Deep Learning
Posted bairuiworld
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Deep Learning相关的知识,希望对你有一定的参考价值。
Deep Learning
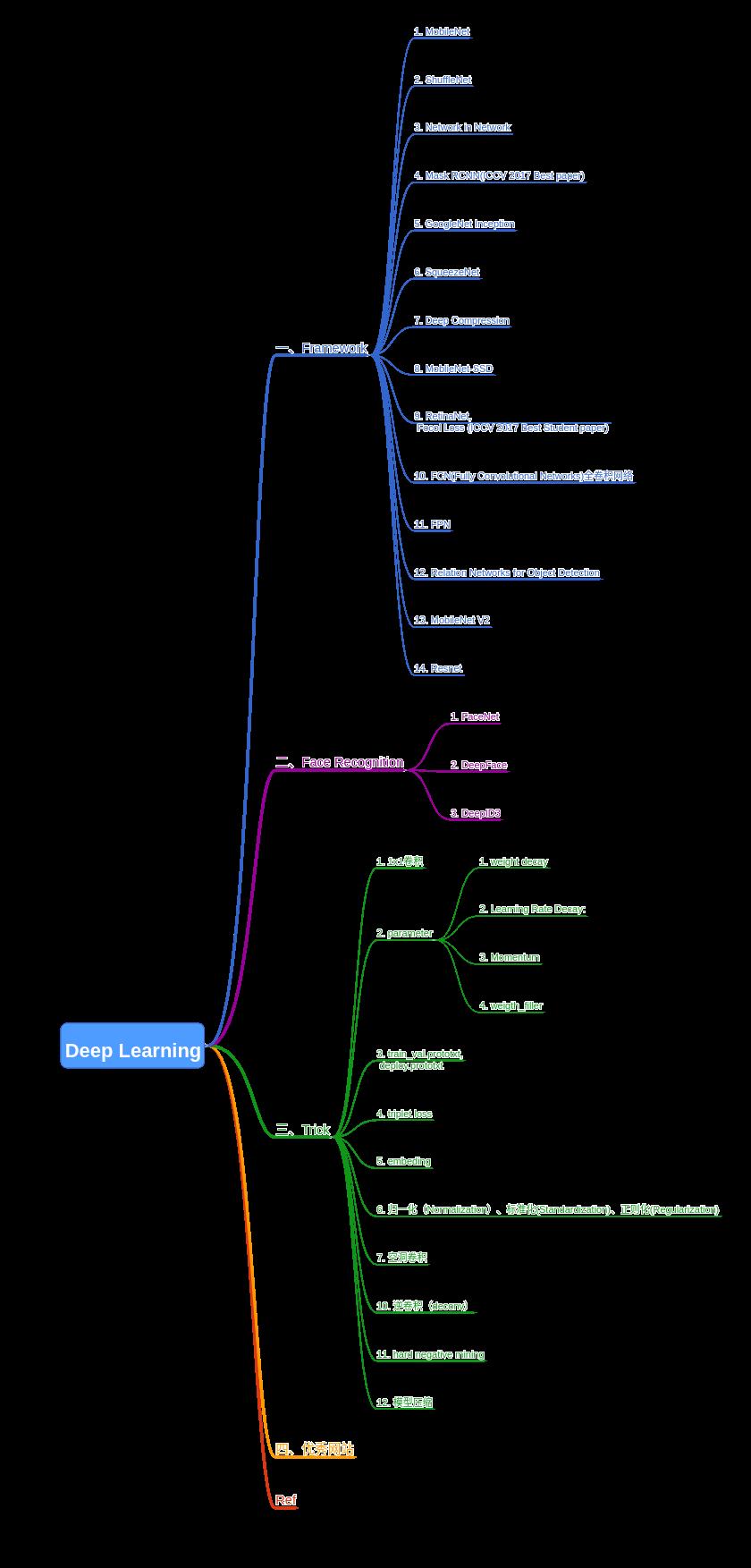
一、Framework
1. MobileNet
将标准卷积拆分成两部,第一次卷积不进行channel间卷积(逐层卷积:depthwise convolution),即一个输入channel对应一个卷积滤波器;第二次只进行channel间卷积,即使用1x1卷积核。如图,原来的参数个数为 ,现在变为
,现在变为 ,参数个数整体减少N倍。
,参数个数整体减少N倍。

