cerely异步分布式
Posted 星空的衣角
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cerely异步分布式相关的知识,希望对你有一定的参考价值。
1、释义:
Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理, 如果你的业务场景中需要用到异步任务,就可以考虑使用celery。
举几个实例场景中可用的例子:
- 你想对100台机器执行一条批量命令,可能会花很长时间 ,但你不想让你的程序等着结果返回,而是给你返回 一个任务ID,你过一段时间只需要拿着这个任务id就可以拿到任务执行结果, 在任务执行ing进行时,你可以继续做其它的事情。
- 你想做一个定时任务,比如每天检测一下你们所有客户的资料,如果发现今天 是客户的生日,就给他发个短信祝福
Celery 本身并不提供消息服务,在执行任务时需要通过一个消息中间件来接收和发送任务消息,以及存储任务结果, 一般使用rabbitMQ or Redis
2、Celery的优点:
- 简单:一单熟悉了celery的工作流程后,配置和使用还是比较简单的
- 高可用:当任务执行失败或执行过程中发生连接中断,celery 会自动尝试重新执行任务
- 快速:一个单进程的celery每分钟可处理上百万个任务
- 灵活: 几乎celery的各个组件都可以被扩展及自定制
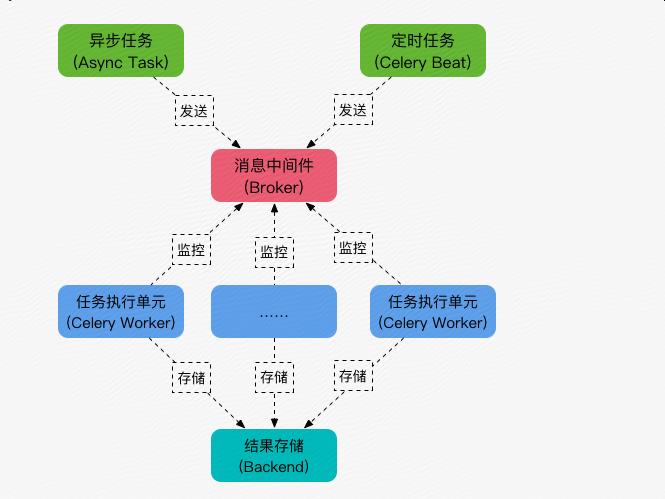
3、Celery基本工作流程图
4、示例
这里我们使用redis
连接url的格式为:
redis://:password@hostname:port/db_number
例如:
BROKER_URL = \'redis://localhost:6379/0\'
安装celery和redis
- pip install celery
- pip install redis
使用celery包含三个方面:
- 定义任务函数
- 运行celery服务
- 客户应用程序的调用
先创建一个脚本 tasks.py
from celery import Celery #导入了celery
broker = \'redis://172.16.94.85:6379/1\'
backend = \'redis://172.16.94.85:6379/2\'
app = Celery(\'tasks\', broker=broker, backend=backend) #创建了celery实例app,实例化的过程中指定任务名tasks(和文件名一致),传入了broker和backend
@app.task #装饰器
def add(x, y): #创建任务函数add
print("running...", x, y)
return x + y
在当前命令行终端运行(启动worker,worker名要和脚本名一致):
celery -A tasks worker --loglevel=info
此时会看见一对输出,包括注册的任务
新建 test.py并执行:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2018/5/26 8:17
# @Author : JWQ
# @File : demo1.py
from tasks import add #导入tasks模块
re = add.delay(10, 20)
print(re.result) #获取结果
print(re.ready) #是否处理
print(re.get(timeout=1)) #获取结果
print(re.status) #是否处理
执行test.py后在celery行能看到相关的操作日志:
[2018-05-25 11:31:28,373: WARNING/ForkPoolWorker-1] (\'running...\', 4, 4)
[2018-05-25 11:31:28,394: INFO/ForkPoolWorker-1] Task tasks.add[30b145f9-14f7-4cd8-aa5e-7b6105c52325] succeeded in 0.0216804221272s: 8
[2018-05-25 11:31:58,991: INFO/MainProcess] Received task: tasks.add[7f8207cb-d561-4567-8ae7-7c035af02762]
[2018-05-25 11:31:58,995: WARNING/ForkPoolWorker-1] (\'running...\', 4, 4)
[2018-05-25 11:31:58,998: INFO/ForkPoolWorker-1] Task tasks.add[7f8207cb-d561-4567-8ae7-7c035af02762] succeeded in 0.00274921953678s: 8
打开 backend的redis,也可以看见celery执行的信息。
