark-assembly-1.6.0-hadoop2.6.0.jar文件,点击打开。
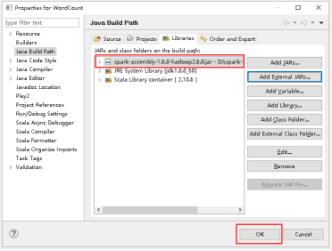
29、点击OK。
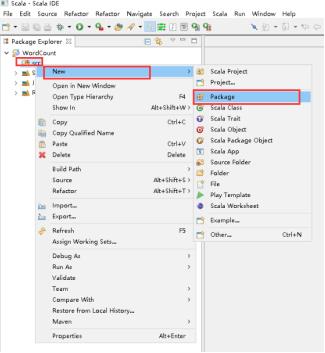
30、项目里创建包,右击src -> New -> Package。
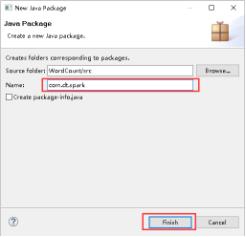
31、填写好Name,点击Finish。
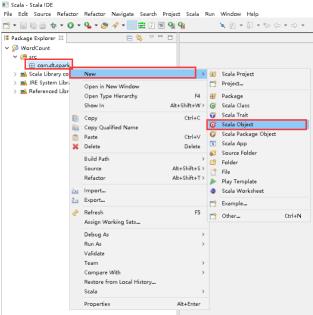
32、创建Scala Object,右击com.dt.spark -> New -> Scala Object。
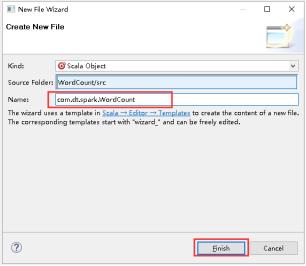
33、填写好Name,点击Finish。
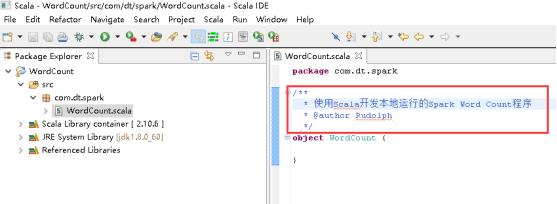
34、开始编写WordCount,写Title。
35、添加main方法。
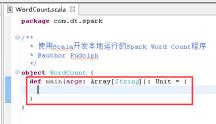
36、创建SparkConf对象,图里的第1步。
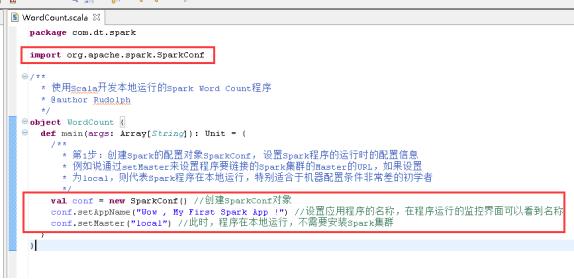
37、创建SparkContext对象,图里的第2步。
