Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考相关的知识,希望对你有一定的参考价值。
本期内容 :
- 数据接收架构设计模式
- 数据接收源码彻底研究
一、Spark Streaming数据接收设计模式
Spark Streaming接收数据也相似MVC架构:
1、 Mode相当于Receiver存储数据,C级别的,Receiver是个抽象因为他有好多的Receiver
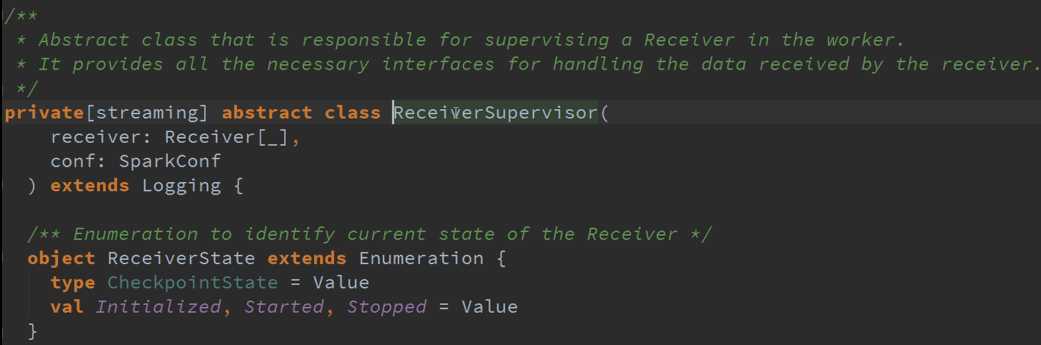
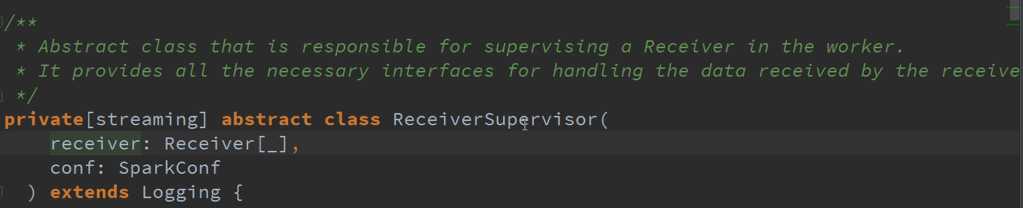
