[开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [二] 最基本,最自由的使用方式
Posted Spread your wings and prepare
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [二] 最基本,最自由的使用方式相关的知识,希望对你有一定的参考价值。
[DotnetSpider 系列目录]
使用环境
-
Visual Studio 2017
-
.NET 4.5 or later or .NET Core
概述
在上一篇也讲到过,实现一个完整的爬虫需要4大模块:下载器(已有实现),URL调度(已有实现),数据抽取(需要自己实现),数据存储(需要自己实现),因此,只需要实现数据抽取、数据存储这两个模块就可以完成一个爬虫了。
新建一个Console 项目
- 右键项目的Manage NuGet Packages(管理NuGet包)
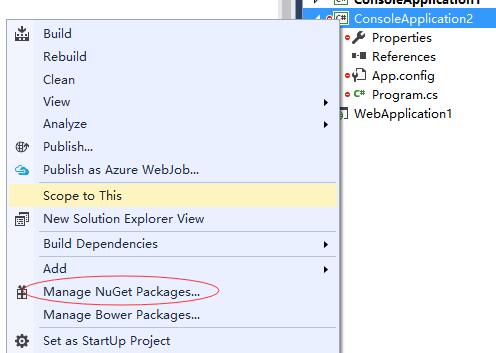
-
搜索DotnetSpider2, 从结果列表中选中DotnetSpider2.Core并安装到控制台项目中
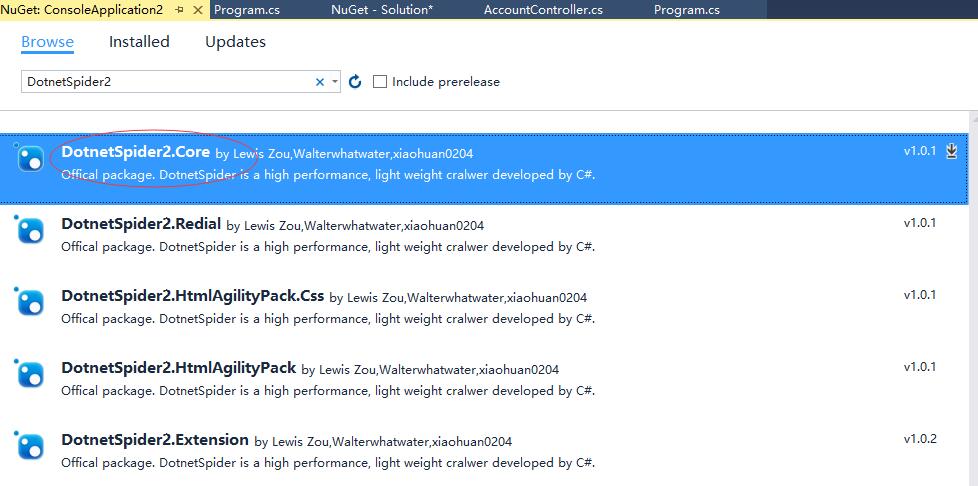
定义数据对象
public class YoukuVideo { public string Name { get; set; } }
定义数据抽取(实现 IPageProcessor 接口)
public class YoukuPageProcessor : BasePageProcessor { protected override void Handle(Page page) { // 利用 Selectable 查询并构造自己想要的数据对象 var totalVideoElements = page.Selectable.SelectList(Selectors.XPath("//div[@class=\'yk-pack pack-film\']")).Nodes(); List<YoukuVideo> results = new List<YoukuVideo>(); foreach (var videoElement in totalVideoElements) { var video = new YoukuVideo(); video.Name = videoElement.Select(Selectors.XPath(".//img[@class=\'quic\']/@alt")).GetValue(); results.Add(video); } // Save data object by key. 以自定义KEY存入page对象中供Pipeline调用 page.AddResultItem("VideoResult", results); } }
需要注意的是
- Page 对象中Selectable属性是由下载的html构造的选择器容器,调用Seletable的接口就可以进行Xpath,Css, JsonPath,Regex的查询
