雪花算法
Posted 布史之铭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了雪花算法相关的知识,希望对你有一定的参考价值。
关于雪花
雪花(snowflake)在自然界中,是极具独特美丽,又变幻莫测的东西:
- 雪花属于六方晶系,它具有四个结晶轴,其中三个辅轴在一个基面上,互相以60度的角度相交,第四轴(主晶轴)与三个辅轴所形成的基面垂直;
- 雪花的基本形状是六角形,但是大自然中却几乎找不出两朵完全相同的雪花,每一个雪花都拥有自己的独有图案,就象地球上找不出两个完全相同的人一样。许多学者用显微镜观测过成千上万朵雪花,这些研究最后表明,形状、大小完全一样和各部分完全对称的雪花,在自然界中是无法形成的。

雪花算法:
雪花算法的原始版本是scala版,用于生成分布式ID(纯数字,时间顺序),订单编号等。
自增ID:对于数据敏感场景不宜使用,且不适合于分布式场景。
GUID:采用无意义字符串,数据量增大时造成访问过慢,且不宜排序。

算法描述:
- 最高位是符号位,始终为0,不可用。
- 41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。
- 10位的机器标识,10位的长度最多支持部署1024个节点。
- 12位的计数序列号,序列号即一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号。
# Donet版本 ```c# using System;
namespace System
{
///
/// 分布式ID算法(雪花算法)
///
public class Snowflake
{
private static long machineId;//机器ID
private static long datacenterId = 0L;//数据ID
private static long sequence = 0L;//计数从零开始
private static long twepoch = 687888001020L; //唯一时间随机量
private static long machineIdBits = 5L; //机器码字节数
private static long datacenterIdBits = 5L;//数据字节数
public static long maxMachineId = -1L ^ -1L << (int)machineIdBits; //最大机器ID
private static long maxDatacenterId = -1L ^ (-1L << (int)datacenterIdBits);//最大数据ID
private static long sequenceBits = 12L; //计数器字节数,12个字节用来保存计数码
private static long machineIdShift = sequenceBits; //机器码数据左移位数,就是后面计数器占用的位数
private static long datacenterIdShift = sequenceBits + machineIdBits;
private static long timestampLeftShift = sequenceBits + machineIdBits + datacenterIdBits; //时间戳左移动位数就是机器码+计数器总字节数+数据字节数
public static long sequenceMask = -1L ^ -1L << (int)sequenceBits; //一微秒内可以产生计数,如果达到该值则等到下一微妙在进行生成
private static long lastTimestamp = -1L;//最后时间戳
private static object syncRoot = new object();//加锁对象
static Snowflake snowflake;
public static Snowflake Instance()
{
if (snowflake == null)
snowflake = new Snowflake();
return snowflake;
}
public Snowflake()
{
Snowflakes(0L, -1);
}
public Snowflake(long machineId)
{
Snowflakes(machineId, -1);
}
public Snowflake(long machineId, long datacenterId)
{
Snowflakes(machineId, datacenterId);
}
private void Snowflakes(long machineId, long datacenterId)
{
if (machineId >= 0)
{
if (machineId > maxMachineId)
{
throw new Exception("机器码ID非法");
}
Snowflake.machineId = machineId;
}
if (datacenterId >= 0)
{
if (datacenterId > maxDatacenterId)
{
throw new Exception("数据中心ID非法");
}
Snowflake.datacenterId = datacenterId;
}
}
/// <summary>
/// 生成当前时间戳
/// </summary>
/// <returns>毫秒</returns>
private static long GetTimestamp()
{
return (long)(DateTime.UtcNow - new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds;
}
/// <summary>
/// 获取下一微秒时间戳
/// </summary>
/// <param name="lastTimestamp"></param>
/// <returns></returns>
private static long GetNextTimestamp(long lastTimestamp)
{
long timestamp = GetTimestamp();
if (timestamp <= lastTimestamp)
{
timestamp = GetTimestamp();
}
return timestamp;
}
/// <summary>
/// 获取长整型的ID
/// </summary>
/// <returns></returns>
public long GetId()
{
lock (syncRoot)
{
long timestamp = GetTimestamp();
if (Snowflake.lastTimestamp == timestamp)
{ //同一微妙中生成ID
sequence = (sequence + 1) & sequenceMask; //用&运算计算该微秒内产生的计数是否已经到达上限
if (sequence == 0)
{
//一微妙内产生的ID计数已达上限,等待下一微妙
