iOS中的预编译指令
Posted luqinbin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了iOS中的预编译指令相关的知识,希望对你有一定的参考价值。
ios中的预编译指令的初步探究
目录[+]
开篇
我们人类创造东西的时候有个词叫做”仿生学“!人类创造什么东西都会模仿自己来创造,所以上帝没有长成树的样子而和人长得一样,科幻片里面外星人也像人一样有眼睛有鼻子……但是人类自己创造的东西如果太像自己,自己又会吓尿(恐怖谷效应),人类真是奇葩;奇葩的我们在20世纪创造了改变世界的东西——计算机(电脑),不用怀疑,这货当然也是仿生学!这货哪里长得像人了??别不服,先听我说完,先把你的砖头放下。狭义的仿生学是外形上仿生嘛,其实广义上仿生学还可以原理的仿生,构造的仿生,性能的仿生阿拉巴拉……,计算机(这里我狭义的使用个人PC来举例)我们常说的有输入设备(键盘呀鼠标呀摄像头呀……)、处理设备(CPU、GPU……)和输出设备(显示器、音响……);然后你自个儿瞅瞅你自己的眼睛耳朵(输入),大脑(处理),四肢(输出) 当初设计电脑必须要这种构造的人难道不是瞅着自己来设计计算机的么?^_^
所以上计算机组成原理的时候有什么地方晦涩难以理解的时候,我就立刻解禁我高中的生物知识,然后就迎刃而解了~但是今天我这篇博客是要讲程序的呀,这把犊子扯的那么远看客们也难免心有愤懑,你切勿急躁,我马上就带你们飞!跟着我用仿生学的角度去理解计算机,那么计算机程序是神马呢?教科书上怎么说?可以被计算机执行,那神马东西会被人执行的呢?老婆的命令、老爸的呵斥、项目经理的需求变更……我们都会执行,貌似这就是人的程序了,这确实就是人的程序!下面我具体拿老婆的命令来详解一下人得程序的执行过程;比如老婆说了一句”你给我滚出去睡沙发!“,首先这句话的处理流程是这样的:
图1
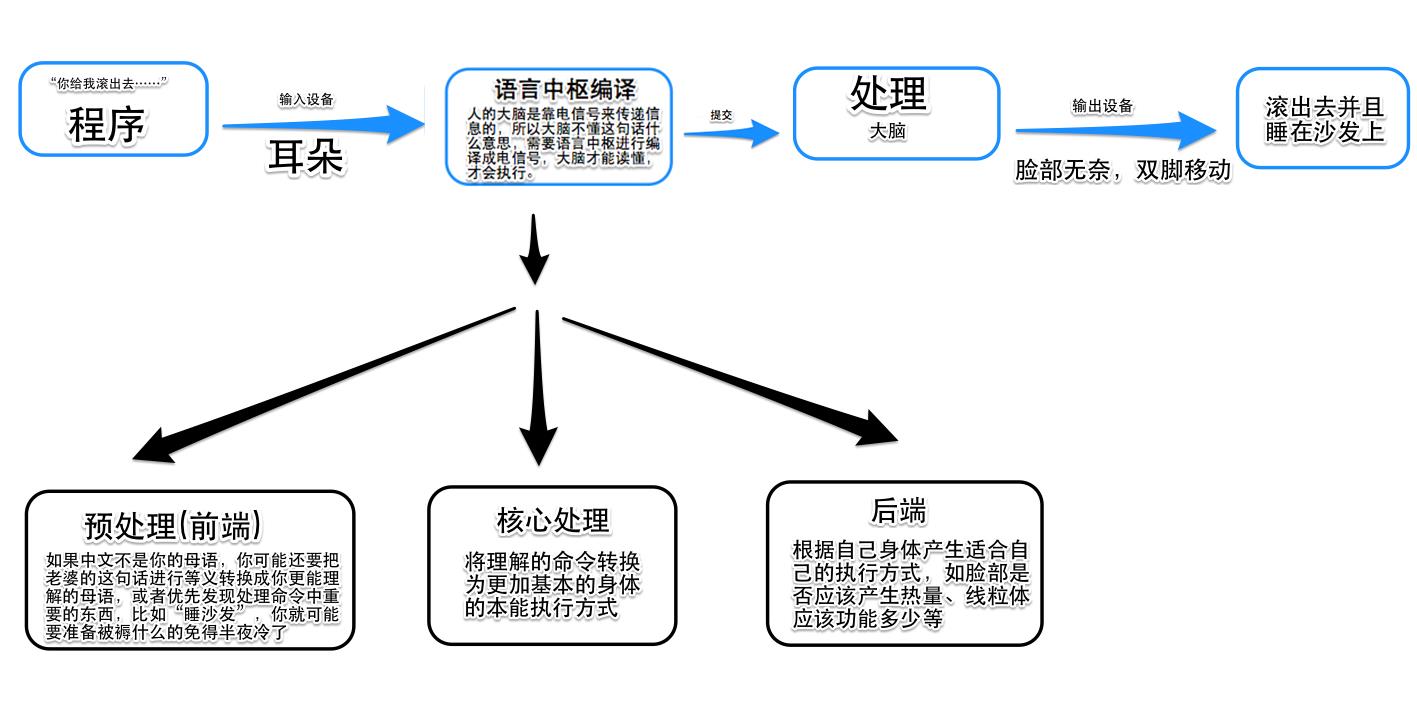
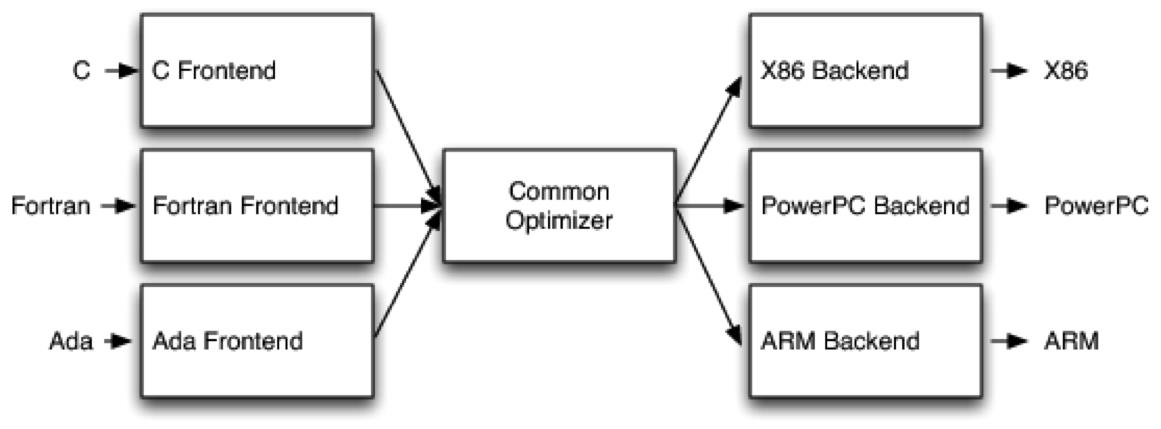
带你们看计算机程序执行过程之前,我们要严肃的了解一点程序的编译,也就是上图中的,我们把老婆的命令转换成电信号的过程。在计算机世界中有些好事者把这个玩意儿称作编译器(compiler),什么gcc呀clang呀阿拉巴拉,说的编译器这名字逼格好高~其实说白了就是个翻译的东西,如我们人执行程序过程中,把老婆的话(也是人类的话)翻译成大脑懂的话(电波),在计算机中就是把各种编程语言(c、c++、oc……)翻译成0101011……让计算机懂。编译器的工作原理基本上都是三段式的,可以分为前端(Frontend)、优化器(Optimizer)、后端(Backend)。前端负责解析源代码,检查语法错误,并将其翻译为抽象的语法树(Abstract Syntax Tree)。优化器对这一中间代码进行优化,试图使代码更高效。后端则负责将优化器优化后的中间代码转换为目标机器的代码,这一过程后端会最大化的利用目标机器的特殊指令,以提高代码的性能。