- Selectable的GetValue传入true时会把结果去HTML标签化
- 把组装好的对象,如上面的 YoukuVideo List, 保存到page的ResultItem中,并指定一个唯一的Key
定义数据管道(继承BasePipeline这个抽象类)
数据管道可以通过在PageProcessor中指定的唯一Key,取出需要处理的数据存入想要的数据库或文件中
public class YoukuPipeline : BasePipeline { private static long count = 0; public override void Process(ResultItems resultItems) { StringBuilder builder = new StringBuilder(); foreach (YoukuVideo entry in resultItems.Results["VideoResult"]) { count++; builder.Append($" [YoukuVideo {count}] {entry.Name}"); } Console.WriteLine(builder); // Other actions like save data to DB. 可以自由实现插入数据库或保存到文件 } }
初始化起始链接并运行
通过AddStartUrl可以添加爬虫的起始链接后,调用Run方法运行爬虫
// Config encoding, header, cookie, proxy etc... 定义采集的 Site 对象, 设置 Header、Cookie、代理等 var site = new Site { EncodingName = "UTF-8", RemoveOutboundLinks = true }; for (int i = 1; i < 5; ++i) { // Add start/feed urls. 添加初始采集链接 site.AddStartUrl($"http://list.youku.com/category/show/c_96_s_1_d_1_p_{i}.html"); } Spider spider = Spider.Create(site, // use memoery queue scheduler. 使用内存调度 new QueueDuplicateRemovedScheduler(), // use custmize processor for youku 为优酷自定义的 Processor new YoukuPageProcessor()) // use custmize pipeline for youku 为优酷自定义的 Pipeline .AddPipeline(new YoukuPipeline()); spider.Downloader = new HttpClientDownloader(); spider.ThreadNum = 1; spider.EmptySleepTime = 3000; // Start crawler 启动爬虫 spider.Run();
