day01--格式化输出..运算符..初识编码
Posted lianghui-lianghui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了day01--格式化输出..运算符..初识编码相关的知识,希望对你有一定的参考价值。
一,格式化输出
%s: 处理字符串,全能的
%d:处理数字,只能接收数字
name = input("请输入名字:") age = input("请输入年龄:") print("我叫%s,今年%d岁了" % (name,int(age)))
name = input("Name:") age = input("Age:") job = input("Job:") hobby = input("Hobbie:") info = ‘‘‘ ------------ info of %s ----------- #这里的每个%s就是一个占位符,本行的代表 后面拓号里的 name Name : %s #代表 name Age : %s #代表 age job : %s #代表 job Hobbie: %s #代表 hobbie ------------- end ----------------- ‘‘‘ % (name,name,age,job,hobbie) # 这行的 % 号就是 把前面的字符串 与拓号 后面的 变量 关联起来 print(info)
二,基本运算符
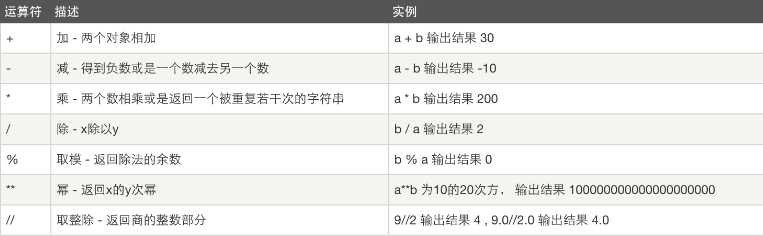
二.1 算数运算
以下假设变量:a=10,b=20
二.2 比较运算
以下假设变量:a=10,b=20

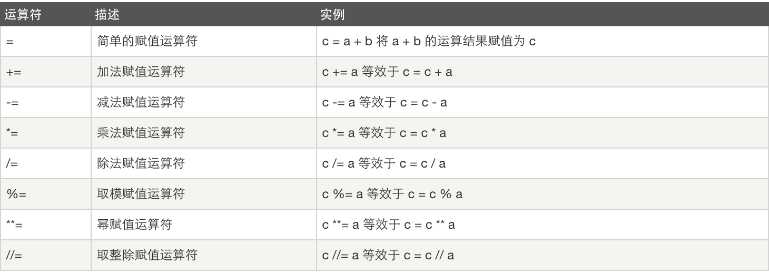
二.3 赋值运算
以下假设变量:a=10,b=20
二.4 逻辑运算
逻辑运算

***优先级关系为( )>not>and>or 同样的运算符从左往右算
x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。
and:和,并且.左右两端必须同时为真,结果才是真
or:或,或者.左右两端有一个是真,结果就是真
not:取反,非.非真即假,非假即真
三,编码
ASCII 不能装中文. 8个bit组成.最多有256种可能. 没有中文 1byte
GBK 有中文. 16个bit => 2byte
把ANSI 空余的位置交给各个国家. 交给中国之后. 中国继续编码.-GBK
交给台湾台湾继续编码. BIG5
依然不能国际化
UNICODE 万国码. 目的是把所有国家的文字都进行编码. 占32位. 缺点: 浪费
ASCII码的内容是不能改变的. 编码还应该是原来的编码. 但是unicode占用32个位置. ASCII会强制在前面补24个0. 在网络传输和数据存储上会浪费空间
32个bit => 4个byte
UTF-8: 可变长度的unicode编码, 8的意思是一个字符最少8位
英文: 8bit, 1byte
欧洲: 16bit, 2byte
中文: 24bit, 3byte
ASCII: 8bit 1byte
GBK: 16bit 2byte
unicode:32bit 4byte
UTF-8: 最少8bit, 1byte, 中文: 24bit 3byte
计算机存储系统单位换算
8bit => 1byte
1024byte => 1KB
1024kb = 1MB
1024MB = 1GB
1024GB = 1TB
以上是关于day01--格式化输出..运算符..初识编码的主要内容,如果未能解决你的问题,请参考以下文章
while循环,格式化输出%,运算符,数据类型的转换,编码的初识,
python全栈__format格式化输出while else逻辑运算符编码初识