通过爬虫抓取链家二手房数据
Posted 梦雨情殇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过爬虫抓取链家二手房数据相关的知识,希望对你有一定的参考价值。
背景:
公司需要分析通过二手房数据来分析下市场需求,主要通过爬虫的方式抓取链家等二手房信息。
一、分析链家网站
1.因为最近天津落户政策开放,天津房价跟着疯了一般,所以我们主要来分析天津二手房数据,进入链家网站我们看到共找到29123套天津二手房;
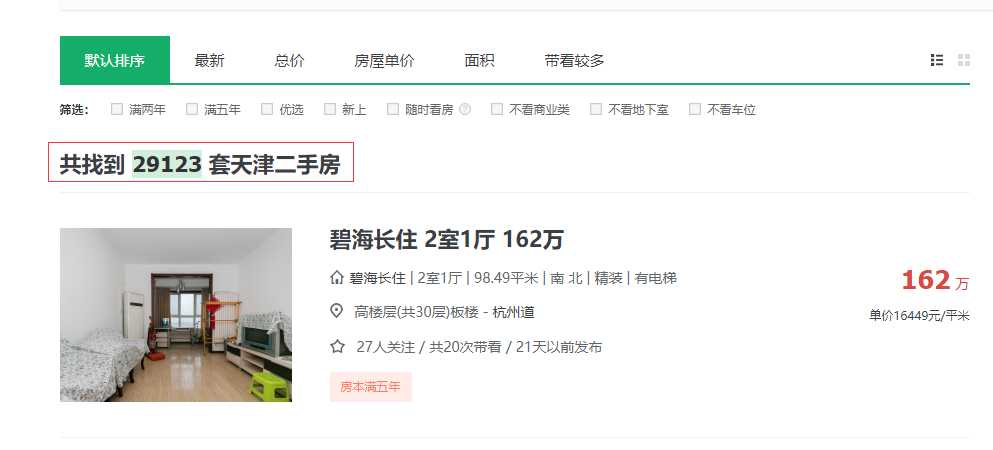
2.查看下页面的数据结构以及每页显示数据条数;
通过分析每页显示数据30条,总共显示100页面,即使我们通过翻页方式100页也只能拿到数据3000条与其提示的数据信息还差的很多。
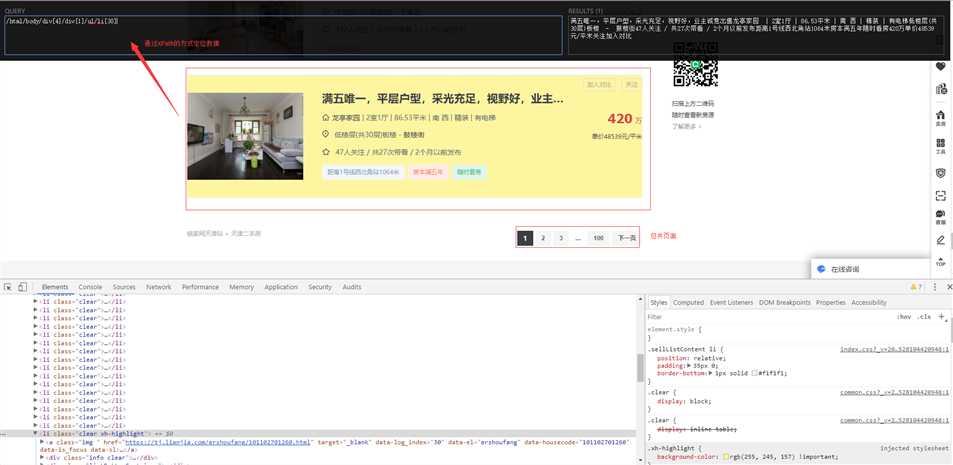
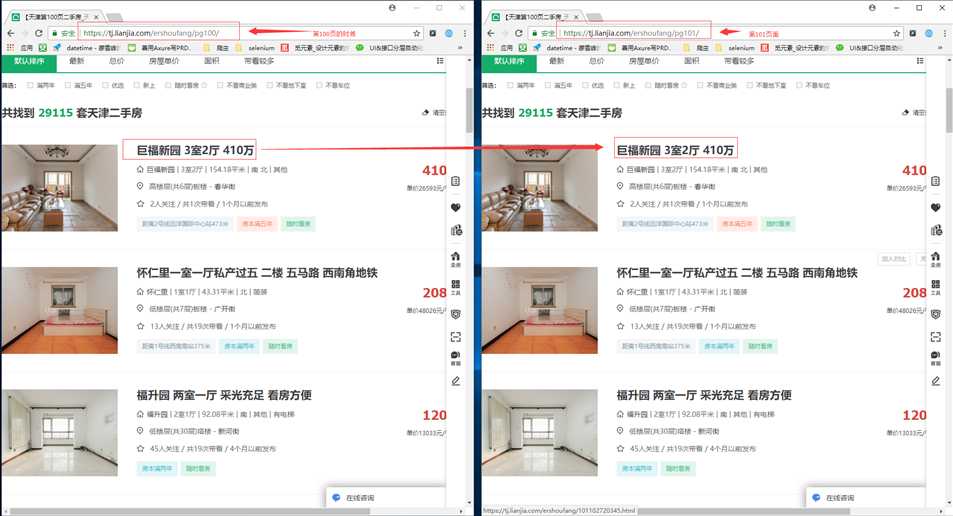
通过翻页的方式没有办法获取需要的数据的话,那么我后来考虑自己拼接url的方式来获取更多的数据,通过拼接方式发现只要超过100页的时候,无论怎么拼接他都是现实最后一页的数据,通过拼接的方式只能以失败告终
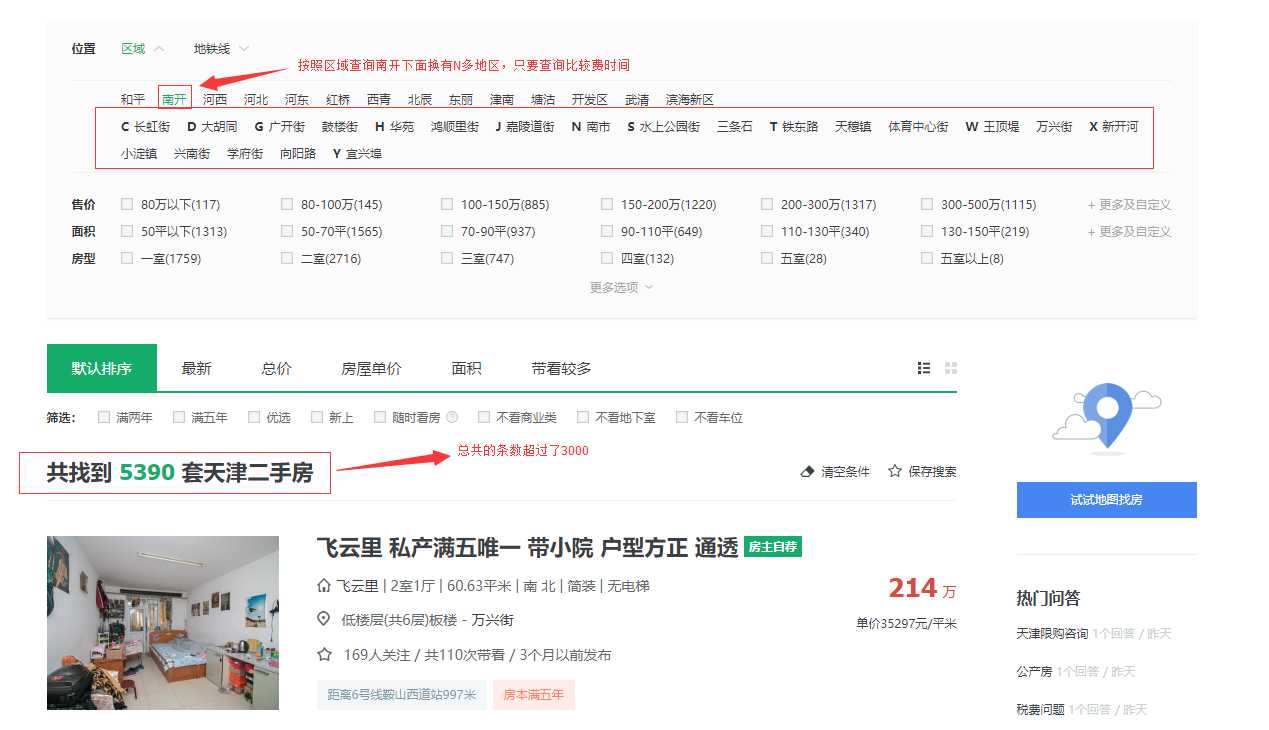
通过拼接url方式失败以后只能考虑通过按照区域的查询条件来检索数据,但是发现通过区域检索的时候有些区域二手房数量也会超过3000条,这样我们必须还的继续按照区域下面的划分,这样会虽然可以但是比较麻烦,所以这样我们暂时不考虑;
通过上面的分析链家对这块限制比较多,如果爬取来容易被封还的考虑使用代理IP来应对,这样会增加成本同时还会限制速度,所以考虑通过APP或者小程序下手抓包分析下他的接口;
二、抓包分析链家APP;
1.一般情况抓包主要通过fiddler 来抓包,下面抓下链家APP的包,手机中配置代理以后会在fiddler中显示手机发送的所有请求,这样不便于我这边分析,所以需要在fiddler设置下过滤规则;
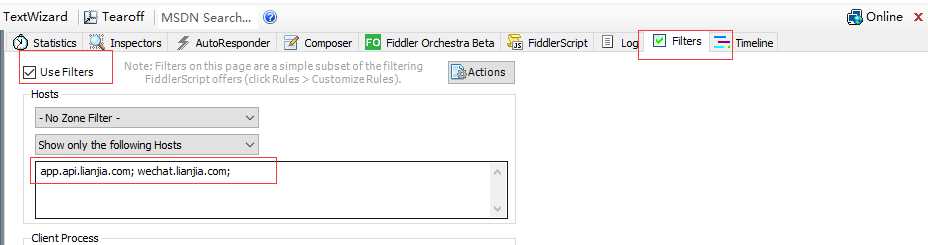
2.访问链家APP,抓取链家二手房的接口,很轻松的我们就抓到了链家二手房的请求接口,通过抓包我们看到了我们需要的数据,瞬间感觉比爬取页面简单的多;
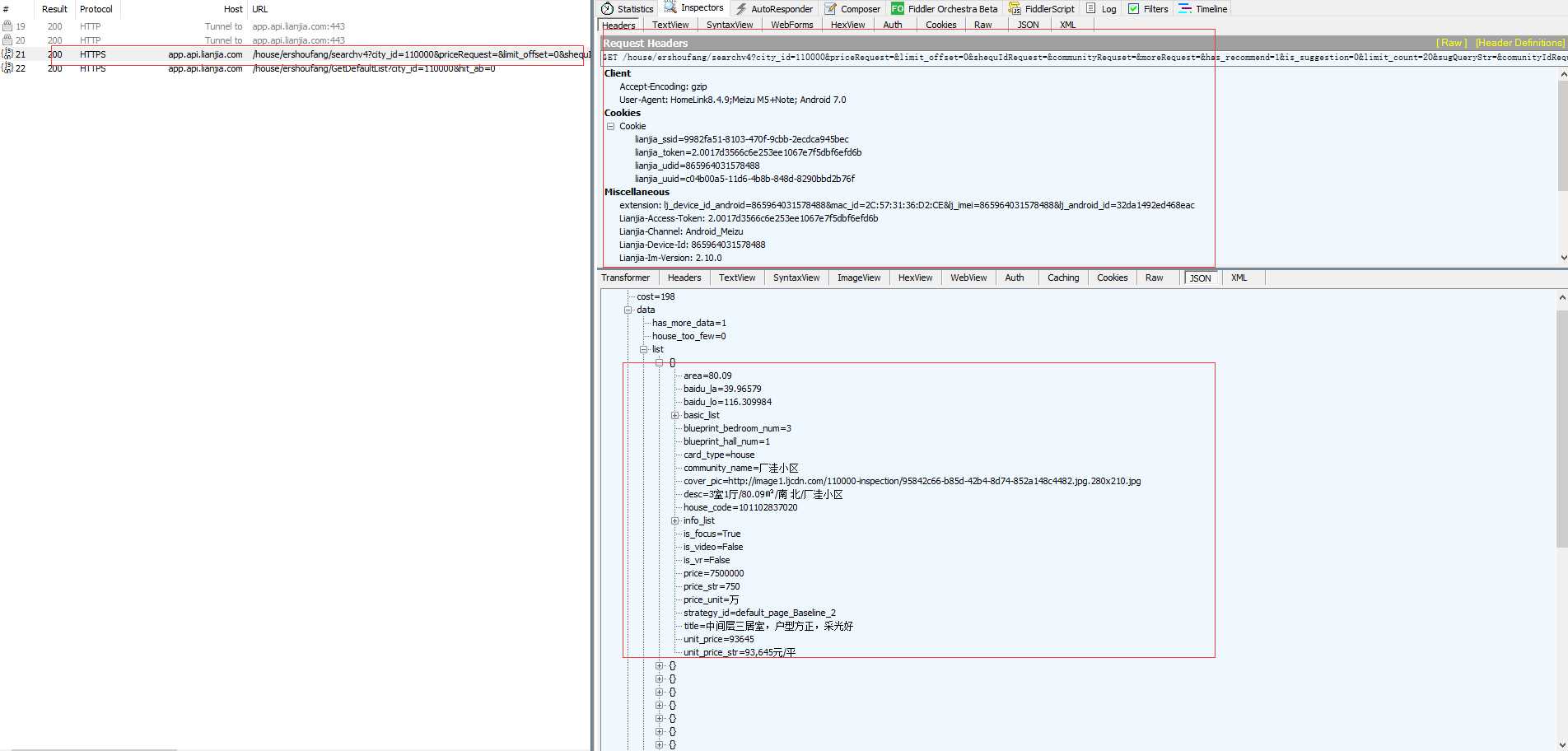
3.把接口拷贝至Postman里面来验证下接口中需要的验证和必要的参数,经过验证接口里面请求参数都是必须参数,而且headers里面有一个必须添加的参数Authorization,通过验证发现Authorization,接口参数改变后Authorization值失效;