图2

为什么要弄成这三段式的呢?我肯定不会从什么框架、结构啊优化……角度说起,因为我也不懂呀,哈哈 不过我可以讲一个过去的故事给大家,大家试想一下编译器是怎么开发出来的呀,好家伙,上网一搜LLVM编译器是C++写的,那c++的编译器呢?其实不用那么麻烦,现在把你的手借给我,让我牵着你回到上个世纪70年代,里奇正在为他新发明的C语言在写编译器呢,他在用汇编语言!汇编语言怎么编译变成二进制流呢?答案是使用01011机器码编写的编译器;所以编译器和计算机语言的进步就像这样迭代发展的,再之后是用高级语言写更高级的编译器,高级的编译器能编译更高级的计算机语言……,虽然蓝翔的挖掘机技术强,但问题还是来了,世界上计算机那么多,各种不同的架构,人还好基本架构都一样,但是计算机有Intel架构的又有ARM架构,怎么能让编程语言通过编译分别产生不同架构的执行码呢?所以这就是编译器三段式这种模型的好处了,当我们要支持多种语言时,只需要添加多个前端就可以了。当需要支持多种目标机器时,只需要添加多个后端就可以了。对于中间的优化器,我们可以使用通用的中间代码。gcc可以支持c、c++、java……等语言的编译。
图3
那么一个HelloWord的程序的编译和执行过程大家就按照图1自行脑补吧
说了这么多终于正片开始了~ 原来我的啰嗦,因为我就是叫做话痨戴^_^,本人从没有开发过Mac os的应用所以本文主要示例代码和框架都是iOS下的,但是是因为C系语言的预编译指令,所以基本都能通用。虽然这篇文章有个宏大的开端,但是本文主要就是想探究一下编译过程中的预处理部分的部分预处理指令,希望本文能够做到的就是抛砖引玉,给比我菜的广大猿友指引一条学习的方向。
在很久很久以前的Xcode不知道什么版本,Build settings里面还可以选择不同的编译器。
图4
不同的编译器,是否对于预处理指令有差异,我也没办法考究了。还有其实、其实人家接触iOS也只有3个月,我开发iOS使用的第一个IDE就是XCode6,如果坑了大家,那就索瑞~~
现在Xcode6里面默认使用了Apple LLVM(Low Level Virtual Machine) 6.0的编译器
图5
各种编译器的区别还有几本对比知识可以参看LLVM和GCC的区别
关于苹果的和gcc以及LLVM背后激情个故事看以看这个三好学生Chris Lattner的LLVM编译工具链
那么接下来就是正片的高潮啦——预处理指令
