jvm1
Posted 672530440
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jvm1相关的知识,希望对你有一定的参考价值。
java JVM内存模型 %.1.java监控工具使用 %.2.Jps查看jvm的进程 %.2.1.jconsole jconsole是一种集成了上面所有命令功能的可视化工具,可以分析jvm的内存使用情况和线程等信息。 通过JDK/bin目录下的“jconsole.exe”启动Jconsole后,将自动搜索出本机运行的所有JVM进程,不需要用户使用jps来查询了,双击其中一个进程即可开始监控。也可以“远程连接服务器,进行远程虚拟机的监控。” Main进程是本地的一个springboot项目。
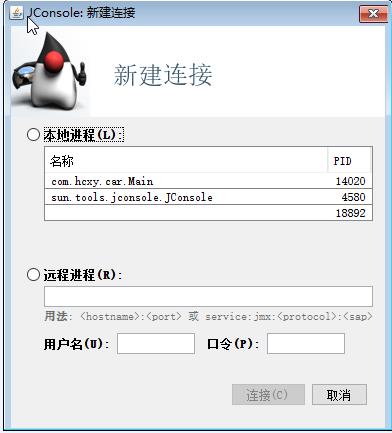
远程连接:jvisualvm和jconsole是一样的。
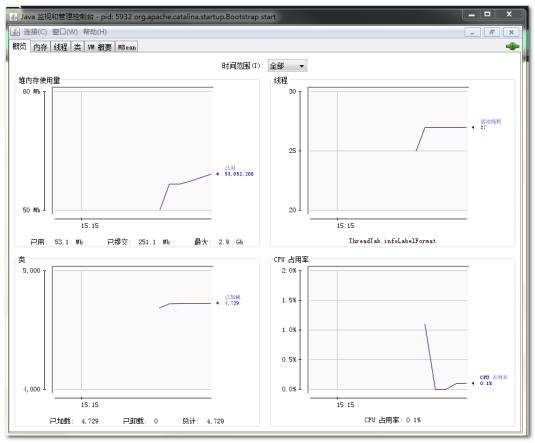
概述页面显示的是整个虚拟机主要运行数据的概览。非堆区是方法区(永久区)。
.1.1. jvisualvm比jconsole更好用,也在bin里面
提供了和jconsole的功能类似,提供了一大堆的插件。
插件中,Visual GC(可视化GC)还是比较好用的,可视化GC可以看到内存的具体使用情况。
本地进程(jvm进程):eclipse,JConsole,VisualVM(是他自己),
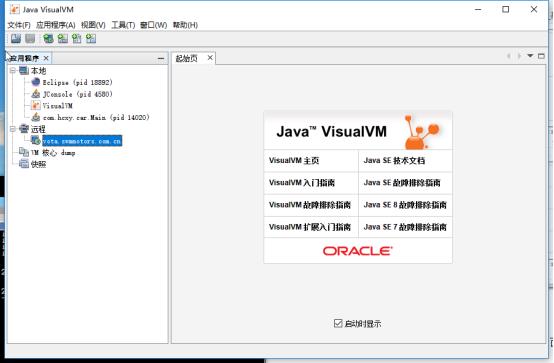
Dump出来可以有一个很详细的线程报告:
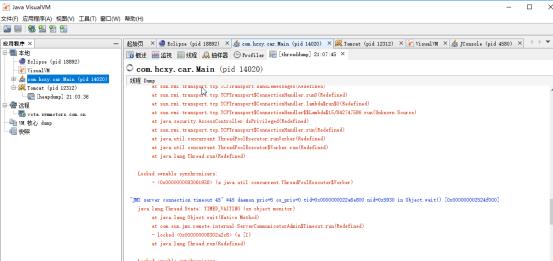
Eclipse和tomcat也有性能监控工具。
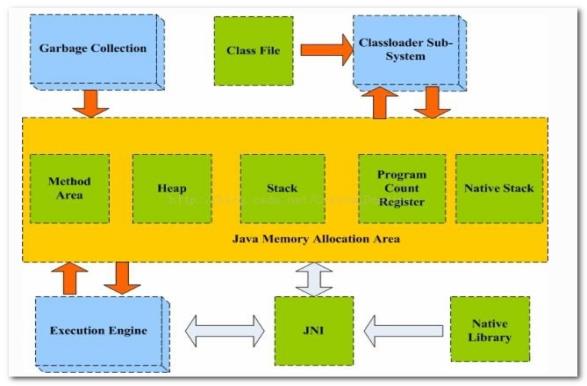
%.1.java内存模型 %.1.1.内存模型图解 虚拟机把所管理的内存区域划分为若干个不同的区。这些区域有各自的用途以及创建和销毁的时间。 有的区域随着虚拟机进程的启动而存在,有的区域则依赖用户线程的启动和结束而建立和销毁,我们可以将这些区域统称为Java运行时数据区域。 Java虚拟机运行时数据区域被分为五个区域:堆(Heap)、栈(Stack)、本地方法栈(Native Stack)、方法区(Method Area)、程序计数器(Program Count Register)。 类的定义放在一个地方,放在方法区里面Method Area也叫永久区。 程序运行会产生一个个的对象,放在堆里面。 栈(Stack)是程序执行的时候本质是启动一个main线程执行,main线程执行方法的时候有局部变量放在栈里面。 栈里面是分线程存放的,每个线程都有自己的栈空间,保证每个线程不冲突。堆里面是线程共享的。一个线程会调用多个嵌套的方法a调B,B调C,比如递归里面。线程每调用一个方法就会产生一个栈桢,存放方法调用过程中需要的变量。调用的方法过多就会产生栈溢出。
程序计数器(Program Count Register):执行到哪一行了。
本地方法栈(Native Stack):jvm跟操作系统的交互,调用windows和linux的方法,比如文件操作都会调用本地操作系统的方法。
垃圾回收:C++里面maloc之后要free掉,
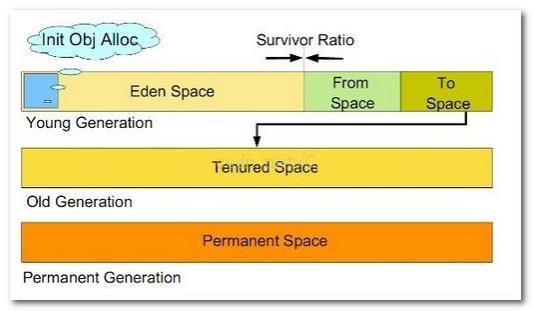