在python环境中调用的add函数,实际上是在应用程序中调用这个方法。需要注意,如果把返回值赋值给一个变量,那么原来的应用程序也会被阻塞,需要等待异步任务返回的结果。因此,实际使用中,不需要把结果赋值。
5、Celery模块调用
既然celery是一个分布式的任务调度模块,那么celery是如何和分布式挂钩呢,celery可以支持多台不通的计算机执行不同的任务或者相同的任务。
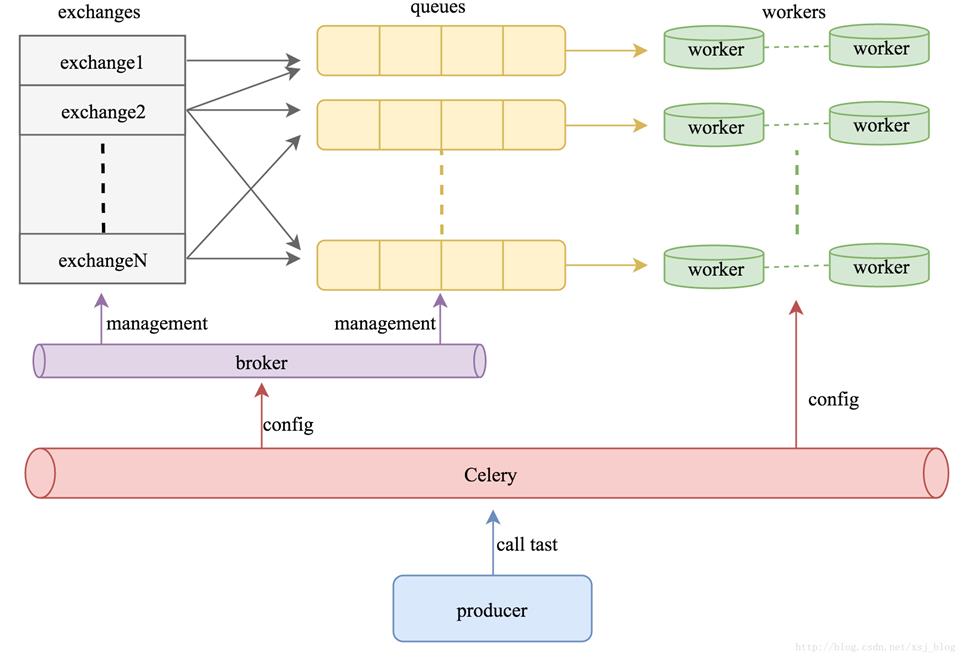
如果要说celery的分布式应用的话,我觉得就要提到celery的消息路由机制,就要提一下AMQP协议。具体的可以查看AMQP的文档。简单地说就是可以有多个消息队列(Message Queue),不同的消息可以指定发送给不同的Message Queue,而这是通过Exchange来实现的。发送消息到Message Queue中时,可以指定routiing_key,Exchange通过routing_key来把消息路由(routes)到不同的Message Queue中去,如图:
6、多worker,多队列
先写脚本task.py
[root@localhost celery]# cat tasks.py#!/usr/bin/env python
#-*- coding:utf-8 -*-
from celery import Celery
app = Celery()
app.config_from_object("celeryconfig")
@app.task
def taskA(x,y):
return x + y
@app.task
def taskB(x,y,z):
return x + y + z上面的代码中,首先定义了一个Celery的对象,然后通过celeryconfig.py对celery对象进行设置。之后又分别定义了三个task,分别是taskA, taskB和add。
[root@localhost celery]# cat celeryconfig.py#!/usr/bin/env python
#-*- coding:utf-8 -*-
from kombu import Exchange,Queue
BROKER_URL = "redis://192.168.48.131:6379/1"
CELERY_RESULT_BACKEND = "redis://192.168.48.131:6379/2"
CELERY_QUEUES = (
Queue("default",Exchange("default"),routing_key="default"),
Queue("for_task_A",Exchange("for_task_A"),routing_key="for_task_A"),
Queue("for_task_B",Exchange("for_task_B"),routing_key="for_task_B")
)
CELERY_ROUTES = {
\'tasks.taskA\':{"queue":"for_task_A","routing_key":"for_task_A"},
\'tasks.taskB\':{"queue":"for_task_B","routing_key":"for_task_B"}
}配置文件一般单独写在一个文件中
celery -A tasks worker -l info -n workerA.%h -Q for_task_A
celery -A tasks worker -l info -n workerB.%h -Q for_task_B
from tasks import *
re1 = taskA.delay(100, 200)
print(re1.result)
re2 = taskB.delay(1, 2, 3)
print(re2.result)
re3 = add.delay(1, 2, 3)
print(re3.status) #PENDING
celery -A tasks worker -l info -n worker.%h -Q celery
CELERY_TIMEZONE = \'UTC\'
CELERYBEAT_SCHEDULE = {
\'taskA_schedule\' : {
\'task\':\'tasks.taskA\',
\'schedule\':20,
\'args\':(5,6)
},
\'taskB_scheduler\' : {
\'task\':"tasks.taskB",
"schedule":200,
"args":(10,20,30)
},
\'add_schedule\': {
"task":"tasks.add",
"schedule":10,
"args":(1,2)
}注意格式,否则会有问题
celery –A tasks beat
Celery启动定时任务:
这样taskA每20秒执行一次taskA.delay(5, 6)
taskB每200秒执行一次taskB.delay(10, 20, 30)
Celery每10秒执行一次add.delay(1, 2)
以上是关于cerely异步分布式的主要内容,如果未能解决你的问题,请参考以下文章