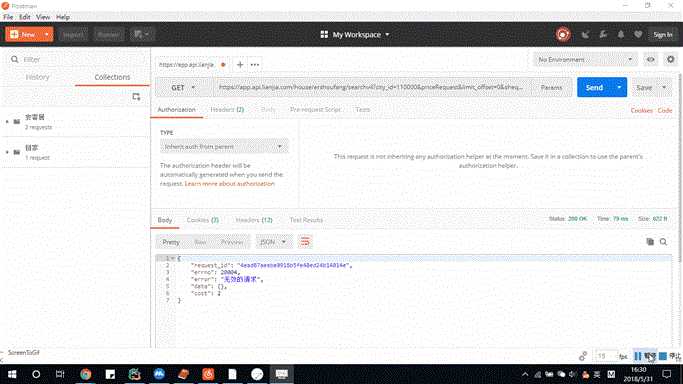
分析步骤:
1.直接复制接口在Postman请求,请求结果返回"无效的请求";
2.headers 添加参数UA再次请求,请求结果返回"无效的请求";
3.headers 添加参数Authorization再次请求,请求结果返回正常数据(抓包的过程中发现这个值很特殊所以优先尝试);
4.判断Authorization是否是动态值变更接口的参数再次请求,请求结果返回"无效的请求";
5.筛减请求参数再次请求,请求结果返回返回"无效的请求";
根据上述分析Authorization 可能根据请求参数进行加密生成的,这样我们要了解逻辑只能反编译APP,那只能再次改变策略,尝试小程序是否可以实现;
4.抓包分析链家小程序
我们依然需要按照上述的分析步骤来抓包分析,接口请求的参数均是必须参数,而且headers里面的参数依然需要authorization,这个时候我们再也没有办法避开分析这个参数了;
# 二手房微信小程序接口 https://wechat.lianjia.com/ershoufang/search?city_id=120000&condition=&query=&order=&offset=0&limit=10&sign= #headers 参数 lianjia-source:ljwxapp authorization:bGp3eGFwcDoxYTNjMDA3MmQ0ZDA3NTM2ODVlOTJlMDQ0NmUwNDk5NQ== time-stamp:1527659945696
三、反编译链家微信小程序
1.获取微信小程序所对应的 wxapkg 包文件;
i.安装android-sdk-windows,安装完成执行adb --version命令返回版本号证明安装成功;
C:Usershunk>adb --version Android Debug Bridge version 1.0.39 Version 0.0.1-4500957 Installed as D:Program Filesandroid-sdk-windowsplatform-toolsadb.exe
ii.安装MuMu模拟器安装登陆微信,添加链家小程序;
iii.通过adb命令链接模拟器,获取wxapkg 包文件;
#链接mumu 模拟器 adb connect 127.0.0.1:7555 # 注意adb连接手机端口5555 # adb shell cd /data/data/com.tencent.mm/MicroMsg/8c12ff3e9b0391b589c0d5b16dc21952/appbrand/pkg #8c12ff3e9b0391b589c0d5b16dc21952为当前微信的用户名字,可以根据自己的实际来查找 