2. ShuffleNet
以前Inception网络group时,各个通道之间都是独立的,现在将各个通道打乱,增强通道间的交互信息。

ShuffleNet使用类似MobileNet的网络,就是增加了通道间的shuffle,去掉了ReLU。先1x1 pointwise conv, 然后shuffle, 再进行3x3 Detpthwise conv,作者说1x1, 3x3的顺序不重要。

实验结果:

相对于MobileNet,ShuffleNet的前向计算量不仅有效地得到了减少,而且分类错误率也有明显提升,验证了网络的可行性。
3. Network in Network
利用 Mlpconv 和 全局平均 pooling 建立了 Network in Network 网络结构。
Mlpconv: mlpcon 指的是: multilayer perceptron + convolution;

过程如下:
假设上面的第三个图中的输入为2*(4 4), 输出为2 * (33)时:
- 第一层的卷积核大小为2*2, 步长为1, 输入为2*(4 *4), 输出为 4*(3*3);
- 第二层的卷积核大小为1*1, 步长为1, 输入为4*(3 *3), 输出为 3*(3*3);
- 第三层的卷积核大小为1*1, 步长为1, 输入为3*(3 *3), 输出为 2*(3*3);
后面两层的卷积核大小为1x1,意味着每个卷积核只进行不同通道间的累加,而不进行同一个Feature Map上的卷积,保证Feature Map大小不变。整个mlpconv的效果就相当于使用了第一层的卷积核大小,第三层的通道数的一层卷积。但好处是复杂的结构增加了网络的非线性,使网络表征非线性能力增强。文中也说明了 NIN比 maxout networks 更 non-linearity;

全局平均池化:即每个feature map平均池化成一个值,如果有m个通道,就会生成一个m维的向量(传统方法使用全连接层生成固定维度向量,但全连接层需要参数多,容易过拟合,dropout可以缓解这个问题),然后使用softmax分类:

http://blog.csdn.net/diamonjoy_zone/article/details/70229148
https://www.cnblogs.com/yinheyi/p/6978223.html
4. Mask RCNN(ICCV 2017 Best paper)

原来的分割都是对整张图片的所有目标进行多分类,输入一张图片,会输出一张整体的mask,如下图左边。
作者现在用分类框来辅导分割,那么现在在分类框内做分割只需要做二分类,减少其它的干扰。同时,作者将分类工作与分割工作进行解耦,分类和分割是两个过程,先分类,在对每个分类框进行分割。如下图左边所示。

http://blog.csdn.net/linolzhang/article/details/71774168
5. GoogleNet Inception
使用了1×1,3×3,5×5的卷积核,又因为pooling也是CNN成功的原因之一,所以把pooling也算到了里面,然后将结果在拼起来。

发展:
Inception V1, V2, V3, V4
Inception-Resnet V1, V2
Inception V1——构建了1x1、3x3、5x5的 conv 和3x3的 pooling 的分支网络,同时使用 MLPConv 和全局平均池化,扩宽卷积层网络宽度,增加了网络对尺度的适应性;
Inception V2——提出了 Batch Normalization,代替 Dropout 和 LRN,其正则化的效果让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提高,同时学习 VGG 使用两个3´3的卷积核代替5´5的卷积核,在降低参数量同时提高网络学习能力;
Inception V3——引入了 Factorization,将一个较大的二维卷积拆成两个较小的一维卷积,比如将3x3卷积拆成1x3卷积和3x1卷积,一方面节约了大量参数,加速运算并减轻了过拟合,同时增加了一层非线性扩展模型表达能力,除了在 Inception Module 中使用分支,还在分支中使用了分支(Network In Network In Network);
Inception V4——设计了一个更深更优化的 Inception v4 模型。另外研究了 Inception Module 结合 ResNet,inception-resnet-v1, inception-resnet-v2 可以极大地加速训练,同时极大提升性能。而Inception v4可以达到和inception-resnet-v2 相媲美的性能。
http://blog.csdn.net/stdcoutzyx/article/details/51052847
http://blog.csdn.net/yuanchheneducn/article/details/53045551
6. SqueezeNet
作者提出了一个类似inception的网络单元结构,取名为fire module。使用这个模块代替原始的3x3卷积,一个fire module 包含一个squeeze 卷积层(只包含1x1卷积核)和一个expand卷积层(包含1x1和3x3卷积核)。其中,squeeze层借鉴了inception的思想,利用1x1卷积核来降低输入到expand层中3x3卷积核的输入通道数。