%.1.1. 堆(Heap) Java Heap区域随着虚拟机的启动而创建。是一块共享的区域有锁和同步。 堆分为新生代、老年代、永久区(方法区)。垃圾回收也要回收永久区(静态变量,类的定义),永久区也会溢出,所以垃圾回收也回收永久区。 新生代、老年代根据对象存活的年龄划分的。New的新的对象在新生代,垃圾回收器 垃圾回收器从程序的根节点开始搜索,看能够走到哪些对象,A引用B,B引用A,但是程序到达不了这个对象,虽然A和B都有引用(根据引用判断垃圾是不准确的),但是垃圾回收器到达不了,还是会把他当成垃圾回收。
收集器的使用(配置文件配置):

现在大多数的GC基本都采用了分代收集算法。如果再细致一点,Java Heap还有Eden空间,From Survivor空间,To Survivor空间等。
Java Heap可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可。
.1.1. 堆
.1.1. 栈(Stack)
相对于Java Heap来讲,Java Stack是线程私有的,她的生命周期与线程相同。Java Stack描述的是Java方法执行时的内存模型,每个方法执行时都会创建一个栈帧(Stack Frame)用语存储局部变量表、操作数栈、动态链接、方法出口等信息。从下图从可以看到,每个线程在执行一个方法时,都意味着有一个栈帧在当前线程对应的栈帧中入栈和出栈。
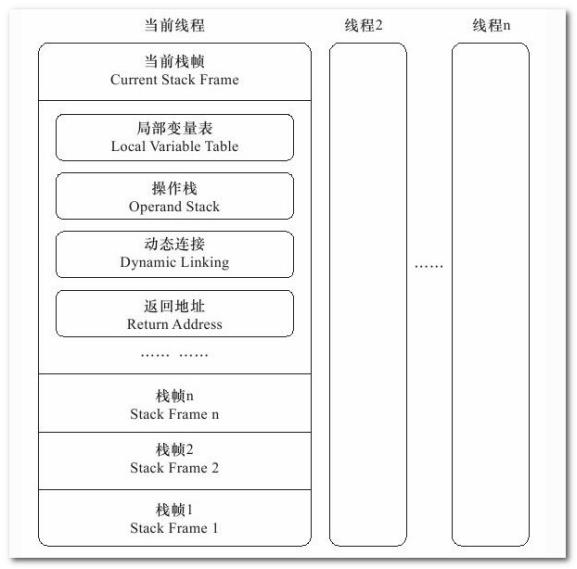
图中可以看到每一个栈帧中都有局部变量表。局部变量表存放了编译期间的各种基本数据类型,对象引用等信息。
%.1.1.本地方法栈(Native Stack) 本地方法栈(Native Stack)与Java虚拟机站(Java Stack)所发挥的作用非常相似,他们之间的区别在于虚拟机栈为虚拟机栈执行java方法(也就是字节码)服务,而本地方法栈则为使用到Native方法服务。与操作系统的方法交互。 %.1.2.方法区(Method Area) 方法区(Method Area)与堆(Java Heap)一样,是各个线程共享的内存区域,它用于存储虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据(会把jsp编译成servlet的java代码)。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是她却有一个别名叫做非堆(Non-Heap)。分析下Java虚拟机规范,之所以把方法区描述为堆的一个逻辑部分,应该觉得她们都是存储数据的角度出发的。一个存储对象数据(堆),一个存储静态信息(方法区)。 在上文中,我们看到堆中有新生代、老生代、永久代的描述。为什么我们将新生代、老生代、永久代三个概念一起说,那是因为HotSpot虚拟机的设计团队选择把GC分代收集扩展至方法区,或者说使用永久代来实现方法区而已。这样HotSpot的垃圾收集器就能想管理Java堆一样管理这部分内存。简单点说就是HotSpot虚拟机中内存模型的分代,其中新生代和老生代在堆中,永久代使用方法区实现。根据官方发布的路线图信息,现在也有放弃永久代并逐步采用Native Memory来实现方法区的规划,在JDK1.7的HotSpot中,已经把原本放在永久代的字符串常量池移出。