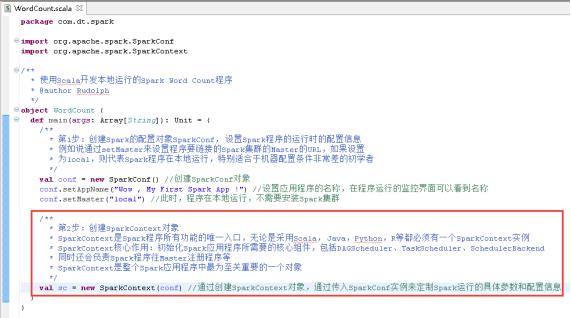
38、读取本地文件,图里的第3步
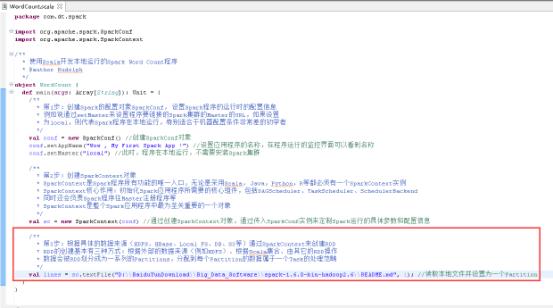
39、将每一行的字符串拆分成单个的单词,图里的第4.1步。
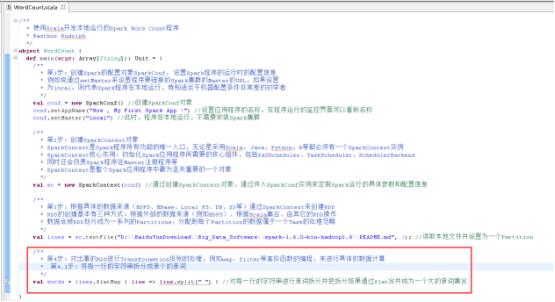
40、在单词拆分的基础上对每个单词实例计数为1,也就是word => (word, 1),图里4.2步。
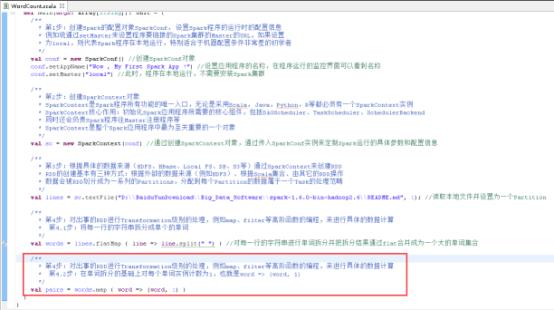
41、每个单词实例计数为1的基础之上统计每个单词在文件中出现的总次数,图里4.3步。
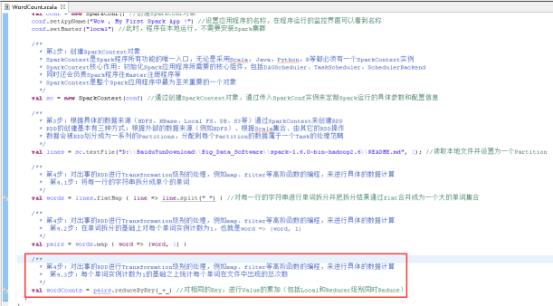
42、打印计算结果,图里的第5步。
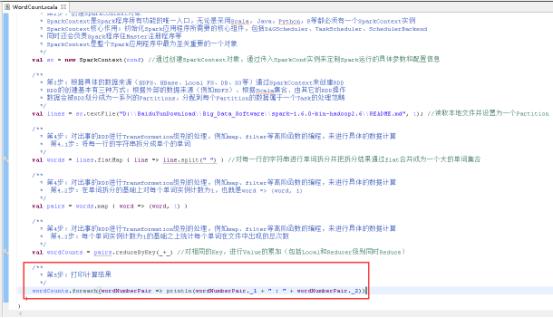
43、关闭SparkContext,图里的第6步。
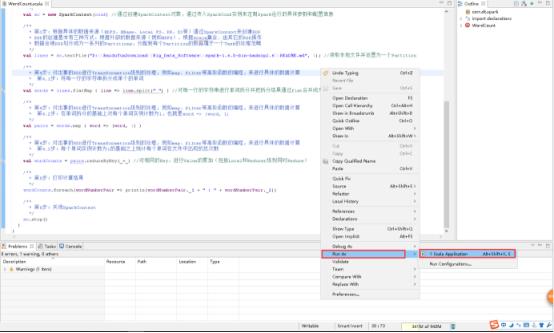
44、运行项目,右击WorkCount.scala文件 -> Run As -> Scala Application。
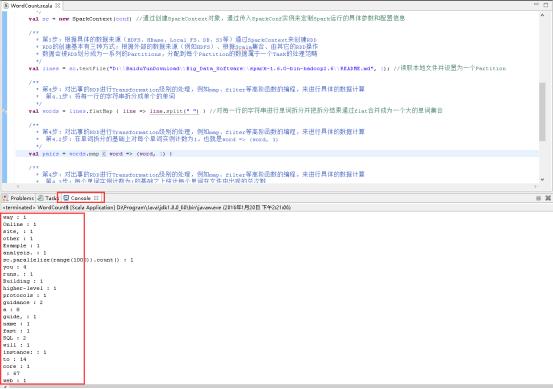
45、看见这样的结果,就代表成功了。
以上是关于CentOS7.5之spark2.3.0安装的主要内容,如果未能解决你的问题,请参考以下文章