回归预测数值型数据
Posted yueguan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了回归预测数值型数据相关的知识,希望对你有一定的参考价值。
一.线性回归
回归的目的是预测数值型的目标值。最直接的办法是依据输入写成一个目标值的计算公式。
回归方程:y=a_1*x_1+a_2*x_2
其中的 a1 和 a2 称作回归系数,求这些回归系数的过程就是回归。一旦有了这些回归系数,再给定输入,做预测就非常容易了,具体的做法是用回归系数乘以输入值,再将结果全部加在一起,就得到了预测值
应当怎样从一大堆数据里求出回归方程呢?假定输入数据存放在矩阵 X 中,而回归系数存放在向量 W 中,那么对于给定的数据 x1,预测结果将会通过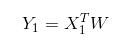
给出。现在的问题是,有一些 x 个对应的 Y,怎样才能找到 w 呢?一个常用的方法就是找出误差最小的 w。这里的误差是指预测 y 值和真实 y 值之间的差值,使用该差值的简单累加将使得正差值和发差值相互抵消,所以使用平方误差公式: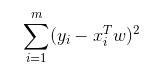
用矩阵表示为: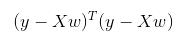
如果对 w 求导,得到: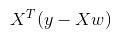
令其等于零,解出 w 如下: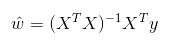
w 上方的小标记表示,这是当前可以估计出的 w 的最优解。
值得注意的是,上述公式中包含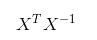 也就是需要对矩阵求逆,因此这个方程只在逆矩阵存在的时候适用(代码中可以用伪逆矩阵)。上述的最佳 w 求解的统计学中的常见问题,除了矩阵方法外还有其他方法可以解决。该方法也称为 OLS,即普通最小二乘法(ordinary least squares)。
也就是需要对矩阵求逆,因此这个方程只在逆矩阵存在的时候适用(代码中可以用伪逆矩阵)。上述的最佳 w 求解的统计学中的常见问题,除了矩阵方法外还有其他方法可以解决。该方法也称为 OLS,即普通最小二乘法(ordinary least squares)。
利用一个普通数据集画出散点图及最佳拟合直线如下:
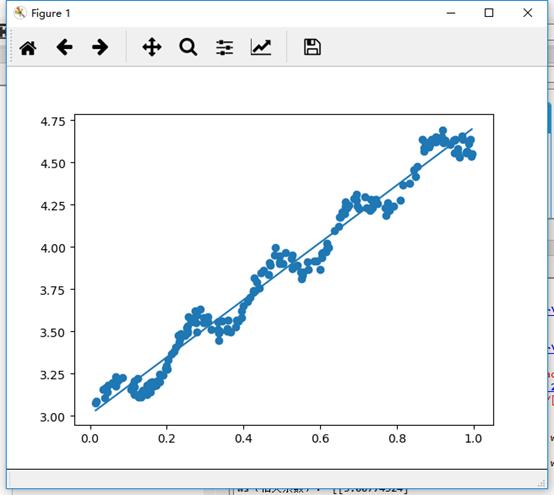
from numpy import * import numpy as np import operator from os import listdir import matplotlib.pyplot as plt def loadDataSet(filename): numFeat = len(open(filename).readline().split("\\t")) -1 dataMat = []; labelMat = [] fr = open(filename) for line in fr.readlines(): lineArr = [] curLine = line.strip().split("\\t") for i in range(numFeat): lineArr.append(float(curLine[i])) dataMat.append(lineArr) labelMat.append(float(curLine[-1])) return dataMat,labelMat #计算最佳拟合曲线 def standRegress(xArr,yArr): xMat = mat(xArr); yMat = mat(yArr).T #.T代表转置矩阵 xTx = xMat.T * xMat if linalg.det(xTx) ==0.0: #linalg.det(xTx) 