cancro:/data/data/com.tencent.mm/MicroMsg/8c12ff3e9b0391b589c0d5b16dc21952/appbrand/pkg # rm -rf * # 便于识别那个属于链家,先删除目录内容再次打开链家小程序 cancro:/data/data/com.tencent.mm/MicroMsg/8c12ff3e9b0391b589c0d5b16dc21952/appbrand/pkg # ls _-1261323258_17.wxapkg # 名字不固定,根据实际来查看 _1123949441_130.wxapkg and/pkg # cp _-1261323258_17.wxapkg /sdcard/ cancro:/data/data/com.tencent.mm/MicroMsg/8c12ff3e9b0391b589c0d5b16dc21952/appbrand/pkg # exit # 把_-1261323258_17.wxapkg 下载本地
C:Usershunk>adb pull /sdcard/_-1261323258_17.wxapkg . /sdcard/_-1261323258_17.wxapkg: 1 file pulled. 1.0 MB/s (988967 bytes in 0.941s)
2.反编译微信小程序,获取重要信息;
通过github上获取微信小程序.wxapkg解压工具,我这边使用python3来解压;
把_-1261323258_17.wxapkg和unwxapkg.py 放在通过个目录解压,会在当前目录生成_-1261323258_17.wxapkg_dir
python .unwxapkg.py .\_-1261323258_17.wxapkg
下面是解压后的目录结构
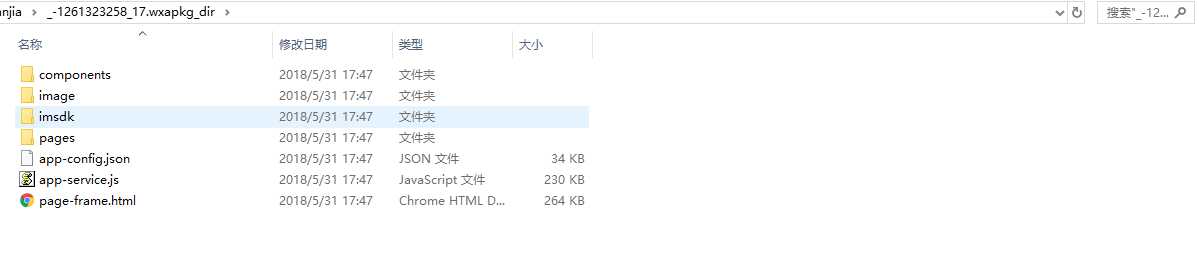
目录结构简单的介绍
| *.html | 包含wxss样式信息 |
| app-service.js | 所有js汇总文件 |
| app-config.json | app.json 以及各个页面的配置文件 |
| page-frame.html | wxml文件及app.wxss 样式 |
3.分析加密过程,生成authorization;
i.微信小程序的页面逻辑主要都会存储在app-service.js,下面我们需要来解析下这个文件,打开文件的时候里面的内容比较乱,我们需要通过格式化工具格式下js文件,使用Nodepad++ 来打开,安装下JSTool工具格式化js代码,这样会让我们看的舒服一些;
ii.通过关键字"authorization"搜索,对应的加密信息
