中国大学排名爬虫
Posted 疼你&心依旧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中国大学排名爬虫相关的知识,希望对你有一定的参考价值。
-
功能描述:
-
输出:大学排名信息的屏幕输出(排名,大学名称,总分)
-
技术路线:requests-bs4
-
定向爬虫:仅对输入的URL链接进行爬取,不扩展爬取。
-
程序的程序设计:
-
步骤1:从网络上获取大学排名网页内容(gethtmlText())
-
步骤2:提取网页内容中信息到合适的数据结构(fillUnivList())
-
步骤3:利用数据结构展示并输出结果(printUnivList())
格式化输出:
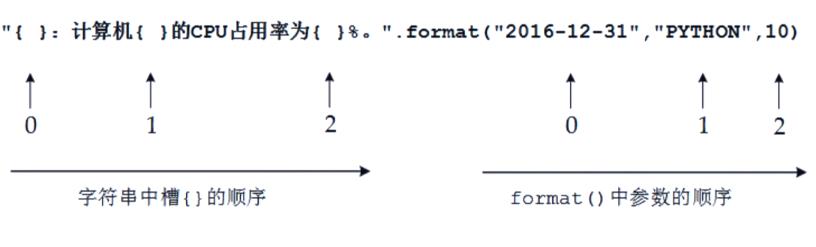
-
爬虫代码:
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 5 def getHTMLText(url): 6 try: 7 r = requests.get(url, timeout = 30) 8 r.raise_for_status() 9 r.encoding = r.apparent_encoding 10 return r.text 11 except: 12 return "" 13 14 def fillUnivList(ulist, html): 15 soup = BeautifulSoup(html, "html.parser") 16 for tr in soup.find(\'tbody\').children: 17 if isinstance(tr, bs4.element.Tag): 18 tds = tr(\'td\') 19 ulist.append([tds[0].string, tds[1].string, tds[2].string]) 20 21 def printUnivList(ulist, num): 22 print("{:^10}\\t{:^6}\\t{:^10}".format("排名", "学校名称", "总分")) 23 for i in range(num): 24 u = ulist[i] 25 print("{:^10}\\t{:^6}\\t{:^10}".format(u[0], u[1], u[2])) 26 27 #主函数 28 def main(): 29 uinfo = [] 30 url = \'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html\' 31 html = getHTMLText(url) 32 fillUnivList(uinfo, html) 33 printUnivList(uinfo, 20) # 20所大学 34 main()
-
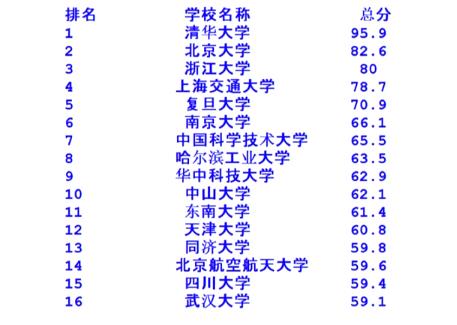
爬虫结果:

-
爬虫实例优化:
-
中文对齐问题的原因:
-
:<填充><对齐><宽度>,<.精度><类型>引导符号用于填充的单个字符<左对齐>右对齐^居中对齐槽的设定输出宽度数字的千分位分隔符适用于整数和浮点数浮点数小数备部分的精度或字符串的最大输出长度整数类型:b,c,d,o,x,X浮点数类型:e,E,f,%当中文字符宽度不够使,采用西文字符填充;中西文占用宽度不同。
-
中文对齐问题的解决:
-
采用中文字符的空格填充 chr(12288)
-
爬虫代码:
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 5 def getHTMLText(url): 6 try: 7 r = requests.get(url, timeout = 30) 8 r.raise_for_status() 9 r.encoding = r.apparent_encoding 10 return r.text 11 except: 12 return "" 13 14 def fillUnivList(ulist, html): 15 soup = BeautifulSoup(html, "html.parser") 16 for tr in soup.find(\'tbody\').children: 17 if isinstance(tr, bs4.element.Tag): 18 tds = tr(\'td\') 19 ulist.append([tds[0].string, tds[1].string, tds[2].string]) 20 21 def printUnivList(ulist, num): 22 tplt = "{0:^10}\\t{1:{3}^10}\\t{2:^10}" 23 print(tplt.format("排名", "学校名称", "总分", chr(12288))) 24 for i in range(num): 25 u = ulist[i] 26 print(tplt.format(u[0], u[1], u[2], chr(12288))) 27 28 #主函数 29 def main(): 30 uinfo = [] 31 url = \'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html\' 32 html = getHTMLText(url) 33 fillUnivList(uinfo, html) 34 printUnivList(uinfo, 20) # 20所大学 35 main()
-
爬虫结果:

以上是关于中国大学排名爬虫的主要内容,如果未能解决你的问题,请参考以下文章