仿9GAG制作过程
Posted 懒星人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了仿9GAG制作过程相关的知识,希望对你有一定的参考价值。
有话要说:
这次准备讲述用python爬虫以及将爬来的数据存到mysql数据库的过程,爬的是煎蛋网的无聊图。
成果:
准备:
- 下载了python3.7并配置好了环境变量
- 下载了PyCharm作为开发python的IDE
- 安装了MySQL客户端以及服务端
- 安装了Navicat客户端
- 通过pip命令下载安装beautifulsoup,selenium以及pymysql模块,pip命令如下:
pip install beautifulsoup4
pip install selenium
pip install pymysql
观察“无聊图”网页源码:
先上部分源码:
1 <li id="comment-3838846"> 2 <div> 3 <div class="row"> 4 <div class="author"><strong 5 title="防伪码:fc33b015c2b4d50cd1a23007810b09f049f1407d" class="orange-name">猴子</strong> <br> 6 <small><a href="#footer" title="@回复" 7 onclick="document.getElementById(\'comment\').value += '@<a href="//jandan.net/pic/page-185#comment-3838846">猴子</a>: '">@4 days ago</a></span></small> 8 </div> 9 <div class="text"><span class="righttext"><a href="//jandan.net/pic/page-185#comment-3838846">3838846</a></span><p>这个盖字是怎么翻译出来的<br /> 10 <img src="//img.jandan.net/img/blank.gif" onload="jandan_load_img(this)" /><span class="img-hash">Ly93dzMuc2luYWltZy5jbi9tdzYwMC8wMDZYTkVZN2d5MWZydm84MHg0Mm1qMzFrdzIzdmF6cS5qcGc=</span></p> 11 </div> 12 <div class="jandan-vote"> 13 <span class="comment-report-c"> 14 <a title="投诉" href="javascript:;" class="comment-report" data-id="3838846">[投诉]</a> 15 </span> 16 <span class="tucao-like-container"> 17 <a title="圈圈/支持" href="javascript:;" class="comment-like like" data-id="3838846" data-type="pos">OO</a> [<span>52</span>] 18 </span> 19 <span class="tucao-unlike-container"> 20 <a title="叉叉/反对" href="javascript:;" class="comment-unlike unlike" data-id="3838846" data-type="neg">XX</a> [<span>13</span>] 21 22 <a href="javascript:;" class="tucao-btn" data-id="3838846"> 吐槽 [16] </a> 23 </span> 24 </div> 25 </div> 26 </div> 27 </li>
发现在源码里边图片链接并没有直接显示出来,而是在js中加载的。因此,不能用普通的爬虫方式来获取图片链接。
看了许多博客,最终决定采用Python3+BeautifulSoup+selenium的方式来抓取。
selenium用来获取网页链接数据,BeautifulSoup用来解析获取的网页源码。
selenium相当于一个小型浏览器,可以直接获取完整的网页源码,获取之后的网页源码如下所示:
1 <li id="comment-3838846"> 2 <div> 3 <div class="row"> 4 <div class="author"><strong title="防伪码:fc33b015c2b4d50cd1a23007810b09f049f1407d" class="orange-name">猴子</strong> <br> 5 <small><a href="#footer" title="@回复" onclick="document.getElementById(\'comment\').value += \'@<a href="//jandan.net/pic/page-185#comment-3838846">猴子</a>: \'">@4 days ago</a></small> 6 </div> 7 <div