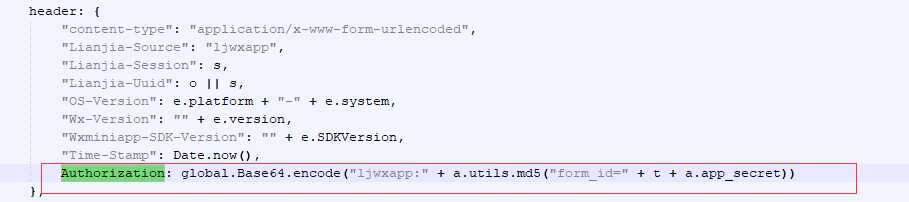
搜索出来第一处带有authorization关键字的代码,这里是请求的定义的header 信息,我们这里可以看到Authorization的值是经过base64编码;
搜索出来第二处带有authorization关键字的代码,这里我们可以看到一个关键信息l += "6e8566e348447383e16fdd1b233dbb49",这里猜想6e856这个串应该是appkey校验信息;
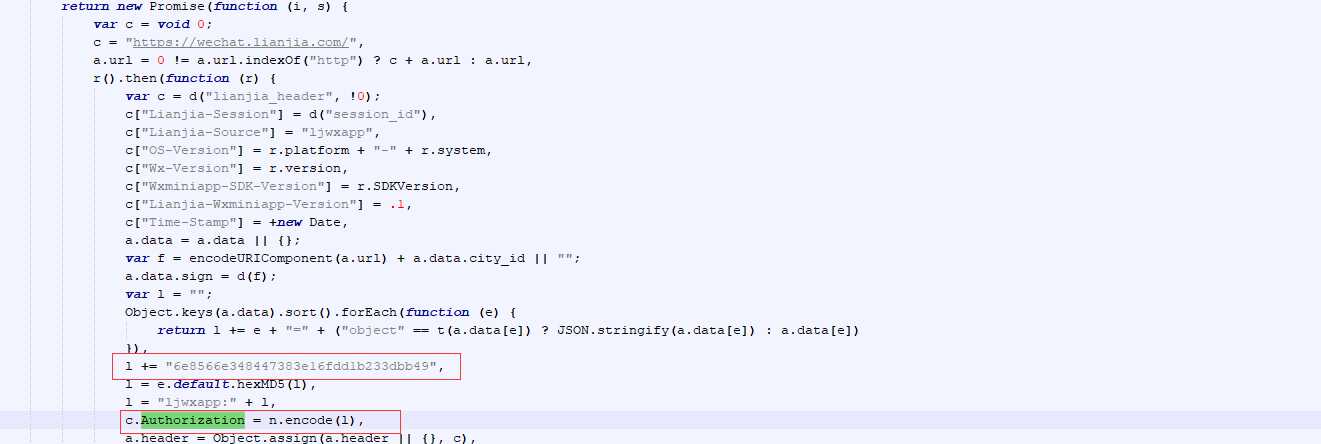
根据搜索出来的两端代码我们来进行一次分析,首先获取请求参数,然后对请求参数转换成为字典,然后通过key进行排序,使用将key和value通过= 链接起来,在末尾添加appkey,进行md5加密,最后在开头添加appid 进行base64 编码;
/*定义变量 l,空字符串*/ var l = ""; /* 1.将请求参数解析成key:value 键值对; 2.通过key进行从小到大排序; 3.通过"="将 key和value连接起来,并追加到变量 l中; */ Object.keys(a.data).sort().forEach(function (e) { return l += e + "=" + ("object" == t(a.data[e]) ? JSON.stringify(a.data[e]) : a.data[e]) }), /*l 中再次追加字符串6e8566e348447383e16fdd1b233dbb49 */ l += "6e8566e348447383e16fdd1b233dbb49", /*对l 字符串进行md5加密*/ l = e.default.hexMD5(l), /*对加密的结果添加前缀 ljwxapp:*/ l = "ljwxapp:" + l, c.Authorization = n.encode(l),
4.验证逻辑是否正确,抓取二手房列表;
import hashlib import base64 from urllib.parse import urlparse, parse_qs app_id = "ljwxapp:" app_key = "6e8566e348447383e16fdd1b233dbb49" def get_authorization(url): """ 根据url 动态获取authorization :param url: :return: """ param = "" parse_param = parse_qs(urlparse(url).query, keep_blank_values=True) # 