相比传统的压缩方法,SqueezeNet能在保证精度不损(甚至略有提升)的情况下,达到最大的压缩率,将原始AlexNet从240MB压缩至4.8MB,而结合Deep Compression后更能达到0.47MB,完全满足了移动端的部署和低带宽网络的传输。

7. Deep Compression
《Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding》
进行权重文件压缩:

1、Pruning(权值剪枝)
2、Quantization (权值量化) codebook
3、Huffman encoding(霍夫曼编码)
http://blog.csdn.net/QcloudCommunity/article/details/77719498
8. MoblieNet-SSD
SSD的MobileNet实现,caffemodel大小只有22.1M左右。
9. RetinaNet, Focol Loss (ICCV 2017 Best Student paper)
深度学习目标检测主要有两种方法:
- 两步检测,如RCNN、Faster RCNN,这样的检测效果好,但速度慢
- 一步检测,如YOLO、SSD,这样的检测速度快,但效果稍差。
作者改进了损失函数,使得在效果、速度上都取得了较好的效果。
二分类问题的原始交叉熵损失函数:

作者做了两方面改进,一个是针对样本不均衡的问题,如果一个类别样本少,它的权重就要大一些。作者用 来调节样本少的类,用一类的调节参数即为
来调节样本少的类,用一类的调节参数即为 。
。

作者另一方面在分类错误度上进行惩罚,分类偏离越大,惩罚的权重也应该越大。

虽然cross_entroy在设计上对分类偏离越大的样本给予越大的损失,但作者想加入一个调节因子可以加大调节力度。如果分类概率为0.2, 那么结果为 ,可以看见当分类正确概率越低,前面的调节因子可以起到加大这种loss的作用;当分类正确概率接近1的时候,前面的调节因子就会很小,导致最后的损失函数变小,这正是想要的结果:惩罚大的分类误差。
,可以看见当分类正确概率越低,前面的调节因子可以起到加大这种loss的作用;当分类正确概率接近1的时候,前面的调节因子就会很小,导致最后的损失函数变小,这正是想要的结果:惩罚大的分类误差。
最后,作者结合两者,给出了最后的损失函数形式:

tensorflow实现:
- import tensorflow as tf
- from tensorflow.python.ops import array_ops
- def focal_loss(prediction_tensor, target_tensor, weights=None, alpha=0.25, gamma=2):
- r"""Compute focal loss for predictions.
- Multi-labels Focal loss formula:
- FL = -alpha * (z-p)^gamma * log(p) -(1-alpha) * p^gamma * log(1-p)
- ,which alpha = 0.25, gamma = 2, p = sigmoid(x), z = target_tensor.
- Args:
- prediction_tensor: A float tensor of shape [batch_size, num_anchors,
- num_classes] representing the predicted logits for each class
- target_tensor: A float tensor of shape [batch_size, num_anchors,
- num_classes] representing one-hot encoded classification targets
- weights: A float tensor of shape [batch_size, num_anchors]
- alpha: A scalar tensor for focal loss alpha hyper-parameter
- gamma: A scalar tensor for focal loss gamma hyper-parameter
- Returns:
- loss: A (scalar) tensor representing the value of the loss function
- """
- sigmoid_p = tf.nn.sigmoid(prediction_tensor)
- zeros = array_ops.zeros_like(sigmoid_p, dtype=sigmoid_p.dtype)
-
- # For poitive prediction, only need consider front part loss, back part is 0;
- # target_tensor > zeros <=> z=1, so poitive coefficient = z - p.
- pos_p_sub = array_ops.where(target_tensor > zeros, target_tensor - sigmoid_p, zeros)
-
- # For negative prediction, only need consider back part loss, front part is 0;
- # target_tensor > zeros <=> z=1, so negative coefficient = 0.
- neg_p_sub = array_ops.where(target_tensor > zeros, zeros, sigmoid_p)
- per_entry_cross_ent = - alpha * (pos_p_sub ** gamma) * tf.log(tf.clip_by_value(sigmoid_p, 1e-8, 1.0)) \\