水塘抽样算法
Posted Hi,Fairy.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了水塘抽样算法相关的知识,希望对你有一定的参考价值。
简介
作用:水塘抽样算法是一种抽样算法,对于一个很大的集合,抽取的样本值能够保证随机.
特点:其复杂度并不很高O(n),并且能够很大程度地节省内存.
问题导入
很多大公司的面试题都考察过这个算法,以谷歌为例,有一道关于水塘抽样的例题
我有一个长度为N的链表,N的值非常大,我不清楚N的确切值.我怎样能写一个尽可能高效地算法来返回K个完全随机的数.
这道题有两个限制:
1.高效,即节省内存的使用
2:尽量随机地返回值
假如我们去掉限制1,可以很简单地做出来,将所有数据加载进内存,计算链表长度,然后通过random函数来求取几个随机数.
这样的效率并不高,把所有数据加载到内存,如果数据非常大可能会导致无法计算.
注意题目中有一个小tip,就是链表.链表这种数据结构是通过数据节点首尾相连形成的链式存储结构.
既然是链表,那么可以一个一个节点处理,不需要将所有数据加载到内存.一个节点一个节点去处理,这还不够形象,将题目换个形式来表述:
我们有1T的文本文件存在硬盘中,想随机抽取几行,保证尽可能少得使用内存并且能够完全随机.
之前想到的加载到内存就不太适合了,但是还可以想到别的办法,比如每次读取一行记录加载到内存,记数+1,清空内存中行数据,直到最后统计一共多少行,然后根据总行数来计算K个随机数.如何再取回行对应的数据呢?我们可以再遍历一遍,一边遍历一边记录这一行的号码是不是在k个随机数中,如果是,则将该行内容保留.
这样的话遍历两次应该可以做到,但是1T数据遍历两次的时间消耗是非常高的.
所以还有更好的方案吗,那就是水塘抽样算法.
水塘抽样算法实现
具体例子
我们先从具体案例中理解水塘抽样算法的实现,再从抽象的角度来理解.
假如10000个数,我们要抽取十个随机数.
一万个数的样本集合数组记作S.
十个随机数的数组记作R,代表result.
先取数组S中前十个数填充进数组R.
算法的第一次迭代流程是这样的:
- 从第十一个数(下标为10)开始迭代,生成一个0到10的随机整数
j,如果j<10(假如J=4),我们就将数组R中的第5项(R[4])替换成S数组中的第11项(S[10]).
遍历完成生成的R数组,就是我们要求的随机数组.
抽象概念
$ S[N] $记作:样本集合
$ R[K] $记作:结果集合
$ N $记作:S数组大小
(J)记作:每次的随机数
(K)记作:前K个随机数
(i)记作:迭代次数.
步骤
取(S)集合中前(K)个数填入(R)集合
从(S[K])开始遍历
生成随机数(J),范围是(0->K+i-1).因为数组下标从0开始,所以-1.
如果(J<K),则替换(R)中的值->(R[j] = S[i]).
- 遍历结束,生成结果数组(R).
算法实现(JAVA)
int[] S = new int[10000];
int N = S.length;
Random random = new Random();
//生成一万个数的数组
for (int r = 0;r < N; r ++){
S[r] = random.nextInt(10000);
}
int k = 10;
int[] R = new int[k];
//S前K个数填充R数组
for (int f = 0;f < k; f++){
R[f] = S[f];
}
int j ;
//遍历数组S,根据算法,替换R数组中的元素,最终生成结果R数组.
for (int i = k;i < S.length;i++){
j = random.nextInt(i);
if (j < k) R[j] = S[i];
}
//打印R数组的结果
for (int i =0;i < R.length;i++) {
System.out.println(R[i]);
}总结一下这种算法.通过一遍遍历就获得了K个随机数,在很大数据的情况下效率是非常高的,非常适合我们的应用场景.
但是为什么这样生成的数是完全随机的呢?
就刚才的具体例子来讲,第一次遍历时,i=10,随机数的范围是0到10共11个数,那么不替换的概率是(10/11),等到第二次迭代时,不替换的概率变成(10/12),第三次(10/13),第四次(10/14).......
这样看来好像每一次的概率并不相等,其实并不是这样,我们要看的是最终进入数组(R)中的概率,虽然第十一个数进入(R)的概率比较大,但是到最后他被替换的概率也很大,所以每个数最终保留在(R)中的概率到底是多少呢?
可以参考一下维基百科中的证明,我觉得非常清晰.
在循环内第n行被抽取的机率为k/n,以(P_n)表示。如果档案共有N行,任意第n行(注意这里n是序号,而不是总数).
被抽取的机率为:
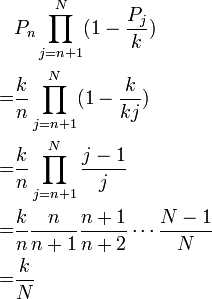
我们可以求得每行被抽取的概率是相同的,等于(k/N).
非常巧妙,所以当我们面对这种情景时,可以考虑使用水塘抽样进行随机抽取.
以上是关于水塘抽样算法的主要内容,如果未能解决你的问题,请参考以下文章