解析url参数 data = {key: value[-1] for key, value in parse_param.items()} # 生成字典 dict_keys = sorted(data.keys()) # 对key进行排序 for key in dict_keys: # 排序后拼接参数,key = value 模式 param += str(key) + "=" + data[key] param = param + app_key # 参数末尾添加app_key param_md5 = hashlib.md5(param.encode()).hexdigest() # 对参数进行md5 加密 authorization_source = app_id + param_md5 # 加密结果添加前缀app_id authorization = base64.b64encode(authorization_source.encode()) # 再次进行base64 编码 return authorization.decode() if __name__ in "__main__":
# 天津链家二手房信息 url = "https://wechat.lianjia.com/ershoufang/search?city_id=120000&condition=&query=&order=&offset=0&limit=10&sign=" print(get_authorization(url)) # 生成加密串:bGp3eGFwcDoxYTNjMDA3MmQ0ZDA3NTM2ODVlOTJlMDQ0NmUwNDk5NQ==
我们把生成的结果放在Postman中验证看看是否正确
四、通过Scrapy 来爬取所有的二手房数据,验证上述逻辑是否正确
1.settings.py 配置文件配置接口请求的地址和APP_ID 和APP_KEY
2.定义我们要抓取的字段
# -*- coding: utf-8 -*- # @Time : 2018/5/30 10:52 # @Author : Hunk # @File : ErShouFangListItems.py # @Software: PyCharm from scrapy import Item from scrapy import Field class ErShouFangItems(Item): house_code = Field() # 二手房ID resblock_id = Field() # 小区ID resblock_name = Field() # 小区名字 price = Field() # 价格元/平
3.编写下Spider逻辑
