74. 编码与解码
Posted 江小白谢
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了74. 编码与解码相关的知识,希望对你有一定的参考价值。
编码与解码
编码:把看的懂得字符变成看不懂的码值,这个过程我们称作为编码。
解码:把码值转变成我们看的懂的字符,这个过程我们称作为解码
解码与编码过程的抽象图分析:
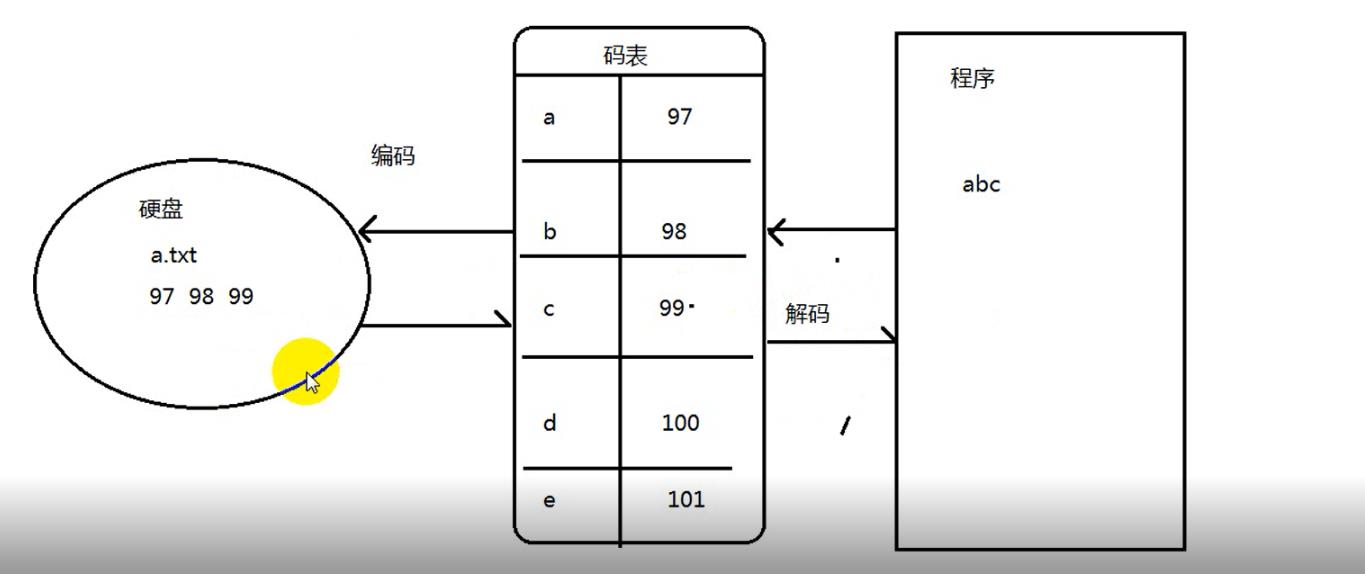
码表:在码表中,每个字符都有一个对应的码值
各种码表的简单介绍如下:

