决策树剪枝问题
Posted 板弓子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树剪枝问题相关的知识,希望对你有一定的参考价值。
决策树的剪枝是将生成的树进行简化,以避免过拟合。
《统计学习方法》上一个简单的方式是加入正则项a|T|,其中|T|为树的叶节点个数。
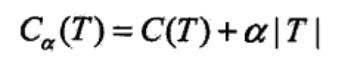
其中C(T)为生成的决策树在训练集上的经验熵,经验熵越大,表明叶节点上的数据标记越不纯,分类效果越差。有了这个标准,拿到一颗生成好的树,我们就递归的判断一组叶节点,看它回缩前和回缩后的代价函数变化。如果代价函数回缩后变小,那么久回缩这组叶节点。当所有叶节点都进行过回缩测试后,剪枝也就完成了。
西瓜书(《机器学习》周志华)上给出了另外一种剪枝策略,即“留出法”,预留一部分数据用作“验证集”以进行性能评估。预留法以决策树在验证集上预测精度为是否剪枝的标准,执行顺序上分为预剪枝和后剪枝。预剪枝是边生成树边剪枝,训练速度快,但容易欠拟合;后剪枝是完全生成后再从底向上剪枝,得出的模型泛化性能好,但训练时间需要更久。
《统计学习方法》一书上还介绍CART算法的剪枝算法,个人觉得是训练集上剪枝与后剪枝的结合。运算量比较大,但拟合效果应该是最好的。
CART剪枝应该是对验证集不同的适应方法(对比后剪枝),好处应该是在适应验证集的基础上保留对训练集的适应。勉强说,后剪枝和CART的剪枝比起来,也是局部和全局的关系。
在迭代求T1, T2...的过程中,alpha值不断变大,也就意味着对树的简化越来越多,对训练集的拟合程度越来越差;而通过验证集从这一系列树中选择一颗,也就是通过验证集来选择对生成树的简化程度,而选择的同时也尽可能保证了简化后的树对训练集的拟合程度。
而后剪枝这种剪枝方法就比较暴力了,直接在生成树的基础上从底向上收,唯一的依据是生成树对验证集的预测准确度。这样的暴力剪枝虽然也减低了模型的复杂度,但没有考虑剪枝后的树对训练集的适应情况,对训练集的拟合程度下降的比较厉害。
以上是关于决策树剪枝问题的主要内容,如果未能解决你的问题,请参考以下文章