算法之美_源代码发布
Posted 白马负金羁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法之美_源代码发布相关的知识,希望对你有一定的参考价值。
1. 关于numpy.random.randn
作用是从正态分布中产生随机样本,其调用格式为numpy.random.randn(d0, d1, ..., dn),这里的d0, d1, ..., dn应该是正的整数,用以表示生成随机序列(或多维矩阵)的shape,如果你输入的数字是float,那么它们会被用截断的方法转换成整数。如果你只要返回一个随机数,那么这个参数列表可以省略。例如:
>>> np.random.randn()
0.9785127566990875此外,如果希望产生符合N(mu, sigma^2)的随机数,你可以使用下面这种写法
sigma * np.random.randn(...) + mu
例如,欲从分布N(3, 6.25)中产生一个2×4的矩阵,则可以使用下面的语句:
>>> 2.5 * np.random.randn(2, 4) + 3
array([[ 3.70744179, 2.39671751, 5.45092548, 2.19642738],
[ 1.54957143, 6.85870137, 3.78902539, -0.92371664]])
2. numpy包中tile()函数
tile(A, reps) 用于重复一个数组A,其中 reps表示重复的次数
例如:
>>> a = np.array([0, 1, 2])
>>> np.tile(a, 2)
array([0, 1, 2, 0, 1, 2])再比如,下面的代码会得到一个二维数组,原数组重复2次,所得之结果再重复2次:
>>> np.tile(a, (2, 2))
array([[0, 1, 2, 0, 1, 2],
[0, 1, 2, 0, 1, 2]])类似地,下面的代码会得到一个三维数组:
>>> np.tile(a, (2, 1, 2))
array([[[0, 1, 2, 0, 1, 2]],
[[0, 1, 2, 0, 1, 2]]])
3. 利用Pandas去除重复的记录
首先,从一个csv文件中读取数据,并用一个dataframe来存放
import pandas as pd
import numpy as np
df = pd.read_csv("csvdata.csv", index_col = 0)
print(df)其中的数据如下

DataFrame的IsDuplicated方法返回一个布尔型Series,表示各行是否重复行。例如,
IsDuplicated=df.duplicated()
print IsDuplicated将会输出如下结果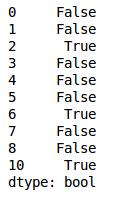
而 drop_duplicates方法,它用于返回一个移除了重复行的DataFrame,例如
frame1=df.drop_duplicates()
print frame1对于前面Series中结果为True的行将都会被剔除,于是得到

如果IsDuplicated方法和drop_duplicates方法中没有设置参数,则这两个方法默认会判断全部列,如果在这两个方法中加入了指定的属性名(或者称为列名),便可根据指定的部分列进行重复项判断。例如
frame2=df.drop_duplicates(['qid3'])
print frame2会得到如下结果

4. 列表的append()函数与extend()函数
append()将括号里面的参数的值作为整体,追加到原来的列表之中。extend()将括号里面的参数的迭代值一个一个地追加到原来的列表中。因此,使用extend()的便利在于:不必用for遍历参数列表中的值并多次调用append()函数,直接用extend()搞定。
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> a.append(b)
>>> a
[1, 2, 3, [4, 5, 6]]
>>> d = [1, 2, 3]
>>> d.extend(b)
>>> d
[1, 2, 3, 4, 5, 6]
5. 要统计一个字符串中,某个字符串出现的次数,可以使用count()方法。
默认情况下,该函数会搜索整个字符串。当然,也可以通过参数来指定搜索的范围。
>>> my_str = "hello world!"
>>> my_str.count('l')
3
>>> my_str.count('l', 0, 10)
3
6. 操作csv文件的一些技巧
假设有一个名为test_file.csv的文件,如下:

下面的代码首先读入这个csv文件,其中 index_col = 0 表示原csv文件中的第一列为index列。reset_index函数用于重新设定index。
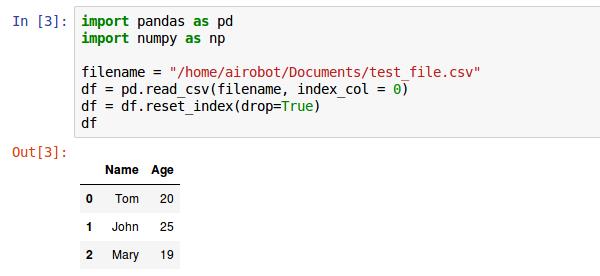
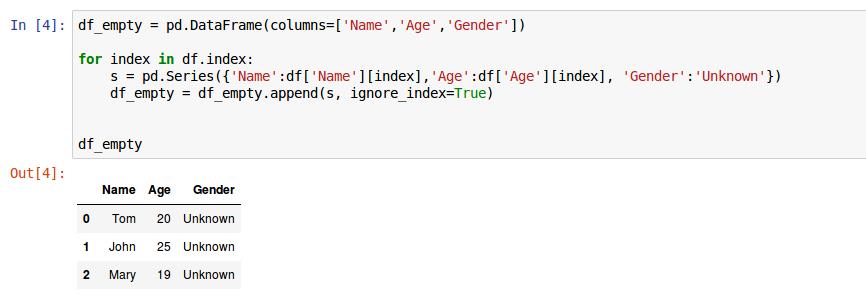
7. 建立一个空的dataframe,然后逐行写入数据
下面我们重新建立一个名为pd_empty的空dataframe,然后逐行地向其中写入数据:
8. 再创建一个名为df2的新dataframe,并将其追加到已经创建好的pd_empty的后面。
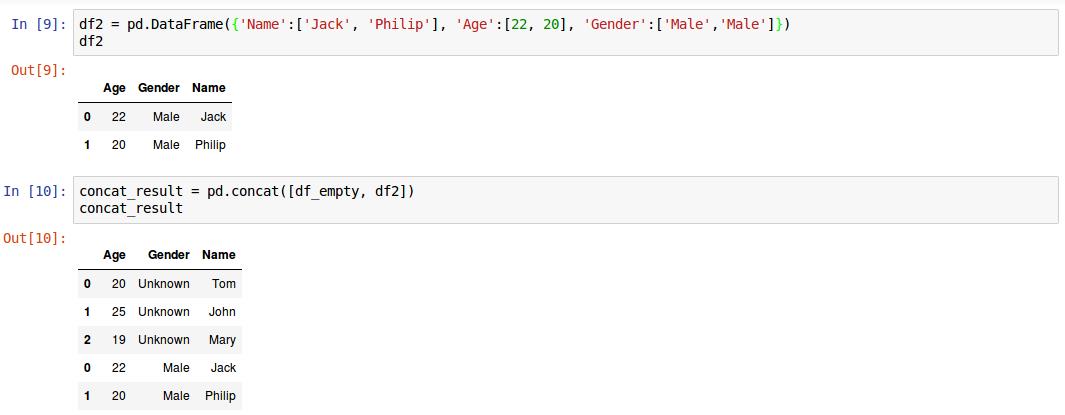
如果需要指定列的顺序,则可以使用columns属性:
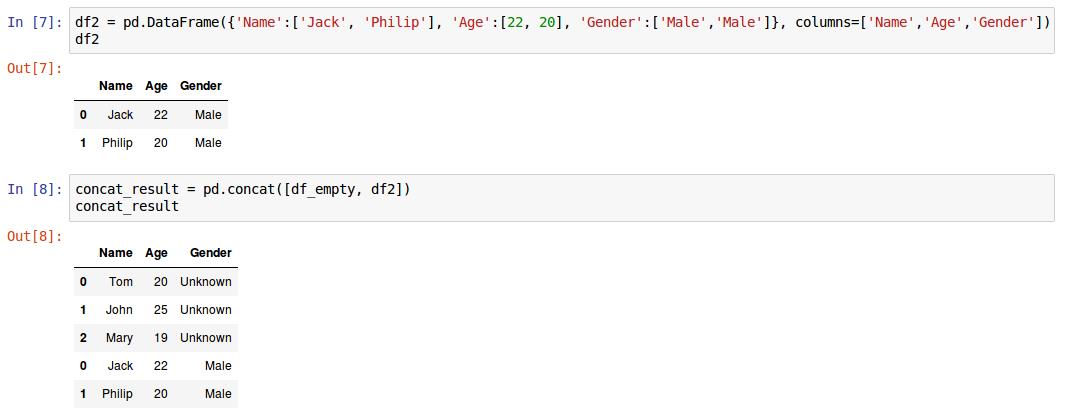
9. 判断dataframe中的某一列是否包含特定值,可以使用‘in’。
例如,下面的例子旨在判断名叫‘Jack’的客户是否存在。如果存在,则输出其对应的年龄信息。
if 'Jack' in concat_result['Name'].values:
print( concat_result.loc[(concat_result['Name']=='Jack')]['Age'].values)
##等价于 print( concat_result[(concat_result['Name']=='Jack')]['Age'].values)
else:
print("No such person.")

以上是关于算法之美_源代码发布的主要内容,如果未能解决你的问题,请参考以下文章