计算行列式的值 print ("This matrix is singular , cannot do inverse") return ws = xTx.I * (xMat.T * yMat) return ws #测试上边的函数 xArr,yArr = loadDataSet("ex0.txt") ws = standRegress(xArr, yArr) print ("ws(相关系数):",ws) #ws 存放的就是回归系数 #画图展示 def show(): import matplotlib.pyplot as plt xMat = mat(xArr); yMat = mat(yArr) yHat = xMat*ws fig = plt.figure() #创建绘图对象 ax = fig.add_subplot(111) #111表示将画布划分为1行2列选择使用从上到下第一块 #scatter绘制散点图 ax.scatter(xMat[:,1].flatten().A[0],yMat.T[:,0].flatten().A[0]) #复制,排序 xCopy =xMat.copy() xCopy.sort(0) yHat = xCopy * ws #plot画线 ax.plot(xCopy[:,1],yHat) plt.show() yHat = mat(xArr) * ws #yHat = xMat * ws print ("相关性:",corrcoef(yHat.T,mat(yArr))) show()
二.局部加权线性回归
线性回归的一个问题是有可能出现欠拟合现象,因为它求的是具有最小均方误差的无偏估计。显而易见,如果模型欠拟合将不能取得最好的预测效果,所以有些方法允许在估计中引入一些偏差,从而降低预测的均方误差。
其中一个方法是局部加权线性回归(Locally Weighted Linear Regression,LWLR)。在该算法中,我们给待预测点附近的每个点赋予一定的权重;然后与8.1节类似,在这个子集上基于最小均方差来进行普通的回归。与 kNN 一样,这种算法每次均需要事先取出对应的数据子集。该算法解出回归系数 w 的形式如下: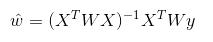
其中 w 是一个矩阵,用来给每个数据点赋予权重。
LWLR 使用“核”来对附近的点赋予更高的权重。核的类型可以自由选择,最常用的核就是高斯核,其对应的权重如下: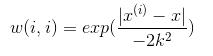
这样就构建了一个只含对角元素的权重矩阵 w,并且点 x 与 x(i) 越近,w(i,i) 将会越大。上述公式包含一个需要用户指定的参数 k,它决定了对附近的点赋予多大的权重,这也就是使用 LWLR 时唯一需要考虑的参数
下图给出了k在三种不同取值下的结果图:
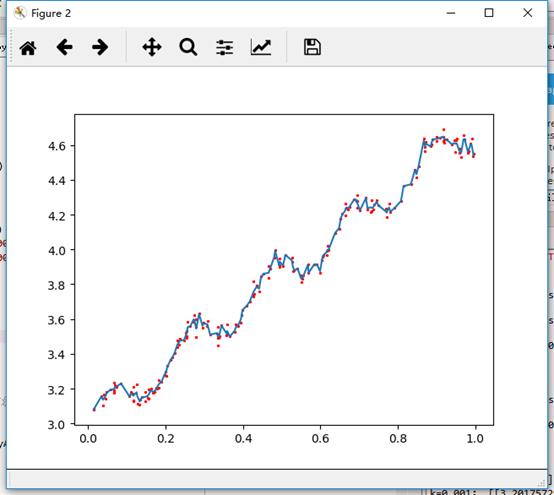
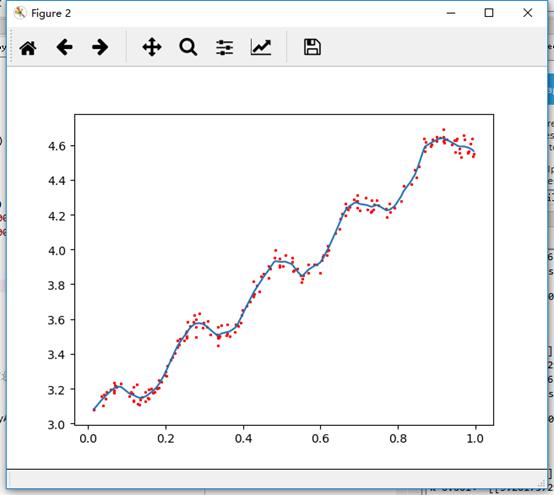
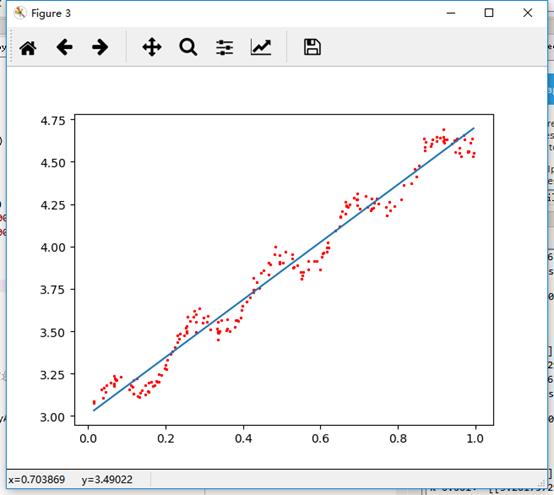
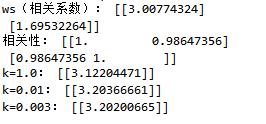
k = 1.0 时的模型效果与最小二乘法差不多,k=0.01时该模型可以挖出数据的潜在规律,而 k=0.003时则考虑了太多的噪声,进而导致了过拟合现象。