timestamp = GetNextTimestamp(lastTimestamp);
}
}
else
{
//不同微秒生成ID
sequence = 0L;
}
if (timestamp < lastTimestamp)
{
throw new Exception("时间戳比上一次生成ID时时间戳还小,故异常");
}
Snowflake.lastTimestamp = timestamp; //把当前时间戳保存为最后生成ID的时间戳
long Id = ((timestamp - twepoch) << (int)timestampLeftShift)
| (datacenterId << (int)datacenterIdShift)
| (machineId << (int)machineIdShift)
| sequence;
return Id;
}
}
}
}
<br/>
<br/>
# Golang版
_snowflake.go_
```go
package snowflake
// twitter 雪花算法
// 把时间戳,工作机器ID, 序列号组合成一个 64位 int
// 第一位置零, [2,42]这41位存放时间戳,[43,52]这10位存放机器id,[53,64]最后12位存放序列号
import "time"
var (
machineID int64 // 机器 id 占10位, 十进制范围是 [ 0, 1023 ]
sn int64 // 序列号占 12 位,十进制范围是 [ 0, 4095 ]
lastTimeStamp int64 // 上次的时间戳(毫秒级), 1秒=1000毫秒, 1毫秒=1000微秒,1微秒=1000纳秒
)
func init() {
lastTimeStamp = time.Now().UnixNano() / 1000000
}
func SetMachineId(mid int64) {
// 把机器 id 左移 12 位,让出 12 位空间给序列号使用
machineID = mid << 12
}
func GetSnowflakeId() int64 {
curTimeStamp := time.Now().UnixNano() / 1000000
// 同一毫秒
if curTimeStamp == lastTimeStamp {
sn++
// 序列号占 12 位,十进制范围是 [ 0, 4095 ]
if sn > 4095 {
time.Sleep(time.Millisecond)
curTimeStamp = time.Now().UnixNano() / 1000000
lastTimeStamp = curTimeStamp
sn = 0
}
// 取 64 位的二进制数 0000000000 0000000000 0000000000 0001111111111 1111111111 1111111111 1 ( 这里共 41 个 1 )和时间戳进行并操作
// 并结果( 右数 )第 42 位必然是 0, 低 41 位也就是时间戳的低 41 位
rightBinValue := curTimeStamp & 0x1FFFFFFFFFF
// 机器 id 占用10位空间,序列号占用12位空间,所以左移 22 位; 经过上面的并操作,左移后的第 1 位,必然是 0
rightBinValue <<= 22
id := rightBinValue | machineID | sn
return id
}
if curTimeStamp > lastTimeStamp {
sn = 0
lastTimeStamp = curTimeStamp
// 取 64 位的二进制数 0000000000 0000000000 0000000000 0001111111111 1111111111 1111111111 1 ( 这里共 41 个 1 )和时间戳进行并操作
// 并结果( 右数 )第 42 位必然是 0, 低 41 位也就是时间戳的低 41 位
rightBinValue := curTimeStamp & 0x1FFFFFFFFFF
// 机器 id 占用10位空间,序列号占用12位空间,所以左移 22 位; 经过上面的并操作,左移后的第 1 位,必然是 0
rightBinValue <<= 22
id := rightBinValue | machineID | sn
return id
}
if curTimeStamp < lastTimeStamp {
return 0
}
return 0
}
main.go
package main
import (
"fmt"
"reflect"
"snowflake"
"time"
)
func main() {
//var ids = []int64{}
var ids = make([]int64, 0)
//设置一个机器标识,如IP编码,防止分布式机器生成重复码
snowflake.SetMachineId(192168100101)
fmt.Println("start", time.Now().Format("13:04:05"))
for i := 0; i < 10000000; i++ {
id := snowflake.GetSnowflakeId()
ids = append(ids, id)
}
fmt.Println("end ", time.Now().Format("13:04:05"))
result := Duplicate(ids)
fmt.Println("去重后数量:", len(result))
fmt.Println(result[10], result[11], result[12], result[13], result[14])
fmt.Println(result[9990], result[9991], result[9992], result[9993], result[9994])
}
//去重
func Duplicate(a interface{}) (ret []interface{}) {
va := reflect.ValueOf(a)
for i := 0; i < va.Len(); i++ {
if i > 0 && reflect.DeepEqual(va.Index(i-1).Interface(), va.Index(i).Interface()) {
continue
}
ret = append(ret, va.Index(i).Interface())
}
return ret
}
注意:在分布式系统中给每台机器设置一个int64的机器码,可以是IP编号+随机数,如
192168011234(192.168.0.1+1234)
测试结果:
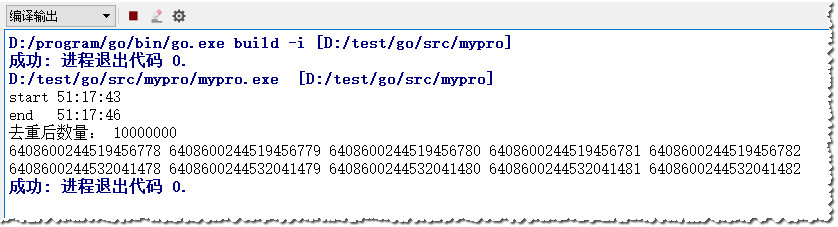
结论:
理论上生成速率为kw/秒,所以完全满足一般企业级应用, 算法可靠(去重处理在此也是多此一举);
性能:100W+/秒;
>参考: https://blog.csdn.net/u011499747/article/details/78254990
以上是关于雪花算法的主要内容,如果未能解决你的问题,请参考以下文章
Java实现雪花算法(snowflake)-生成永不重复的ID(源代码+工具类)使用案例