高潮之前再加一个预高潮^_^,干嘛要预处理呢?回去看图一,老婆说“你给我滚出去睡沙发!” 如果你没有预处理,你按照顺序运行,先滚出去了你可能还不想睡觉,你在沙发上看电视看了几个小时后才打算睡觉,这时候你发现你竟然忘了从房间拿枕头和被子出来了,你这时候就去敲老婆的门,又是一顿臭骂,之后你才能睡觉……折腾不? 如果你进行了预处理,当老婆说完指令,其中你获取到关键字“睡沙发”,不管我滚出去之后睡不睡觉,我都先从房间把被子枕头拿到沙发,这样是不是效率高了很多?同样对于C系的语言的开发,预处理可谓举足轻重,如果你阅读过优秀的C源代码,你一定看到了很多 #define #if #error …… 预编译对程序之后的编译提供了很多方便以及优化,对于错误处理、包引用、跨平台……有着极大的帮助。而且开发中使用预编译指令完成一些事情也是很屌的事情,并且你既然走上了一条改变世界的道路那么当一个有逼格的程序猿的觉悟也需要觉醒呀
文件包含
#include
这个我真的不想多说,只要你大学C语言课程不是体育老师教得话,他们肯定跟你说过#include “”、#include <>的区别,他们肯定说过#include“xxx”包含和使用#include 包含的不同之处就是使用<>包含时,预处理器会搜索C函数库头文件路径下的文件,而使用“”包含时首先搜索程序所在目录,其次搜索系统Path定义目录,如果还是找不到才会搜索C函数库头文件所在目录。
所以我不想为了弥补你老师犯下的错,我就不想重复了,有一点需要注意使用#include的时候包含文件的时候是不能递归包含的,例如a.h文件包含b.h,而b.h就不能再包含a.h了;还有就是重复包含(比如a.h包含了b.h,然后main.c中又包含了a.h和b.h)虽然是允许的但是这会降低编译性能。那该怎么办呢?1、使用#import替代include 2、使用宏判断(宏判断下面会详解),xcode很聪明,只要新建一个头文件a.h 里面就自动就生成了
图6
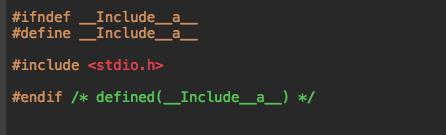
这个看不懂?你可以等看完#ifndef和#define之后就明白了,大概的原理就是,用宏定义判断一个宏是否定义了,如果没有定义则会定义这个宏,这样以来如果已经包含过则这个宏定义肯定已经定义过了,即使再包含也不会重新定义了,下面的代码也就不会包含进去。
这个是非C标准库里面的预处理指令,但是Xcode中允许使用,所以也就介绍一下吧。#include_next是GNU(一群牛逼的人疯狂开源的组织,可以说是Linux的灵魂)的一个扩展,并不是标准C中的指令 例如有个搜索路径链,在#include中,它们的搜索顺序依次是A,B,C,D和E。在B目录中有个头文件叫a.h,在D目录中也有个头文件叫a.h,如果在我们的源代码中这样写#include ,那么我们就会包含的是B目录中的a.h头文件,如果我们这样写#include_next 那么我们就会包含的是D目录中的a.h头文件。#include_next 的意思按我们上面的引号包含中的解释来说就是“在B目录中的a.h头文件后面的目录路径(即C,D和E)中搜索a.h头文件并包含进来)。#include_next 的操作会是这样的,它将在A,B,C,D和E目录中依次搜索a.h头文件,那么首先它会在B目录中搜索到a.h头文件,那它就会以B目录作为分割点,搜索B目录后面的目录(C,D和E),然后在这后面的目录中搜索a.h头文件,并把在这之后搜索到的a.h头文件包含进来。这样说的话大家应该清楚了吧。
