《数据结构》_8跳表和散列表
Posted WittPeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《数据结构》_8跳表和散列表相关的知识,希望对你有一定的参考价值。
跳表
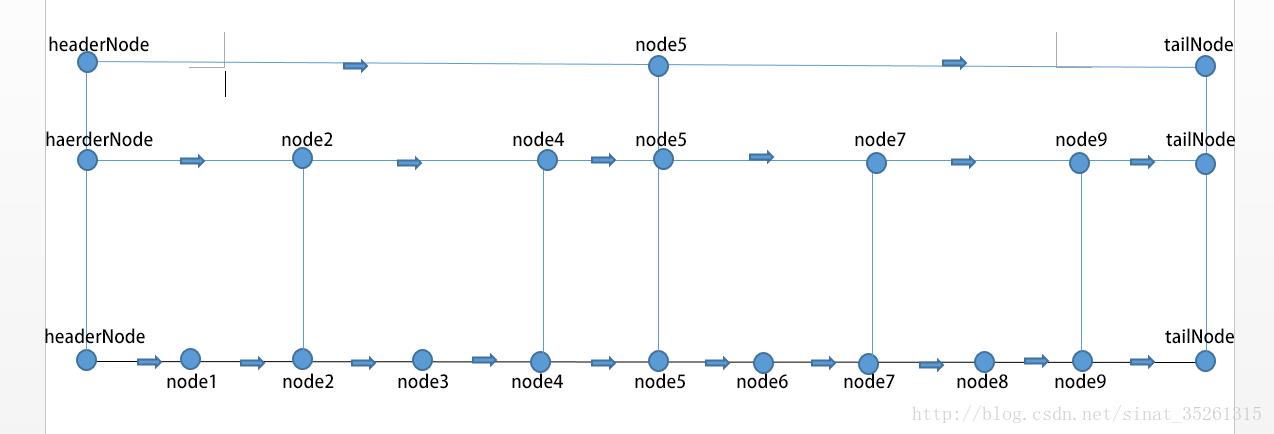
跳表是一个包含n个元素的单链表,且满足以下条件:
(1)在单链表的结点中,每隔2i个元素,就增加一个i级指针,0≤i≤⌈log2n⌉;
(2)其头节点为Head,是一个大小为⌈log2n⌉的一维指针数组,里面只存放指向i级的第一个级指针,0≤i≤⌈log2n⌉,不存放实际数据元素,它和同i级的指针构成一个存放指针的i级单链表;
(3)其尾结点为Tail,是一个可以存放实际数据元素的指针,通常该元素值设为一个较大的数值,作为查找退出的哨兵。
可以借鉴博客https://blog.csdn.net/sinat_35261315/article/details/62890796
等以后有时间了,我自己写一下。
散列表
散列函数:一种可以在元素关键字的值和该元素的存储位置之间建立映射的函数,即Loc=HF(Key)。
散列表:是一段连续的内存空间,考虑是连续的有限内存空间,使用顺序存储结构来实现。
冲突:不同关键字经过散列函数映射到相同地址的现象。关键字称为同义词。
散列表基本操作的实现
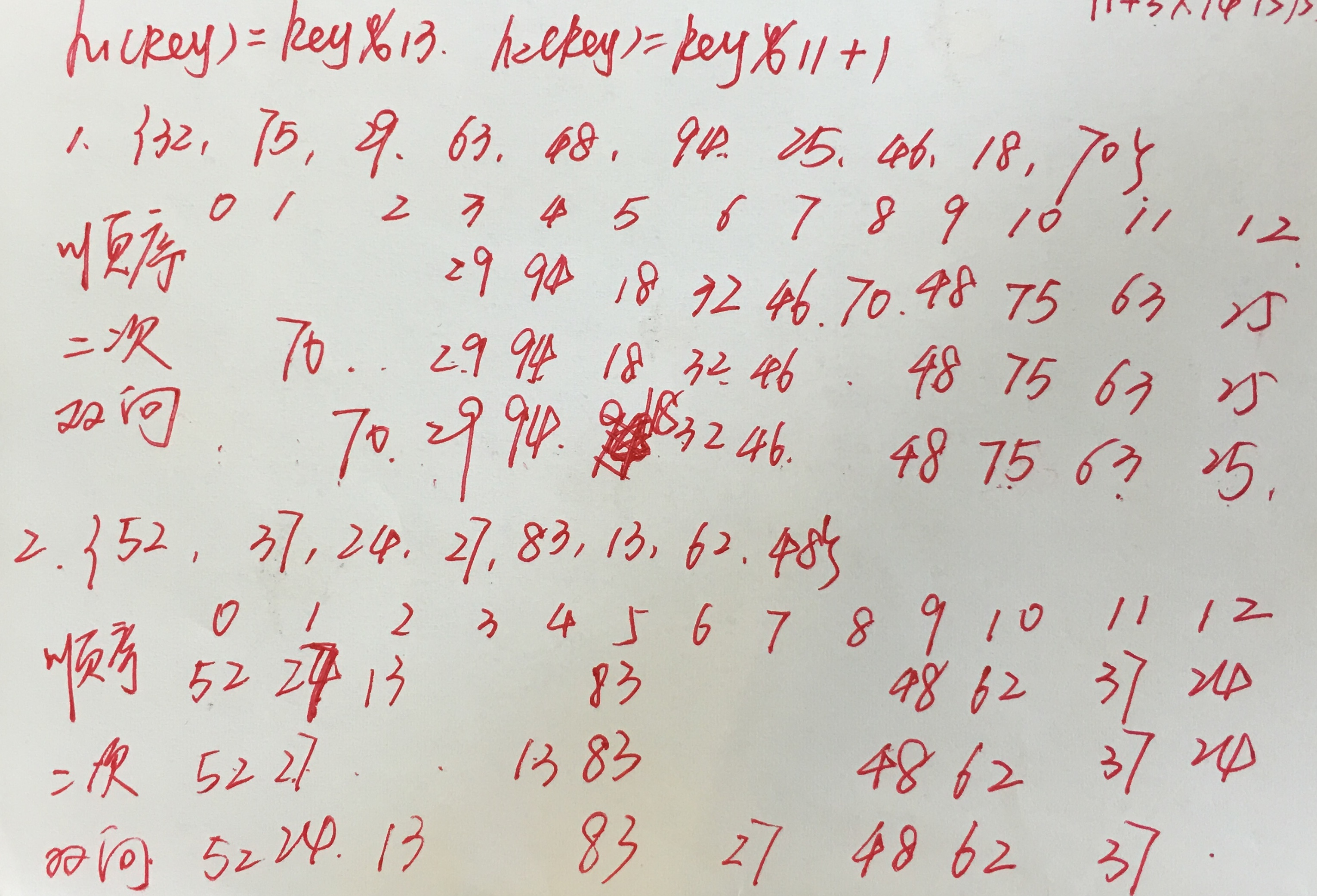
1.开放地址散列方法
Locj=(HF(Key)+dj)%m
顺序探测法:dj =1,2,3,···,m-1
二次探测法:dj =1的平方,- 1的平方,2的平方,- 2的平方,···
伪随机探测法
双散列法:dj =j*HF2(Key)
2.链表散列方法
链表散列方法的基本思想是:当散列函数产生冲突时,通过一个单链表把具有相同散列地址的元素链接在一起,长度为m的散列表可以有m个这样的单链表。假设这m个单链表的头指针都存储在指针数组中,记为htHead[i],0≤i≤m-1。
以上是关于《数据结构》_8跳表和散列表的主要内容,如果未能解决你的问题,请参考以下文章