class="text"><span class="righttext"><a href="//jandan.net/pic/page-185#comment-3838846">3838846</a></span><p>这个盖字是怎么翻译出来的<br> 8 <a href="//ww3.sinaimg.cn/large/006XNEY7gy1frvo80x42mj31kw23vazq.jpg" target="_blank" class="view_img_link">[查看原图]</a><br><img src="http://ww3.sinaimg.cn/mw600/006XNEY7gy1frvo80x42mj31kw23vazq.jpg" style="max-width: 100%; max-height: 450px;"></p> 9 </div> 10 <div class="jandan-vote"> 11 <span class="comment-report-c"> 12 <a title="投诉" href="javascript:;" class="comment-report" data-id="3838846">[投诉]</a> 13 </span> 14 <span class="tucao-like-container"> 15 <a title="圈圈/支持" href="javascript:;" class="comment-like like" data-id="3838846" data-type="pos">OO</a> [<span>52</span>] 16 </span> 17 <span class="tucao-unlike-container"> 18 <a title="叉叉/反对" href="javascript:;" class="comment-unlike unlike" data-id="3838846" data-type="neg">XX</a> [<span>13</span>] 19 20 <a href="javascript:;" class="tucao-btn" data-id="3838846"> 吐槽 [16] </a> 21 </span> 22 </div> 23 </div> 24 </div> 25 </li>
注意到,class="row"的div是我们需要的,并且不包含我们不需要的部分,因此就可以通过class="row"来获取需要的数据。
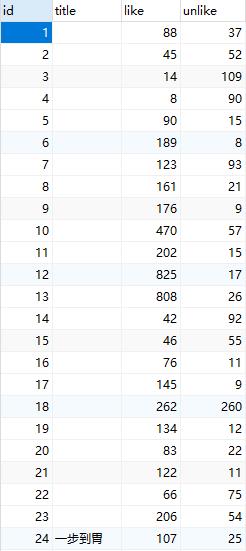
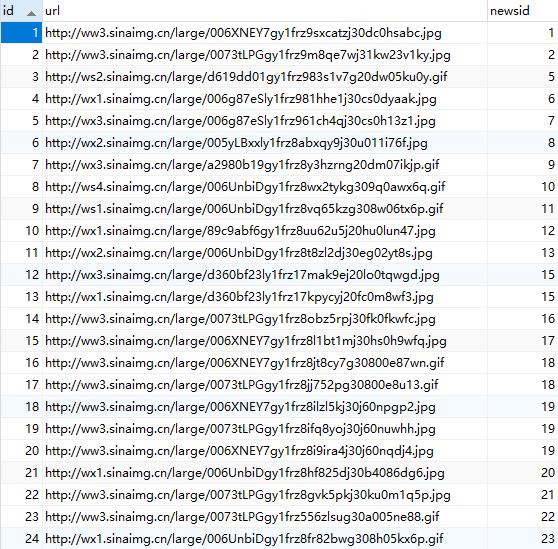
又因为一条段子包含的信息有:一个标题(有些有有些没有),若干张图片,点赞数,点踩数。因此设计数据库表如下:
数据库表设计:
因为以上的信息,故设计了两张表。
一张表用来存放段子的基本信息,包括主键、标题、点赞数、点踩数;
另一张表用来存放段子包含的图片链接,包括主键、图片链接、段子主键。
用段子主键来相互关联,主要SQL语句如下:
CREATE TABLE `news` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT \'段子标识\', `title` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT \'段子标题\', `like` int(11) DEFAULT NULL COMMENT \'点赞数\', `unlike` int(11) DEFAULT NULL COMMENT \'点踩数\', PRIMARY KEY (`id`) ) CREATE TABLE `news_pics` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT \'图片标识\', `url` varchar(255) DEFAULT NULL COMMENT \'图片链接\', `newsid` int(11) NOT NULL COMMENT \'段子标识\', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=319 DEFAULT CHARSET=utf8;
主体部分:
接着,阅读了Python爬取煎蛋妹子图以及python+selenium+PhantomJS爬取网页动态加载内容之后,实现了利用python进行抓取数据解析数据的过程,先上代码:
1 # coding=utf-8 2 import re 3 import pymysql 4 from bs4 import BeautifulSoup 5 from selenium import webdriver 6 7 base_url = "http://jandan.net/pic/page-" 8 driver = webdriver.PhantomJS() 9 10 items = [] 11 urls = ["http://jandan.net/pic/page-{}#comments".format(str(i)) for i in range(50689352, 50689355)] 12 13 db = pymysql.connect(host="localhost", user="root", password="root", db="imitating9gag", charset="utf8") 14 cursor = db.cursor() 15 16 sql_news = \'\'\'INSERT INTO `imitating9gag`.