#import
OC特有的就是一个智能的#include,解决了#include的重复包含的问题。
宏定义
#define
这个使用的就太多了,个人认为是所有预处理指令中最酷的!必须要学习!这里我厚颜无耻的转载OneV’s Den(喵神)的文章,他写的非常的棒!宏定义的黑魔法 - 宏菜鸟起飞手册,请叫我快乐的搬运工!
附上那头小牛
#define NSLog(format, ...) fprintf(stderr, "<%s : %d> %s\\n", \\
[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], \\
__LINE__, __func__); \\
(NSLog)((format), ##__VA_ARGS__); \\
fprintf(stderr, "\\n ------------------\\n/ Hello David Day! \\\\\\n\\\\ my Macro Log ~ /\\n ------------------\\n \\\\\\n \\\\ ^__^\\n (OO)\\__________\\n (__)\\\\ )\\\\/\\\\\\n ||_______ _)\\n || W |\\n YYy ww ww\\n");
图9
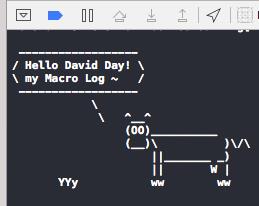
#undef
当你使用了#define宏定义后,则在整个程序的运行周期内这个宏都是有效的,但有时候我们在某个逻辑里希望这个宏失效不想使用,则会使用
#define NetworkOn
-(void)closeNetwork{#undef NetworkOn
}
条件编译
#if #else #endif
if就和我们常用的条件语句的if使用方式一样,#if的后面跟上条件表达式,后面跟上一个#endif表示结束#if,虽说这玩意儿简单,但是用的好,对于某些取巧的工作特别容易实现。比如你现在有这样的需求,我的程序平时调试模式的时候需要打印一些log,但是发布模式的应用就不用再打印log了,怎么办?很多人就说发布的时候吧log语句一句一句的删除呗~ 那客户发烂咋说你写的东西是狗屎让你修改,所以你又要回来调试,当你调试的时候你菊花肯定一紧,以前的调试语句因为过于自信在发布的时候全都删除了,又想不到发布后又被要求修改~,有基友就说了,那就不删除log语句呗,反正是打印到控制台的信息,用户又看不到~,果然没有安全意识,企业开发不是学雷锋,不用把你的所有log都写在日记本,有时候你的软件被破解的原因就是因为你的调试信息出卖了你。安全意识不可无,不然老王替你生孩子~~~~~。
怎么做呢?