我们重点应该了解的是iso8859-1 gbk unicode utf-8
iso8859-1:这个码表很特殊,因为这个是所有码表中,是唯一一个完全占满256个编码位置,也就是说每一个码值都有对应的字符,因为是以ASCII为基础的,所以在这个码表中英文占1个字节(注意:在这个里面中文是没有对应的码值的,以这个码表编码会出现乱码)
gbk:在gb2312中几乎中国的所有字符都可以在里面找到对应的码值,后面因为不满足当时的需求,所以有gbk的诞生,gbk在gb2312的基础上面加入一些少数民族的字符,不过里面仍然有许多码值没有对应的字符,里面仍然有部分的码值没有对应的字符,在这个里面英文占有1个字节,中文占2个字节
unicode:因为每个国家都有自己的码表,感觉很混乱,这个时候unicode诞生,注意的是它只是一种规范而并不是一个码表,如果实现这个规范,那么就是容纳了所有国家的文字,在这个规范之下出现了一个utf-16的码表和utf-8码表(用unicode的时候它默认使用的是uft-16)
utf-8:因为这个是实现了unicode这个规范的码表,所以它容纳所有国家的文字,注意在这个里面英文占1个字节,中文占2个字节
utf-16:注意在这个码表里面英文和中文都占2个字节
下面我们来看看编码与解码的一些简单的实例:
public class Demo1 { public static void main(String[] args) { String str = "a中国"; //平台默认的编码是gbk,编码(把看的懂得字符变成看不懂的码值) byte[] buf = str.getBytes(); //我们再来输出看看 System.out.println("编码后的码值:"+Arrays.toString(buf)); //把码值转变成我们看的懂的字符,解码 String string = new String(buf); System.out.println("解码后的字符:"+string); } }
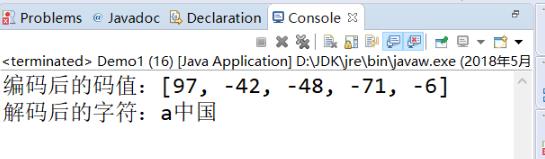
这个里面英文占一个字节,中文占2个字节,所以我们看到了5个字节(注意:一个数字代表一个字节)
getBytes(String charsetName)
使用指定的字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中。
String(byte[] bytes, Charset charset)
通过使用指定的 charset 解码指定的 byte 数组,构造一个新的 String。
我们可以用的getBytes重载和String类的另一个构造方法,用来指定我们编码表,这个可以让我们自己指定编码和解码的码表
public class Demo1 { public static void main(String[] args) throws IOException { String str = "abcd中国"; //我们使用utf-8进行编码 byte[] buf = str.getBytes("utf-8"); //我们再来输出看看 System.out.println("编码后的码值:"+Arrays.toString(buf)); //如果不指定,那么就是使用平台默认的码表(gbk),解码 String string = new String(buf); System.out.println("解码后的字符:"+string); } }

我们可以发现,在我们对已经使用utf-8编码的字符解码后出现了乱码的现象,但是英文却不出现乱码,那么可以证明的是英文可以在这两个码表中通用,中文不行
其实在所有码表中英文都是兼容的,但是中文不行,所以编码与解码一般使用相同的码表,否者容易出现乱码
证明用unicode的时候它默认使用的是uft-16
public class Demo1 { public static void main(String[] args) throws IOException { String str = "abcd中国"; //我们使用unicode码表进行编码 byte[] buf = str.getBytes("unicode"); //我们再来输出看看 System.out.println("编码后的码值:"+Arrays.toString(buf)); //使用utf-16码表解码 String string = new String(buf,"utf-16"); System.out.println("解码后的字符:"+string); } }

首先我们发现使用unicode编码,可以使用utf-16解码,这个说明使用unicode编码的时候默认使用的utf-16编码的。
注意:
1. -1 -2 只是一种标志,证明我们使用了unicode规范,并没有任何意义
2. 在utf-16中英文和中文都占2个字节
下面我们来看看iso8859-1的特殊性
public class Demo1 { public static void main(String[] args) throws IOException { String str = "a中国"; //我们使用gbk码表进行编码 byte[] buf = str.getBytes("gbk"); //我们再来输出看看 System.out.println("gbk编码后的码值:"+Arrays.toString(buf)); //使用iso8859-1码表解码 String string = new String(buf,"iso8859-1"); System.out.println("iso8859-1解码后的字符:"+string); //使用iso8859-1码表编码 byte[] buf2 = string.getBytes("iso8859-1"); System.out.println("iso8859-1解码后的字符:"+Arrays.toString(buf2)); //使用gbk解码 System.out.println("gbk解码后的码值:"+new String(buf2,"gbk")); } }

我先来说说过程,首先我们使用gbk进行了编码,最后因为我们用的是iso8859-1进行解码的,这个时候出现了乱码(英文兼容,码表不一样中文当然出现乱码)
可奇怪的是我们再使用iso8859-1码表解码iso8859-1编码过的字符的时候输出的码值与gbk编码的码值一样?
这个就要源于我们的iso8859-1码表的特殊性,因为在iso8859-1码表中每个码值都有对应的字符,所以当我们使用iso8859-1码表进行解码的时候,虽然会出现乱码,但是数据不会丢失(其他的码表不是每一个码值对应一个字符的,可能会导致数据的丢失)
我们在使用iso8859-1码表进行编码的时候,因为数据没丢失,也就是这几个数字在iso8859-1码表中都有相应的字符(虽然是乱码),才会导致我们使用iso8859-1码表进行编码时码值仍然是原来gbk编码的这几个码值
最后我们在使用gbk码表解码,就得到了我们原来的字符
(额,描述的不是很清楚,能力有限哈)
以上是关于74. 编码与解码的主要内容,如果未能解决你的问题,请参考以下文章