深度学习模型相关知识
Posted 小丑_jk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习模型相关知识相关的知识,希望对你有一定的参考价值。
参考:https://blog.csdn.net/lanran2/article/details/60143861
ROI pooling:
ROI是Regin of Interest的简写,指的是特征图上的框,特点在于输入特征图尺寸不固定,但是输出特征图尺寸固定。
这里加一个Fast RCNN和Faster RCNN在ROI步骤前的区别:
1)在Fast RCNN中,RoI是指Selective Search产生的候选框在特征图的映射
2)在Faster RCNN中,RoI是由RPN产生的候选框在特征图的映射
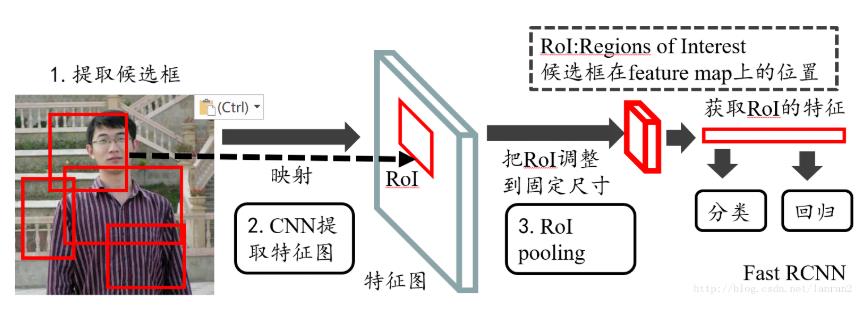
如上为Fast RCNN的整体结构,经过提取候选框后完成在feature map上的映射,再经RoI pooling来将多个不同尺寸的RoI统一到相同的尺寸,然后再提取特征。
RoI pooling的输出:
输出的是batch个vector,其中batch的值是在上面的例子中是单个给定像素图中RoI的个数,vector的大小为channel*w*h(这里的channel也就是上面红色小矩阵的厚度),也就是说RoI Pooling的过程就是将大小不同的box矩形框,映射成固定大小(w*h)的矩形框。
参考:https://blog.csdn.net/zijin0802034/article/details/77685438
Bounding-Box regression (边框回归):
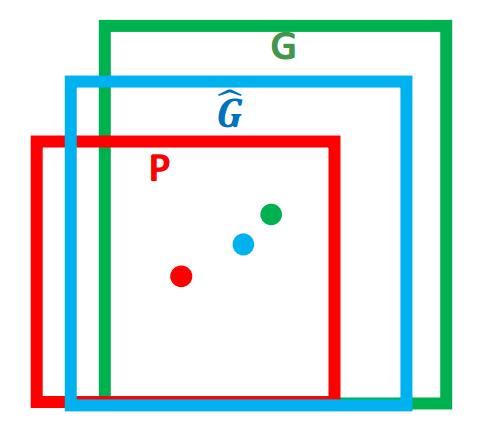
这里以如下的图为例:

上图中,绿色的框表示Ground Truth,红色框为Selection Search 或者RPN提取的Regin Proposal;观察上图可以发现,这里的IoU<0.5(两个bounding box的重叠程度),因而可以判定为未正确监测出飞机,所以我们需要对红色框进行微调,Bounding-box regression就是用于这个窗口的微调过程。
对于窗口一般采用四维向量(x,y,w,h)来表示,其中x,y表示窗口的中心点坐标,w,h表示中心点坐标的宽和高。
Bounding-box regression的作用在于将Regin Proposal 经过映射后得到和真实窗口G更接近的回归窗口![]() ,也就是说边框回归的目的在于为给定
,也就是说边框回归的目的在于为给定![]() 寻找映射f,使得
寻找映射f,使得![]() ,以做到
,以做到![]() 。
。
如上的f(x)过程包括几个步骤:平移、缩放
1、平移的步骤(Δx,Δy):
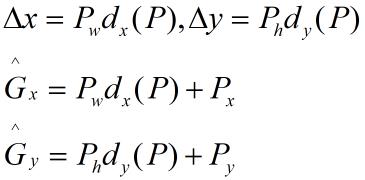
2、然后再做尺度的缩放(Sw,Sh):
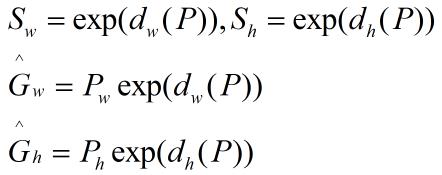
输入部分:
Regin Prosoal里P=(Px,Py,Pw,Ph),输入是这个窗口对应的CNN特征,以及Ground Truth,也即下边提到的t*=(tx,ty,tw,th)
输出部分:
需要进行的平移变换和尺度缩放的dx(P) ,dy(P),dw(P) ,dh(P),或者说 Δx,Δy,Sw,Sh
这里P经过dx(P) ,dy(P),dw(P) ,dh(P)得到的是预测值![]() ,理论上来说,这4个值应该是经过Ground Truth和Proposal计算得到的真正需要的平移量(tx,ty)和(tw,th)。
,理论上来说,这4个值应该是经过Ground Truth和Proposal计算得到的真正需要的平移量(tx,ty)和(tw,th)。
其中tx,ty,tw,th的表达式如下:
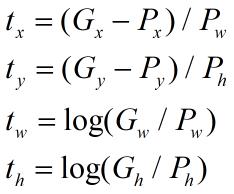