#if DEBUG
func dlog<T>(object: T) {
println(object)
}
#else
func dlog<T>(object: T) {}
#endif
DEBUG是xcode的预定义的宏,这个东西多的很呢,要慢慢挖掘呢。 以后打印log你都只使用dlog()这个函数,如果你是在调试模式的时候就会打印,否则就不会打印了。
其他例子:
判断是否开启ARC,有些库需要ARC支持,则在编译之前可以判断用户有没有开启ARC
#if !__has_feature(objc_arc)
#error "啊 啊 啊~ 伦家需要ARC"
#endif
同样__has_feature(objc_arc)这玩意儿也是xcode预置的 , 前缀是这个的”__“都是预定宏;
又比如,对不同版本的os系统做策略
#if __IPHONE_OS_VERSION_MIN_REQUIRED < __IPHONE_7_0
#endif
又或者判断设备类型
#define IS_IPAD (UI_USER_INTERFACE_IDIOM() == UIUserInterfaceIdiomPad)
#if IS_IPAD
#else
#endif
这个东西简单但是很常使用,正所谓IF在手,天下我有 哈哈哈
#if define #ifdef #ifndef #elif
#if define = #ifdef
#if !define = #ifndef
#elif = "else if"
错误、警告处理
#error
如果编译器遇到这货,马上就会罢工。再说Xcode的错误纠正功能这么强大,所以几乎不可能在编译过程中遇到#error了,所以说这货没用?非也~,我们是受过高等教育的高材生,我们要懂得辩证观点还要了解价值定理!任何事物都有存在的价值的。虽说今天的IDE很好很强大,#error似乎没什么用了~但是还有有一群猿类孤高冷傲,隐居山林,他们鄙视一切IDE,他们坚信Notepad就是他们的屠龙宝刀……
对于这些虚幻飘渺的程序猿们,他们还是需要#error来给他们预报编译前的错误的。我们说点有价值的,如果非要用#error,那在我们当下的开发中怎么用?
现在#error还是有用的,尤其是你在开发一个库的时候,这个库的使用需要一定的条件,如果不满足这个条件,你就不让使用者编译。这样不就可以使用#error啦嘛
#if !__has_feature(objc_arc)
#error "我的低调不是你装逼的资本!这个库需要开启ARC,不然你别用!"
#endif
那么如果用户没有开启ARC就无法进行编译了,因为xcode看到#error就不编译了,在这里只有开启了ARC,#error才会不见。
#warning
这个用法很简单,只要后面跟上你想警告的话就OK了,这样你就可以让编译器提醒这个警告。
图10

如果你在Xcode中设置了
图11

如果你设置成Yes,那么你的waring就等于error,编译不了的哦。
请再次叫我快乐的小搬运工~ 又是他 —->Onev’s Den写的东西,我就是喜欢他,怎么样怎么样?
编译器控制
#pragma
大家都说在所有的预处理指令中,#Pragma 指令可能是最复杂的了,它的作用是设定编译器的状态或者是指示编译器完成一些特定的动作。#pragma指令对每个编译器给出了一个方法,在保持与C和C++语言完全兼容的情况下,给出主机或操作系统专有的特征。依据定义,编译指示是机器或操作系统专有的,且对于每个编译器都是不同的。
其格式一般为: #pragma Para。其中Para 为参数
我们就说说iOS下,常用的
#pragma mark
如果一个文件代码量很大,有时候找某段逻辑不太好找,你就可以使用#pragma mark!
比如这样:
图12

图13
在方法导航哪里就会出现你的mark了 是不是很方便呀
如果使用了 “#pragma mark -“ 如这样:
#pragma mark -
#pragma mark -
#pragma mark 这里是applicationWillTerminate方法呀~
- (void)applicationWillTerminate:(UIApplication *)application {
}
就会这样,
图14
自动分隔开了!!!
#pragma message(“”)
可以输出调试信息
控制编译器行为不过多解释了
#pragma clang diagnostic push
#pragma clang diagnostic ignored “clang的参数”
#pragma clang diagnostic pop
pragma非常复杂需要你对编译器底层非常的了解,只有当你开发一些比较底层的framework的时候才可能比较多用的,我是初学者,我不用我怕谁?
其他
#line
在说这个东西的时候我们先来看一个预定义的宏,LINE,我们在《宏定义的黑魔法 - 宏菜鸟起飞手册》自定义NSLog中见过吧
C语言中的__LINE__用以指示本行语句在源文件中的位置信息。而#line就是可以改变当前行的行号在编译器中的表示,并且之后的行号也会相应的改变,比如
1 #include <stdio.h>
2 main(){
3 printf("%d\\n",LINE);
4 #line 100 5 printf("%d\\n",LINE);
6 printf("%d\\n",LINE);
7 };
输出为:
3
100
101
(完)
以上是关于iOS中的预编译指令的主要内容,如果未能解决你的问题,请参考以下文章