2、 ReceiverSupervisor 是控制器,因为Receiver启动是靠ReceiverSuperior启动的,及接收到的数据交给ReceiverSuperior存储数据的
3、 Driver会获得源数据,即获得界面,操作的时候是通过界面再操作底层的业务逻辑(拿到了源数据,实质上就是操作了真正数据,即界面)
基于Reverse的角度考虑,Spark Streaming接收数据首先会有个循环器,循环器会不断的次序接收数据,接收到数据后需要存储数据,存储完成数据需要汇报给Driver,接收到数据如果不向Driver汇报的话,Driver在调度的时候可能就不会把接收到的数据计入调度任务中,当Driver接收到接收源数据的相关信息,如 ID、分片等内容,Driver会根据具体数据情况分配Job,Driver本身就是基于原有数据来构造出来的,并分配资源的。
二、 Spark Streaming数据接收源码
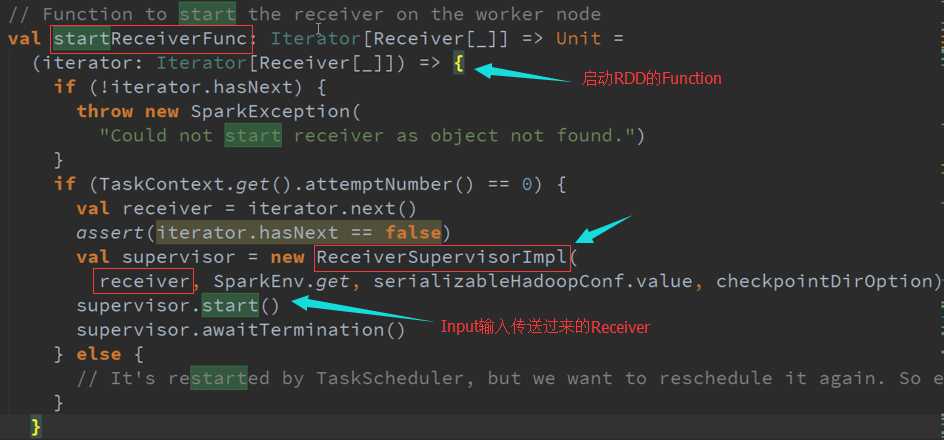
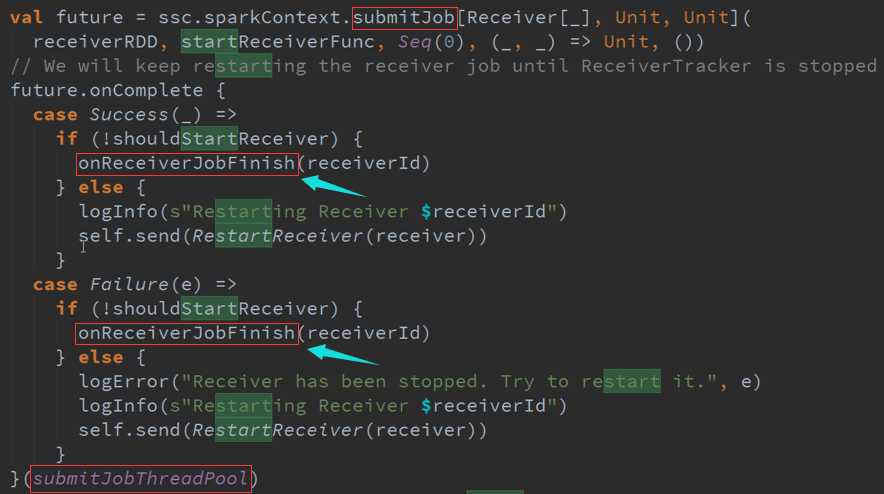
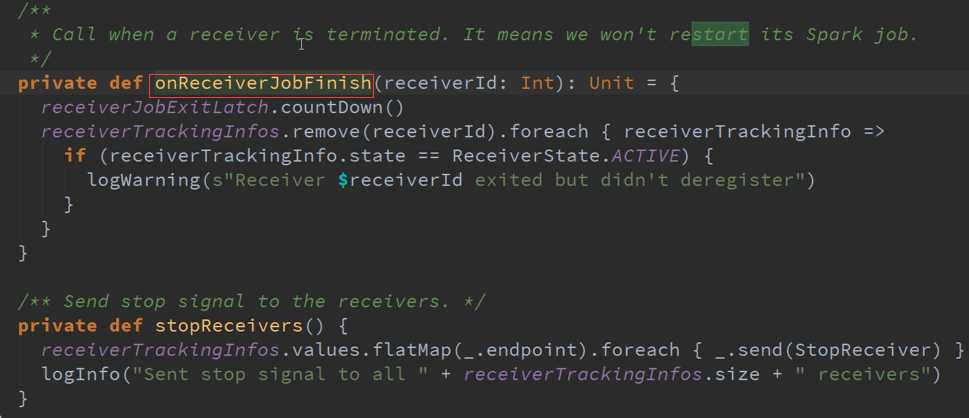
ReceiverTracker是通过发送一个又一个的Job,每个Job只有一个的Teark,每个Teark里面只有ReceiverSupervisor 以函数功能角度启动每一个Receiver的。
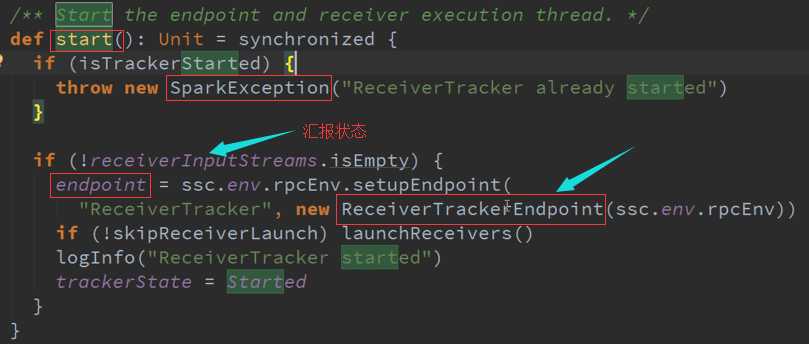