那么目标函数可以表示为![]() ,其中
,其中![]() 是输入Proposal的特征向量,w*是要学习的参数(*表示x,y,w,h,也即每个变换对应一个目标函数),d*(P)是得到的预测值。
是输入Proposal的特征向量,w*是要学习的参数(*表示x,y,w,h,也即每个变换对应一个目标函数),d*(P)是得到的预测值。
目的是为了使预测值和真实值t*=(tx,ty,tw,th)的差异最小,如此得到损失函数:
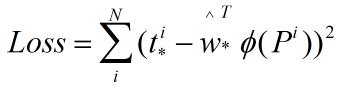
函数优化目标为:
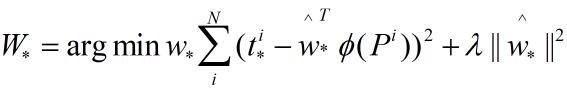
通过梯度下降法得到优化权重w*
参考:http://lib.csdn.net/article/deeplearning/61641
参考:https://www.zhihu.com/question/42205480/answer/155759667
参考:https://blog.csdn.net/williamyi96/article/details/77648047
Regin Proposal Networks(RPN):
Region Proposal Networks是Faster RCNN提出的proposal生成网络,代替了RCNN和Fast-RCNN中的selective search方法。
在介绍RPN之前,首先介绍anchors,这是一组长宽比分别为:width:height=[1:1,1:2,2:1]三种情况的矩阵,(按照其他博文的意思是取3种尺寸的该3种比例,得到9个面积尺寸)以如下为例:

anchor的本质是SPP(spatial pyramid pooling)思想的逆向,SPP本身是用于将不同尺寸的输入resize成相同尺寸的输出,因而SPP的逆向就是将相同尺寸的输出倒推得到不同尺寸的输入。
这里获取的anchors用于遍历Conv-layers计算所得的feature maps,为每一个点都配备这
由于在进行RPN前已经进行了一系列的卷积、池化、relu,假定这里得到的feature为:51x39x256(256为层数)
在这个特征参数基础上,通过3x3的滑动窗口,在51x39的区域上滑动,stride=1,padding=2,那么就得到51x39个3x3的窗口。
对于每个3x3的窗口,计算滑动窗口中心点对应的原始图片的中心点,假定该3x3的窗口是从原始图片经SPP池化得到,这个池化的面积和比例就是一个个anchor。也即对于每个3x3窗口,作者假定它来自9种不同原始区域的池化,这些池化在原始图片的中心点完全一致。也即3x3窗口中心点对应原始图片的中心点。如此来在每个窗口位置根据9个不同比例、不同面积的anchor,逆向推导其对应的原始图的区域,这个区域的尺寸及坐标。这个区域就是我们想要的proposal,通过滑动窗口和anchor,得到了51x39x9个原始图片的proposal;由于每个proposal我们只输出6个参数:每个proposal和ground truth比较得到的前景概率和背景概率(2个参数)(对应图上的cls);由于每个proposal和ground truth位置和尺寸的差异,从proposal平移缩放得到ground truth需要4个平移缩放参数;如下图所示:
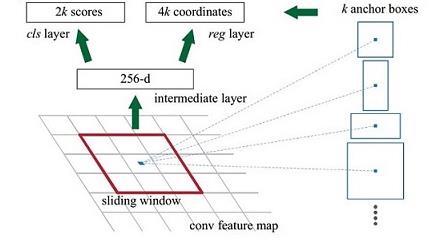
其中这里从proposal平移缩放到ground truth就涉及到上一个模块提到的bounding box regression,用于修正检测框位置。
假设有k个anchor,每个anchor分foreground和background,所以cls=2k scores,每个anchor对应[x,y,w,h]的4个偏移量,故reg=4k coordinates
以上是关于深度学习模型相关知识的主要内容,如果未能解决你的问题,请参考以下文章