word2vec安装以及使用
Posted 鸣灭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了word2vec安装以及使用相关的知识,希望对你有一定的参考价值。
一、安装
我使用的是在linux环境下运行的,所以首先去下载linux环境模拟器,下载的是cygwin因为要使用make命令工具,所以安装时要选中Devel与utils模块,默认安装没有安装make命令工具。记住一定要选中这两个模块,不然没有make命令工具没法运行makefile。
二、作用
我知道word2vec可以查看输入一个词,查看相近词比如这样
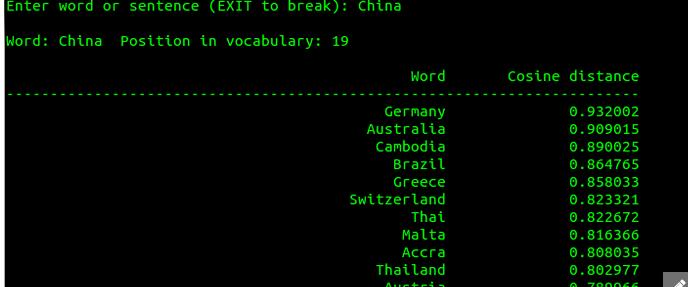
也可以对文本进行聚类,在其他人博客上看的说是使用k均值聚类
比如这样

聚完类也可以对聚类结果排序
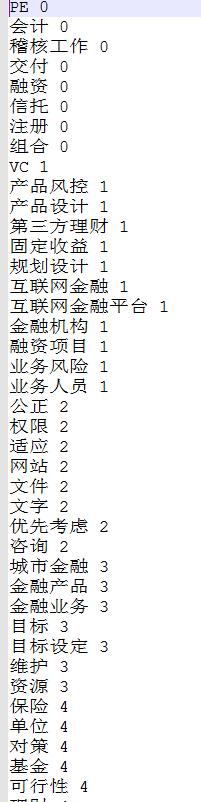
最后一个功能是短语分析没用过
可以参见http://www.cnblogs.com/hebin/p/3507609.html
这个博客
三、语料文件要求
语料文件要使用空格将词语分开,分词工具可是使用中科院分词工具。我会写一篇中科院分词工具的使用,大家可以参见。使用utf-8编码,可是使用Notepade++等工具将文件改变编码。
四、使用
进入linux环境模拟器输入 cd D:/word2vec/w2v/trunk这是进入文件下的指令,然后输入make等一会文件中会出现一些其他的文件,然后就可以使用了。将训练文件放到当前目录下。
使用指令

-train 训练数据
-output 结果输入文件,即每个词的向量
-cbow 是否使用cbow模型,0表示使用skip-gram模型,1表示使用cbow模型,默认情况下是skip-gram模型,cbow模型快一些,skip-gram模型效果好一些
-size 表示输出的词向量维数
-window 为训练的窗口大小,8表示每个词考虑前8个词与后8个词(实际代码中还有一个随机选窗口的过程,窗口大小<=5)
-negative 表示是否使用NEG方,0表示不使用,其它的值目前还不是很清楚
-hs 是否使用HS方法,0表示不使用,1表示使用
-sample 表示 采样的阈值,如果一个词在训练样本中出现的频率越大,那么就越会被采样
-binary 表示输出的结果文件是否采用二进制存储,0表示不使用(即普通的文本存储,可以打开查看),1表示使用,即vectors.bin的存储类型
通过设置binary可以打开查看
文本聚类的语句
./word2vec -train resultbig.txt -output classes.txt -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 12 -classes 500 &
2 sort classes.txt -k 2 -n > classes_sorted_sogouca.txt
引用参考博客
http://www.cnblogs.com/hebin/p/3507609.html
http://blog.csdn.net/heyongluoyao8/article/details/43488765
以上是关于word2vec安装以及使用的主要内容,如果未能解决你的问题,请参考以下文章
wiki中文语料+word2vec (python3.5 windows win7)
Windows下C extension not loaded for Word2Vec, training will be slow.解决方法