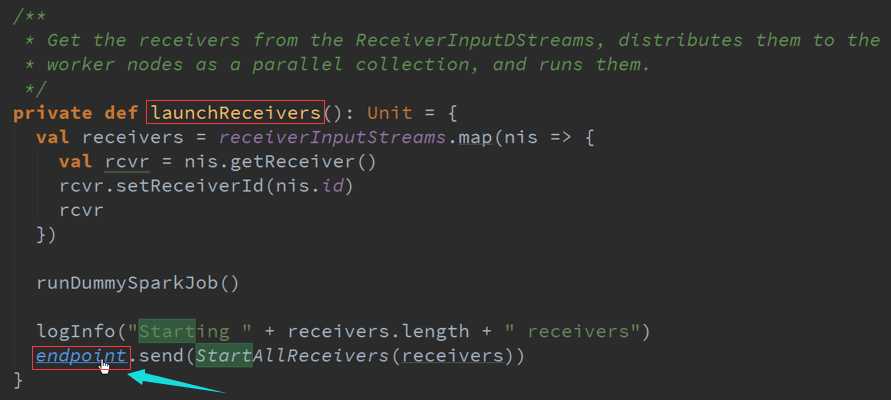
LaunchReceivers处理流程源码 :
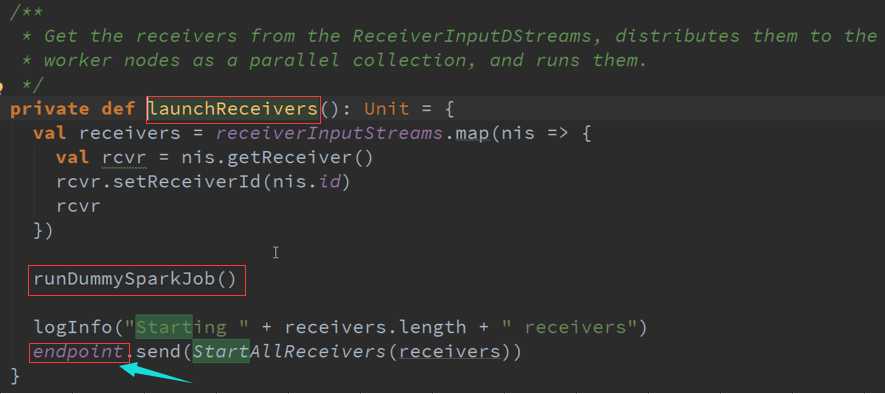


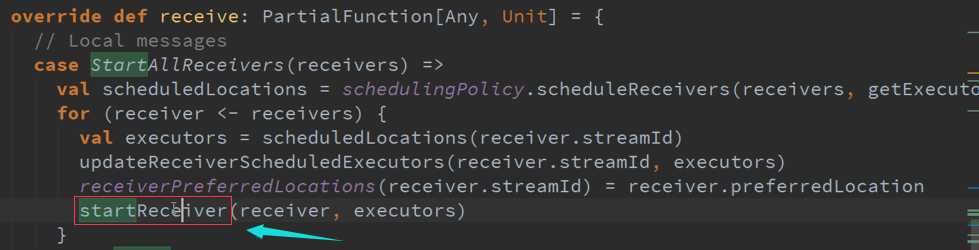
确认数据到达ReceiverTracker
Receiver的产生源码 :
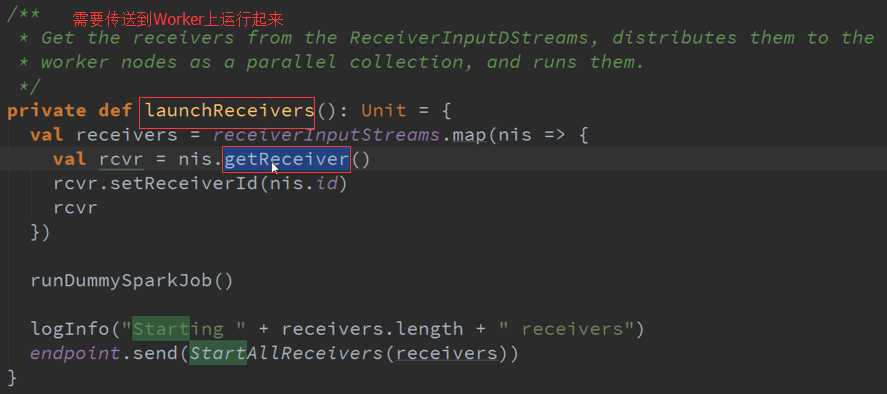
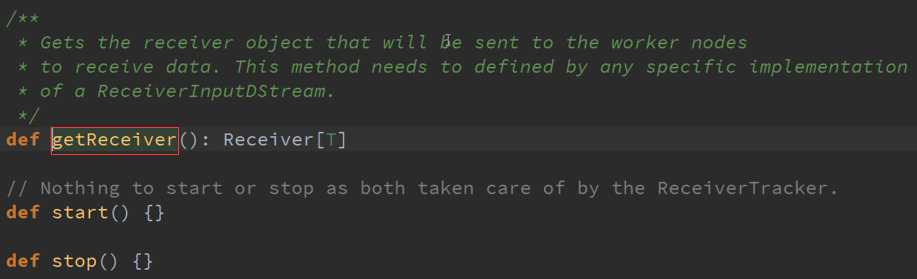
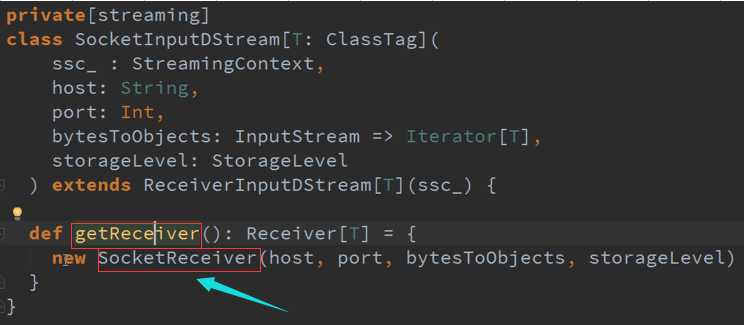
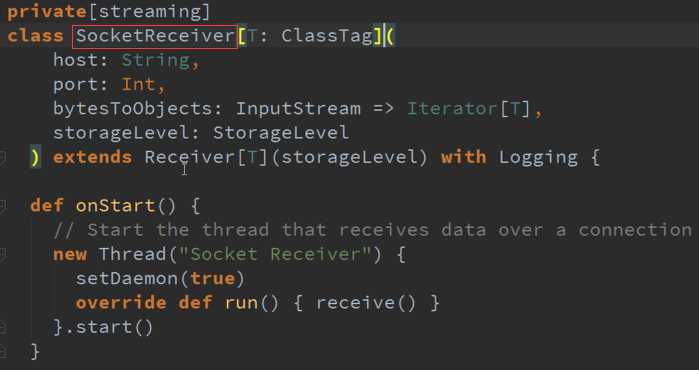
