Dota2 高分段英雄热度爬虫(模拟CSRF,RSA登陆)
Posted rokichen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Dota2 高分段英雄热度爬虫(模拟CSRF,RSA登陆)相关的知识,希望对你有一定的参考价值。
1.需求分析
相信大部分电竞玩家,都会下载max,小黑盒等软件,但是软件提供的数据模式都是固定的,本文的目标呢就是爬取dota2-max+上的所有职业战队选手的比赛信息,然后从这些场次中发现近期挑选率,胜率高的英雄,这样对天梯的大趋势就会有一个了解。选择职业选手的理由有两个:其一,职业选手对英雄强度应该是非常敏感的,会去练的基本都是强势英雄;其二,一个队伍必然囊括了所有的位置,这样他们选择的英雄从一号位到五号位都是较为均衡的,有助于我们选出所有高分局常见的强势英雄。
2.login url分析
我觉得爬虫的第一步必然是从想爬的网站的页面分析开始的,所谓知己知彼百战不殆。爬虫说白了就是模拟一个正常的用户在浏览网页的过程,了解网页的基本架构是必然的。其次呢就是我第一次写爬虫的时候对于网页的分析一头雾水,网上requests,urllib2的教程一大堆,但是如何分析网页,却很少有人教,这其实才是爬虫的关键呀。
我们打开max+,目标就是职业这个页面了:

试着打开看一下:
需要login。使用chrome浏览器。按下F12,查看网页的信息:
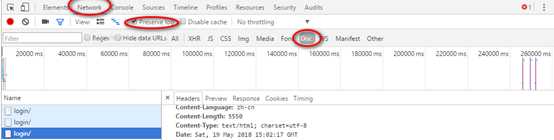
选择Network下的doc,里面就包括了该页面的代码,post/request的header,post提交的表单formdata,如何模拟登陆就是从分析这些开始。
先随意输入一个错误的账号密码,phonenum:123,password:123,登陆,登陆失败,ok分析一下该页面。
Header:
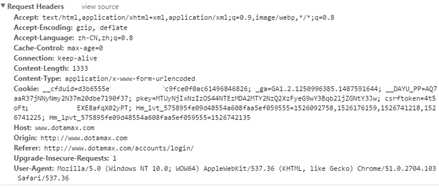
注意下这个csrftoken,待会会讲到。再来看post的form信息:
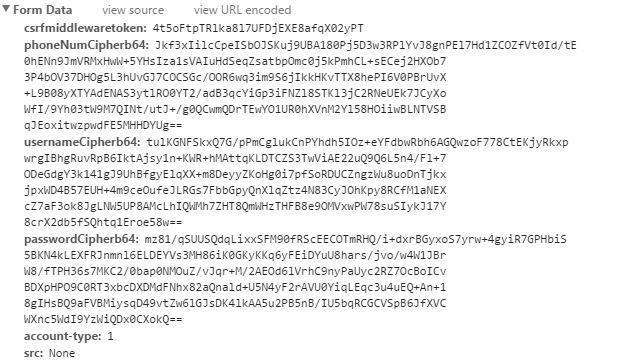
Em..登陆表单的两个个问题来了。
第一个问题:提交的表单的这个csrfmiddlewaretoken是什么?
第二个问题:phonenum/username和password都不是明文,如何处理。
3.CSRF防御的处理
CSRF是网站一种防御的机制,他的目的就是为了防止不良的URL在盗取了你的cookie之后,使用你的cookie模拟登陆,从而进行非法操作。于是在你每次访问这个页面的时候,CSRF防御会在cookie和表单中添加一个动态的csrftoken码,这样就算是你的cookie被盗取,由于csrftoken是变化的,恶意url也无法模拟你的账户登陆了。参考:https://blog.csdn.net/stpeace/article/details/53512283
这就意味着首先要获取csrfmiddlewaretoken,然后将其添加至post表单中,否则是无法模拟登陆成功的。
这给我们的爬虫带来了一点小麻烦,在post登陆表单模拟登陆之前,我们要先从网页中得到这个随机的csrfmiddlewaretoken:
先构造一个header:
header_login ={ ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/51.0.2704.103 Safari/537.36‘, ‘Referer‘:‘http://www.dotamax.com/accounts/login/‘, ‘Host‘:‘www.dotamax.com‘, ‘Accept‘:‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8‘, ‘Accept-Language‘:‘zh-CN,zh;q=0.8‘, ‘Connection‘:‘keep-alive‘, ‘Content-Type‘:‘application/x-www-form-urlencoded‘, } max_login = r‘http://www.dotamax.com/accounts/login/‘
然后使用urllib构造一个opener,使用同一opener访问同一链接时cookie是相同的,这就意味着获取到该cookie的csrfmiddlewaretoken,在接下来使用opener提交表单时同样是有效的。
cookie_filename = ‘cookie.txt‘ fobj = open(cookie_filename,‘w‘) fobj.close()#创建一个txt储存cookie信息,便于下次登陆使用,该项可以忽略 cookiejar = http.cookiejar.LWPCookieJar(cookie_filename) handler = urllib.request.HTTPCookieProcessor(cookiejar) opener = urllib.request.build_opener(handler) 然后get一下http://www.dotamax.com/accounts/login/ req_csrf = urllib.request.Request(max_login, headers = header_login) response_csrf = opener.open(req_csrf) print (‘Sutatue:‘,response_csrf.status) html = response_csrf.read().decode(‘UTF-8‘)
html就是抓取的网页的html/json代码,从中找到这一段:

正则匹配一下,csrfmiddlewaretoken就拿到了,第一个问题解决:
csrf_pattern = re.compile(‘name=\\‘csrfmiddlewaretoken\\‘ value=\\‘(.*?)\\‘‘) csrfmiddlewaretoken = re.search(csrf_pattern,utext).group(1)#获得csrf码
4.RSA加密的处理
第二个问题,可以看到表单中的PhoneNum与Password,都不是明文,在网页post表单之前,输入的账号密码都经过了加密处理。
首先在utext中寻找一下password相关的代码:
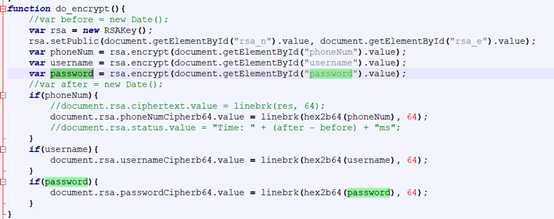
加密的function被找到了,这样可以知道post的表单在上传之前被RSA加密了。RSA加密是一个很大的话题,本人不才,也没法在这里讲清楚,但是需要知道知道一点基础的知识就可以搞定登陆表单的问题:RSA加密的过程中使用公钥rsa_n和私钥rsa_e来对报文进行加密;这意味着知道公钥rsa_n和私钥rsa_e,同时知道加密的算法,就可以模拟网页对账号密码加密,上传加密后的账号密码,便可以模拟登陆了;并且幸运的是python给我们提供了RSA包,并且附带了encrypt加密函数。
那么接下来便是找到公钥rsa_n和私钥rsa_e,同样是在html中寻找:


Ojbk,最理想的情况出现了,公钥rsa_n和私钥rsa_e都在html中被找到(某些网站的n或rsa_e被隐藏在了token中,这种情况会麻烦一些),使用RSA包写一个加密的函数:
def encry(message): rsa_e = 10001 rsa_n = ‘B81E72A33686A201B0AC009D679750990E3D168670DC6F9452C24E5A4C299AC002C6C89C3CB38784AEA95D66B7B3E9C‘ ‘A950EB9EEFB4EF61383EDDB67C35727F9CA87EE3238346C66D042B35812179501F472AD4F3BA19E701256FE0435AB85‘ ‘6E5C5BEA24A2387153023CD4CD43CDA7260FCC1E2E49C14102C253F559F9A45D59DF5004A017B1239448A9A001D276C‘ ‘AD12535DEDE89FFBD57D75BBC9B575530DDD1B7FAD46064AD3C640CBD017F58981215B2EE17CBE175C36570C5235902‘ ‘818648577234E70E81133B088164F98E605D0D6E69A6095A32A72511E9AC901727B635CE2E8002A7B0EC8D012606903‘ ‘BCB825E60C7B6619FFCED4401E693F5EC68AB‘ rsaPublickey = int (rsa_n,16) rsaPrivate=int (str(rsa_e),16) key = rsa.PublicKey(rsaPublickey,rsaPrivate) message = message.encode() passwd = rsa.encrypt(message,key) passwd64 = binascii.b2a_base64(passwd) message_encrypt = bytes.decode(passwd64) return message_encrypt
需要注意密匙加密之前要encode转换为字节码,加密之后decode重新转换为字符串。
这样账号密码加密的问题也解决了。接下来按照常规步骤,爬取数据就可以了。
5.模拟登陆并保存cookie
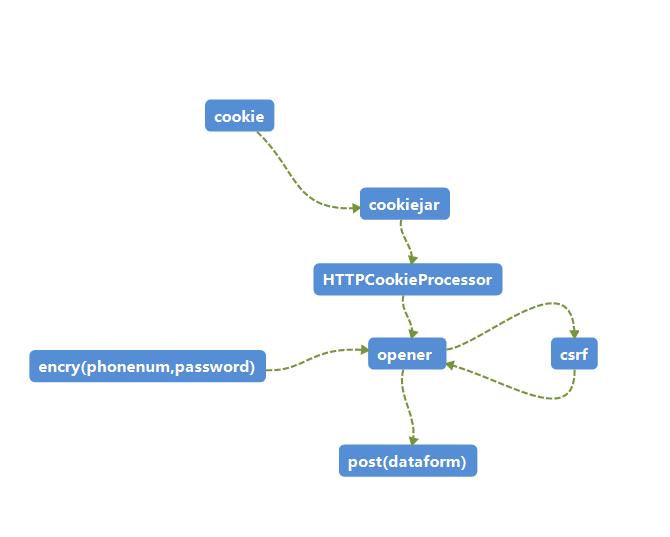
至此已经完成了opener的构造,获取到了csrfmiddlewaretoken,完成了encrypt加密函数。接下来便可以构造post表单了。
phoneNumCipherb64 = encry(phone_num) passwordCipherb64 = encry(passw) usernameCipherb64 = encry(usern) values1 = {‘csrfmiddlewaretoken‘:csrfmiddlewaretoken,‘phoneNumCipherb64‘:phoneNumCipherb64,‘usernameCipherb64‘:usernameCipherb64,‘passwordCipherb64‘:passwordCipherb64,‘account-type‘:‘1‘,‘src‘:None} data_login = urlencode(values1).encode(encoding=‘UTF8‘) req = urllib.request.Request(max_login,data=data_login,headers=header_login) response = opener.open(req)#至此完成登陆操作,并将cookie保存至response中。 html_login = response.read().decode(‘UTF-8‘) if not ‘pkey‘ in [cookie.name for cookie in cookiejar]: print ("We are not logged in !") else: print("We are logged in !")
很常规的操作,登陆之后检查一下pkey项是否在cookie中来确认是否登陆成功,若登陆失败的话cookie中不会保存这一项。
6.分析url,将所有选手的steam id爬取下来
完成了模拟登陆,那么登陆之后才能看到的信息也可以爬取了,接下来就是将所有选手的steam id爬取下来,方便我们之后遍历所有职业选手的近期比赛,从而获得想要的英雄趋势的数据。目标页面:http://www.dotamax.com/player/pro/
得到页面的html,找到选手steam id相关的字段。