%.1.1.总结 1、线程私有的数据区域有: Java虚拟机栈(Java Stack) 本地方法栈(Native Stack) 2、线程共有的数据区域有: 堆(Java Heap) 方法区
.1. JVM参数列表
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0 -Xmx3550m:最大堆内存为3550M。 -Xms3550m:初始堆内存为3550m。 此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。 -Xmn2g:设置年轻代大小为2G。 整个堆大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。 -Xss128k:设置每个线程的栈大小。 JDK5.0以后每个线程栈大小为1M,在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在 3000~5000左右。 -XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5 -XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。 设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6 -XX:MaxPermSize=16m:设置持久代大小为16m。 -XX:MaxTenuringThreshold=0:设置垃圾最大年龄。 如果设置为0的话,则年轻代对象不经过Survivor区,直 接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象 再年轻代的存活时间,增加在年轻代即被回收的概论。 收集器设置 -XX:+UseSerialGC:设置串行收集器 -XX:+UseParallelGC:设置并行收集器 -XX:+UseParalledlOldGC:设置并行年老代收集器 -XX:+UseConcMarkSweepGC:设置并发收集器 垃圾回收统计信息 -XX:+PrintGC :jvm故障调试的时候 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:filename 并行收集器设置 -XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。 -XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间 -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n) 并发收集器设置 -XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。 -XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
以上是关于jvm1的主要内容,如果未能解决你的问题,请参考以下文章
Java岗大厂面试百日冲刺 - 日积月累,每日三题Day25—— JVM1
Caused by: com.rabbitmq.client.ShutdownSignalException: connection error