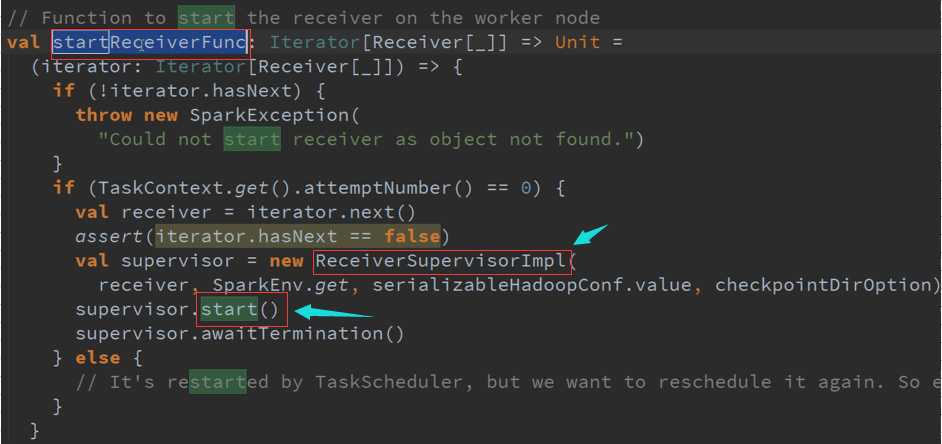
专门为创建Receiver而做的RDD源码 :
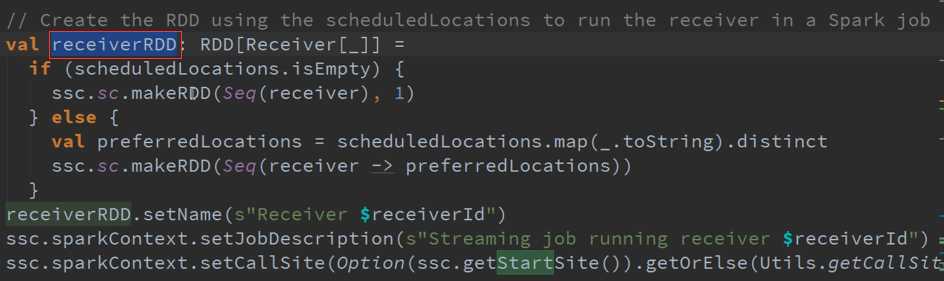
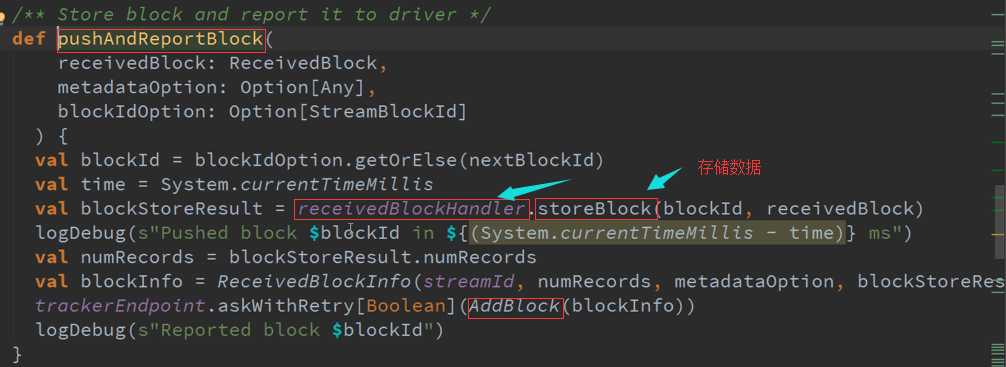
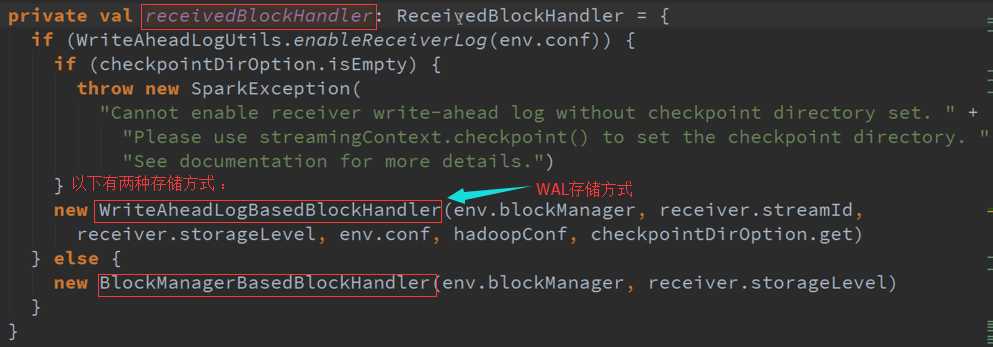
ReceiverSupervisor数据存储源码 :
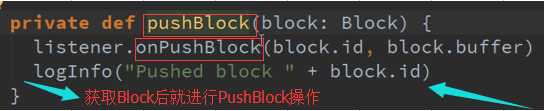
Receiver接收到的数据会给ReceiverSupervisor ,然后ReceiverSupervisor存储数据再把信息汇报给ReceiverTracker(其实是汇报给RPC)。