分析之后做一个正则匹配,就拿到选手id的数据了。
#获取职业选手id max_player = ‘http://www.dotamax.com/player/pro/‘ players_html = maxcrawler.get_webtext(opener,max_player,header_data,form_csrf) players_pattern = re.compile(‘<span style="color:#555;">([\\d]*)</span></div></a></td>‘) player_list = re.findall(players_pattern,players_html)
7.抓取职业选手近期比赛信息
接下来就是最终的目标了,职业选手的比赛信息代表着高分段的信息,来看看到底是什么英雄风靡高分段。
选手的个人页面是通过id来构造的:

所以用获得的选手id表单player_list,对他们的个人页面遍历就可以把近期比赛的数据全都抓取下来了。
分析一下个人页面的html:

对该段做正则匹配,遍历所有的选手,想要的数据就抓取下来了:
for id in player_list: player_url = ‘http://www.dotamax.com/player/detail/%s/‘%id player_html = maxcrawler.get_webtext(opener,player_url,header_data,form_csrf) recenthero_pattern = re.compile(‘\\t+ \\t(.*?) </a></td><td sorttable_customkey=‘) player_hero_list = player_hero_list+ re.findall(recenthero_pattern,player_html) recentRate_pattern = re.compile(r‘!important;">(.*?)</font></td><td>(\\s)‘) player_result_list = player_result_list+ list(map(lambda x:x[0] ,re.findall(recentRate_pattern,player_html))) if len(player_hero_list) > 100: break time.sleep(0.5)
进行一些简单的数据处理:
将list转换为dict:
hero_win_dic = dict(zip(hero_list,[0 for x in range(len(hero_list))])) hero_lost_dic = hero_win_dic.copy() for index,ele in enumerate(player_hero_list): if player_result_list[index] == ‘胜利‘: hero_win_dic[ele] = hero_win_dic[ele]+1 else: hero_lost_dic[ele] = hero_lost_dic[ele] + 1 print(hero_lost_dic) print(hero_win_dic)
将dict转换为dataframe并保存为csv格式:
profession_df = pandas.DataFrame([hero_win_dic,hero_lost_dic],index= [‘profession_win‘,‘profession_lost‘]) profession_df = profession_df.T profession_df[‘select_num‘] = profession_df[‘profession_win‘]+profession_df[‘profession_lost‘] profession_df[‘win_rate‘] = profession_df[‘profession_win‘]/profession_df[‘select_num‘] profession_df.to_csv(time.strftime(‘%Y-%m-%d‘,time.localtime(time.time()))+‘.csv‘)
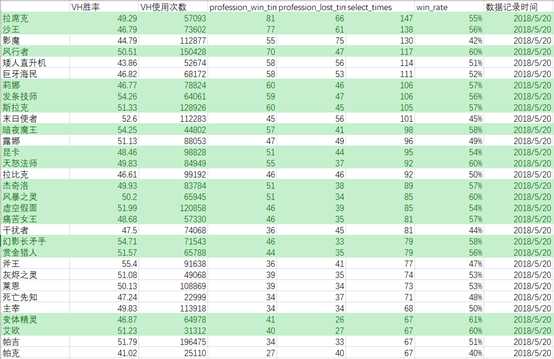
爬到的数据到手,数据的样本有点偏少,但是也能大致反应高分段天梯的趋势,挑选次数多,胜率又高的英雄,应该是值得练一手来上分的当前版本一档英雄~~