`news` (`id`, `title`, `like`, `unlike`) VALUES (\'%d\', \'%s\', \'%d\', \'%d\')\'\'\' 17 sql_pics = \'\'\'INSERT INTO `imitating9gag`.`news_pics` (`id`, `url`, `newsid`) VALUES (\'%d\', \'%s\', \'%d\')\'\'\' 18 19 if __name__ == "__main__": 20 for url in urls: 21 driver.get(url) 22 data = driver.page_source 23 soup = BeautifulSoup(data, "html.parser") 24 divs = soup.findAll(\'div\', attrs={\'class\': \'row\'}) 25 26 # 遍历所有的项 27 for div in divs: 28 # \'title\'代表的是文字,\'urls\'代表的是图片的集合,\'like\'代表的是点赞数,\'unlike\'代表的是踩 29 item = {} 30 urls = [] 31 32 item[\'like\'] = div.find(\'span\', attrs={\'class\': \'tucao-like-container\'}).find(\'span\').string 33 item[\'unlike\'] = div.find(\'span\', attrs={\'class\': \'tucao-unlike-container\'}).find(\'span\').string 34 35 paragraph = div.find(attrs={\'class\': \'text\'}).find("p") 36 37 # 获取所有的图片链接 38 links = paragraph.select("a.view_img_link") 39 for link in links: 40 urls.append("http:" + link.get(\'href\')) 41 item[\'urls\'] = urls 42 43 # 获取最开始的文字部分 44 title = re.search(\'<p>[\\s\\S]+?<a\', str(paragraph)) 45 46 if title is not None and title.group()[3:-8] is not None \\ 47 and title.group()[3:-8].find(\'view_img_link\') == -1: 48 item[\'title\'] = title.group()[3:-8] 49 else: 50 item[\'title\'] = "" 51 52 items.append(item) 53 54 i = 1 55 j = 1 56 try: 57 for item in items: 58 # 插入新闻数据 59 cursor.execute(sql_news % (i, item[\'title\'], int(item[\'like\']), int(item[\'unlike\']))) 60 # 插入图片数据 61 for tempUrl in item[\'urls\']: 62 cursor.execute(sql_pics % (j, tempUrl, i)) 63 j = j+1 64 i = i+1 65 db.commit() 66 except Exception as e: 67 print(e) 68 print(item) 69 db.rollback() 70 db.close()
注意点:
- 在用pymysql的时候,如果插入的数据有中文,则在connect的时候需要设置charset,见13行
- 44行在获取title的时候用了正则表达式,最开始直接用[.+]并不会匹配换行符,因此换成了[\\s\\S],\\s匹配空白符,\\S匹配非空白符,因此可以匹配所有的字符。
- 最开始准备使用MySQLdb来操作数据库,但是python3不支持,于是换成了pymysql来操作数据库
至此,后台数据已经获取完成,接下来是后台接口的开发,准备采用Java的Servlet来实现后台接口的开发。
反思:
- 对python语法掌握的不足,一些简单的语法需要通过查询才知道怎么用,需要找一个时间完整的学习一边python语法
- 对正则表达式的使用不熟练,以后需要加强对正则表达式使用的练习
- 本次代码仅作学习用,没有进行优化,也没有考虑到一些特殊的情况
- 通过这次学习到了python语法+爬虫基本步骤+数据库的整体设计+解析网页源码
- 如果title中有表情,保存数据库会报错,该问题正在解决
大家如果有什么疑问或者建议可以通过评论或者邮件的方式联系我,欢迎大家的评论~
以上是关于仿9GAG制作过程的主要内容,如果未能解决你的问题,请参考以下文章