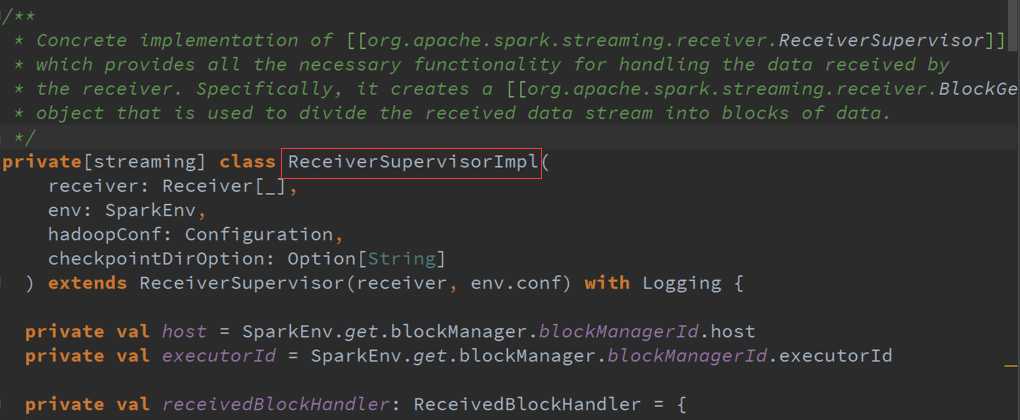
两个构造器 :

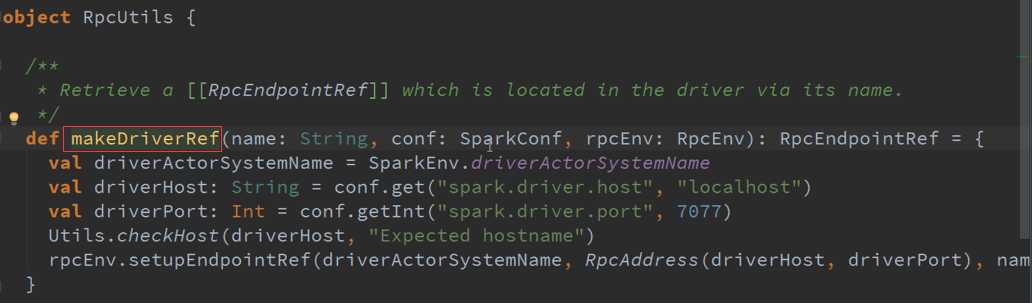
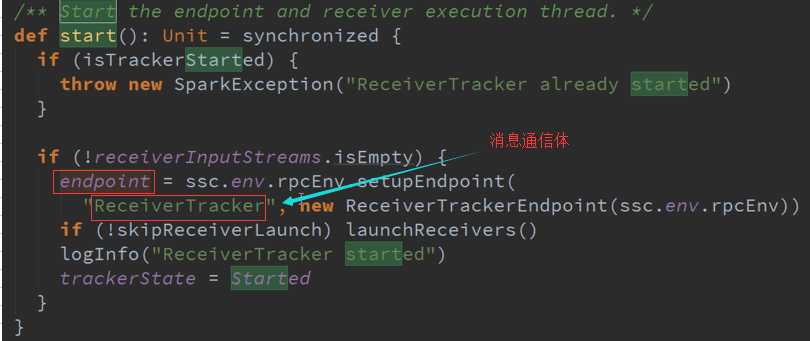
SetupEndpoint 消息循环体源码:
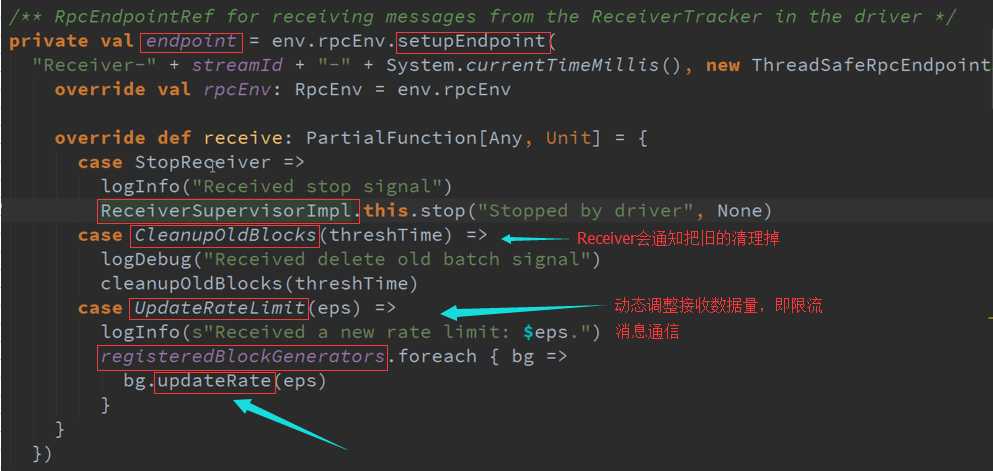
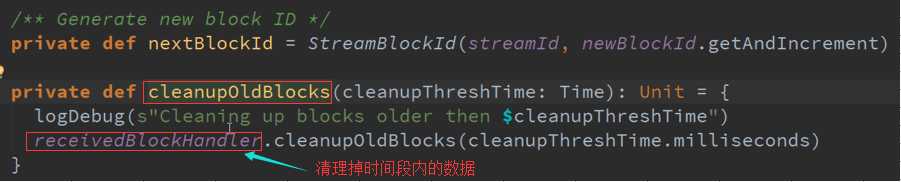
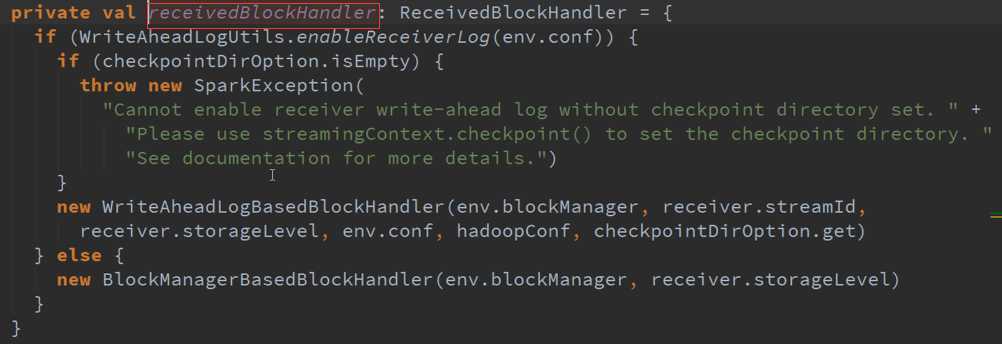