# -*- coding: utf-8 -*- # @Time : 2018/5/30 10:51 # @Author : Hunk # @File : ParseErShouFangList.py # @Software: PyCharm import time import json import math from scrapy import Spider from scrapy import Request from lib.Encrypt import get_authorization from scrapy.utils.project import get_project_settings from ..items.ErShouFangListItems import ErShouFangItems class ParseErShouFangSpider(Spider): """ 楼盘列表 """ name = ‘TJErShouFang‘ def __init__(self, city_id, *args, **kwargs): super(ParseErShouFangSpider, self).__init__(*args, **kwargs) self.settings = get_project_settings() self.base_url = self.settings["WX_BASE_URL"] # 获取配置文件中的微信小程序的请求地址 self.api = "/ershoufang/search" # 二手房接口地址 self.city_id = city_id self.limit_offset = 0 self.new_house_url = self.base_url + self.api + "?city_id=%s&condition=&query=&order=&offset=%s&limit=10&sign" # 拼接二手房接口地址 self.start_urls = self.new_house_url % (city_id, self.limit_offset) # 请求地址 self.headers = {"time-stamp": str(int(time.time() * 1000)), "lianjia-source": "ljwxapp", "authorization": ""} # 定义header def start_requests(self): """ 重写start_requests :return: """ self.headers["authorization"] = get_authorization(self.start_urls) yield