def lwlr(testPoint,xArr,yArr,k=1.0): xMat = mat(xArr); yMat = mat(yArr).T m = shape(xMat)[0] weights = mat(eye((m))) #产生对角线矩阵 for j in range(m): diffMat = testPoint - xMat[j,:] #更新权重值,以指数级递减 weights[j,j] = exp(diffMat * diffMat.T /(-2.0*k**2)) xTx = xMat.T * (weights * xMat) if linalg.det(xTx) == 0.0: print ("this matrix is singular,cannot do inverse") return ws = xTx.I * (xMat.T * (weights * yMat)) return testPoint * ws def lwlrTest(testArr,xArr,yArr,k=1.0): m = shape(testArr)[0] yHat = zeros(m) for i in range(m): yHat[i] =lwlr(testArr[i],xArr,yArr,k) return yHat xArr,yArr = loadDataSet(\'ex0.txt\') print ("k=1.0:",lwlr(xArr[0],xArr,yArr,1.0)) print ("k=0.01:",lwlr(xArr[0],xArr,yArr,0.01)) print ("k=0.003:",lwlr(xArr[0],xArr,yArr,0.003)) #画图 def showlwlr(): yHat = lwlrTest(xArr, xArr, yArr, 0.01) xMat = mat(xArr) srtInd = xMat[:,1].argsort(0) xSort = xMat[srtInd][:,0,:] import matplotlib.pyplot as plt fig = plt.figure() #创建绘图对象 ax = fig.add_subplot(111) #111表示将画布划分为1行2列选择使用从上到下第一块 ax.plot(xSort[:,1],yHat[srtInd]) #scatter绘制散点图 ax.scatter(xMat[:,1].flatten().A[0],mat(yArr).T[:,0].flatten().A[0],s=2,c=\'red\') plt.show() show()
三.使用回归算法预测鲍鱼的年龄
“abalone.txt”数据集部分如下:
用函数ressError()计算出预测误差,可以看出使用较小的核将得到较低的误差,但核过小也会造成过度拟合。
abX, abY = loadDataSet(\'abalone.txt\') yHat01 = lwlrTest(abX[0:99], abX[0:99], abY[0:99], 0.1) yHat1 = lwlrTest(abX[0:99], abX[0:99], abY[0:99], 1) yHat10 = lwlrTest(abX[0:99], abX[0:99], abY[0:99], 10) print(rssError(abY[0:99], yHat01.T)) # 56.7886874305 print(rssError(abY[0:99], yHat1.T)) # 429.89056187 print(rssError(abY[0:99], yHat10.T)) # 549.118170883 ws = standRegres(abX[0:99], abY[0:99]) yHat = np.mat(abX[100:199]) * ws print(rssError(abY[100:199], yHat.T.A)) # 518.636315325
下图分别是核为0.1、1、10及简单线性回归时的误差,可以看出简单线性回归达到了与局部加权线性回归类似的效果,也表明在未知数据上比较才能选取到最佳模型。

此篇展示了如何使用局部加权线性回归来构建模型,可以得到比普通线性回归更好的效果。局部加权线性回归的问题在于,每次必须在整个数据集上运行。也就是说为了做出预测,必须保存所有的训练数据。
以上是关于回归预测数值型数据的主要内容,如果未能解决你的问题,请参考以下文章