运行结果
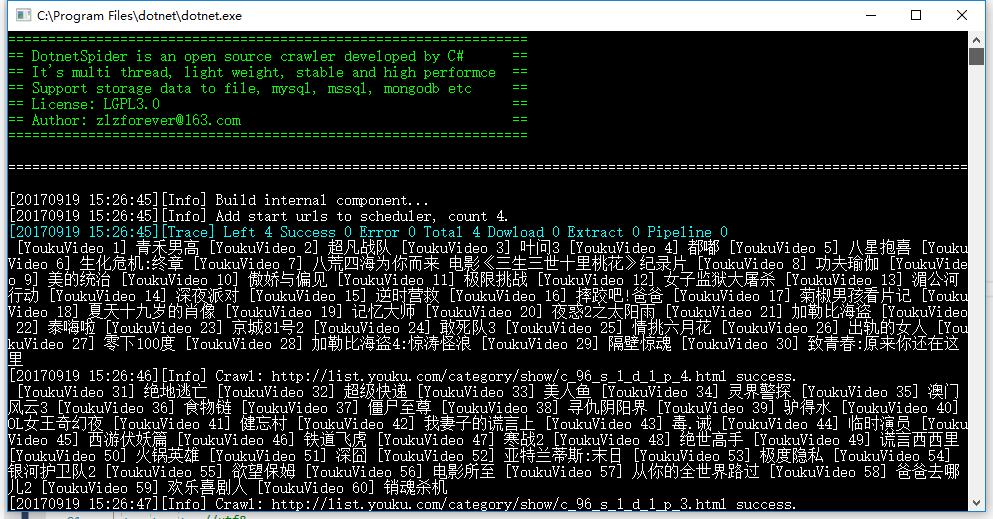
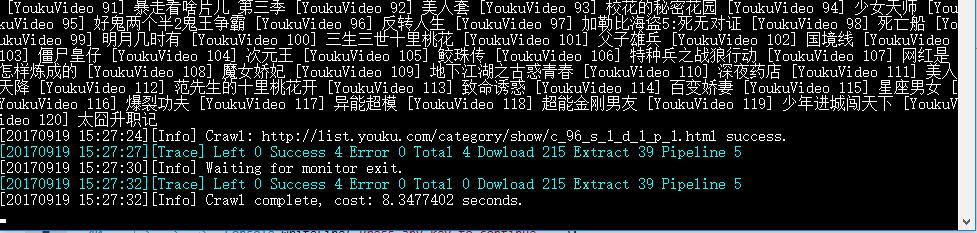 设置目标页抽取
设置目标页抽取
以上只是采集了初始的一个链接,如何达到翻页(遍历)效果继续采集直的最后一页呢?只需要在PageProccessor中解析出符合规则的目标页,并加入到Page对象的TargetRequests这个List中即可。我们做如下改动:
public class YoukuPageProcessor : BasePageProcessor { protected override void Handle(Page page) { // 利用 Selectable 查询并构造自己想要的数据对象 var totalVideoElements = page.Selectable.SelectList(Selectors.XPath("//div[@class=\'yk-pack pack-film\']")).Nodes(); List<YoukuVideo> results = new List<YoukuVideo>(); foreach (var videoElement in totalVideoElements) { var video = new YoukuVideo(); video.Name = videoElement.Select(Selectors.XPath(".//img[@class=\'quic\']/@alt")).GetValue(); results.Add(video); } // Save data object by key. 以自定义KEY存入page对象中供Pipeline调用 page.AddResultItem("VideoResult", results); // Add target requests to scheduler. 解析需要采集的URL foreach (var url in page.Selectable.SelectList(Selectors.XPath("//ul[@class=\'yk-pages\']")).Links().Nodes()) { page.AddTargetRequest(new Request(url.GetValue(), null)); } } }
重新运行爬虫后,可以看到已经实现的翻页
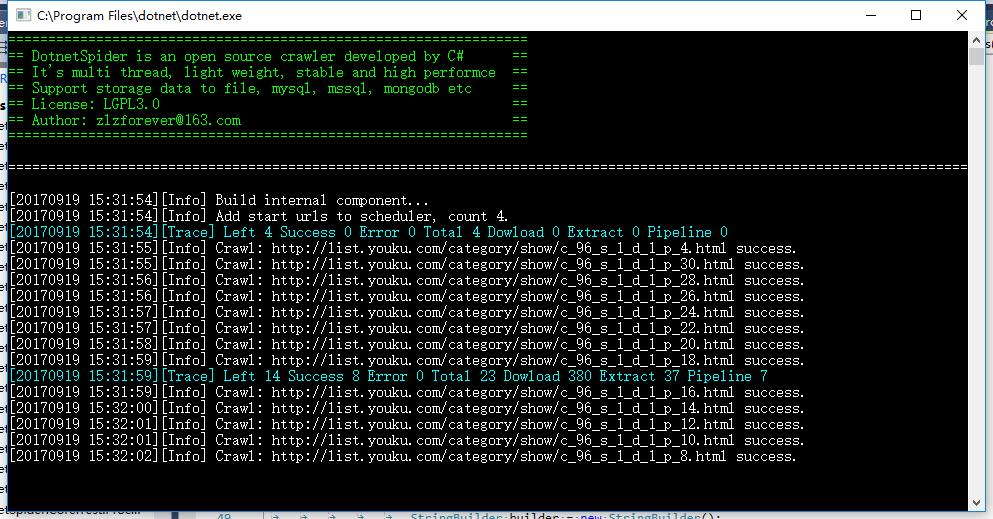
![<p>以上是关于[开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [二] 最基本,最自由的使用方式的主要内容,如果未能解决你的问题,请参考以下文章</p>
</article> </div> </div> </div> </section>
</div>
</div>
<script type=](https://cdn.jsdelivr.net/emojione/assets/png/1F603.png)