Request(url=self.start_urls, headers=self.headers, callback=self.parse) def parse(self, response): total_count = self.parse_page(response) # 获取一共有多少页面数据 for i in range(0, total_count): # 翻页操作 url = self.new_house_url % (self.city_id, self.limit_offset) # 定义请求的url self.limit_offset += 10 # 每页显示10条数据,每次翻页递增10条 self.headers["authorization"] = get_authorization(url) yield Request(url=url, headers=self.headers, callback=self.parse_house_item) def parse_house_item(self, response): """ 解析JSON 数据 :param response: :return: """ item = ErShouFangItems() content = json.loads(response.body.decode()) ershoufang_list = content["data"]["list"] if len(ershoufang_list) > 0: for ershoufang in ershoufang_list: item["house_code"] = ershoufang_list[ershoufang]["house_code"] item["resblock_id"] = ershoufang_list[ershoufang]["resblock_id"] item["resblock_name"] = ershoufang_list[ershoufang]["resblock_name"] yield item def parse_page(self, response): """ 计算总共页数 :param response: :return: """ content = json.loads(response.body.decode()) total_count = int(content["data"]["total_count"]) return int(math.ceil(total_count / 10))
4.运行自己的爬虫,查看下结果
以上过程主要记录了,抓取链家二手房数据时候的过程。
以上是关于通过爬虫抓取链家二手房数据的主要内容,如果未能解决你的问题,请参考以下文章