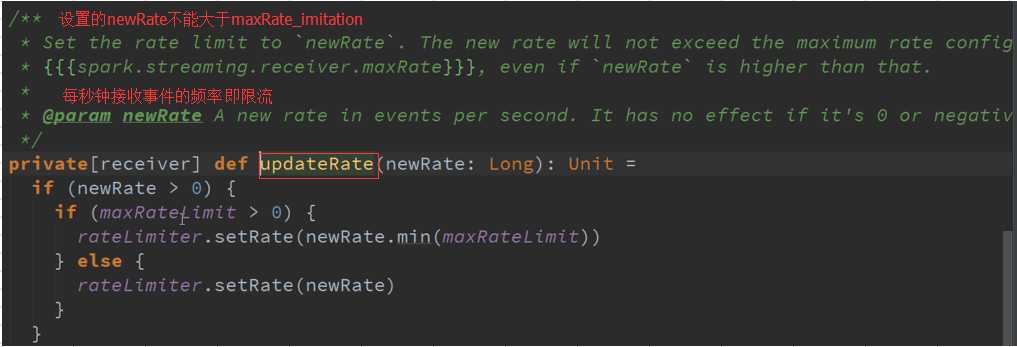
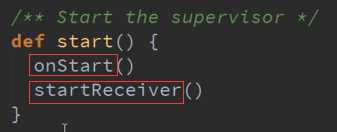
Start启动接收数据 源码 :



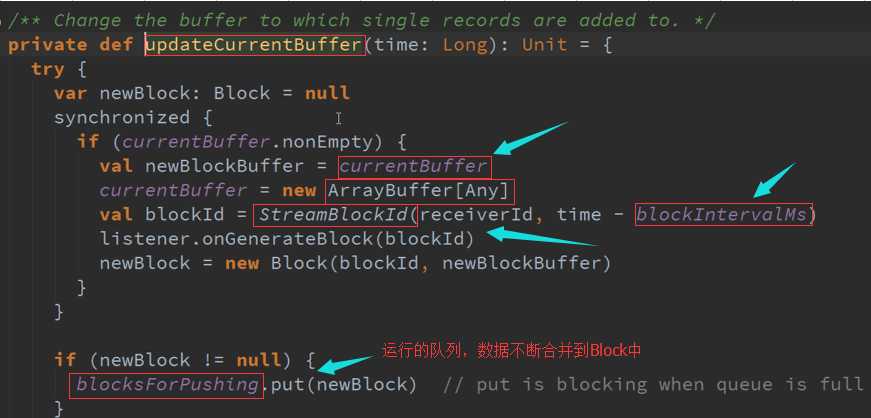
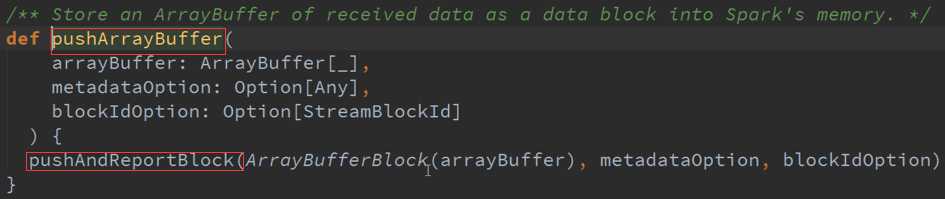
数据传入Buffer 并更新到Block 源码 :

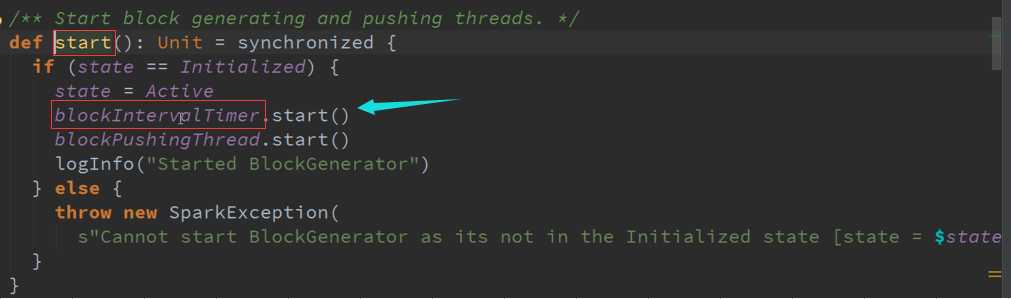

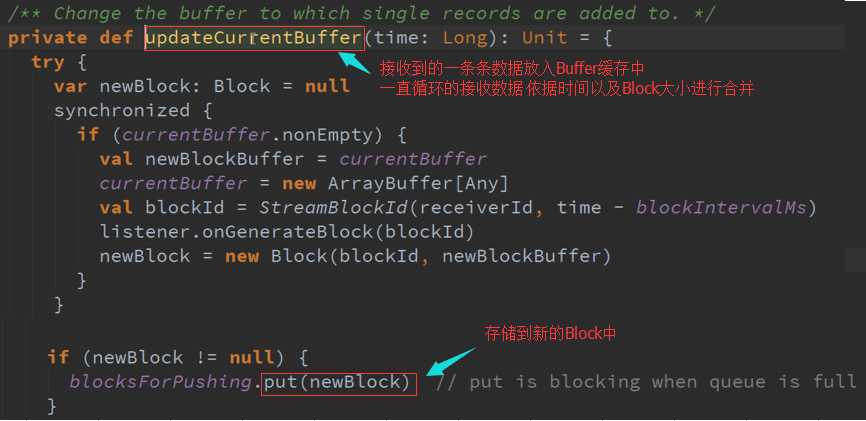
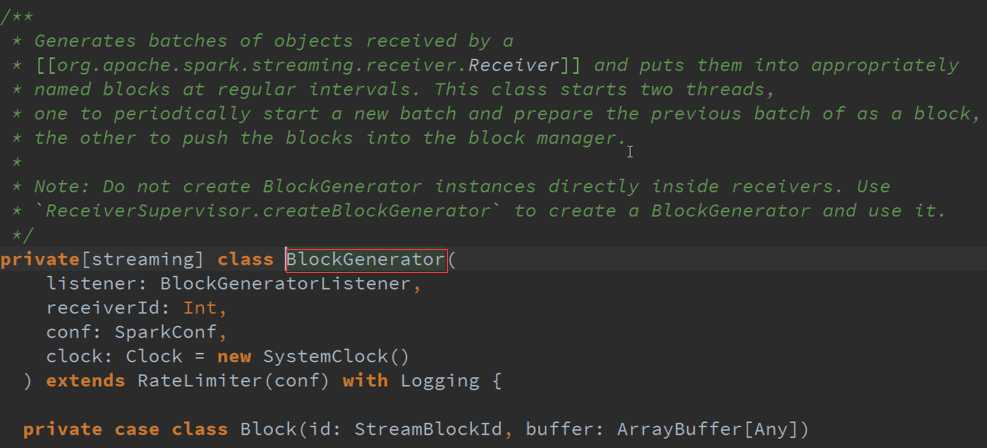
把Receiver接收到的数据生成以Batches的类型存在就是Block的形式存在,并存储在适当的地方以特定的频率启动两条线程:
1、 一条线程专门把Receiver接收到的数据合并成Block
2、 另外一条就是把数据合并后的Block提交给manager去存储
上层框架存储数据需要通过manager去存储,不要在Receiver中启动BlockGenerator ,担心有延迟来不及处理你的数据,可能Receiver存储数据时会报错。
限流BlockGenerator是继承RateLimiter ,不能直接限定流入的数据,但是可以限定存储的数据流速度,相当于限定了流动的数据。
BlockGenerator是由CreateBlockGenerator产生的 :


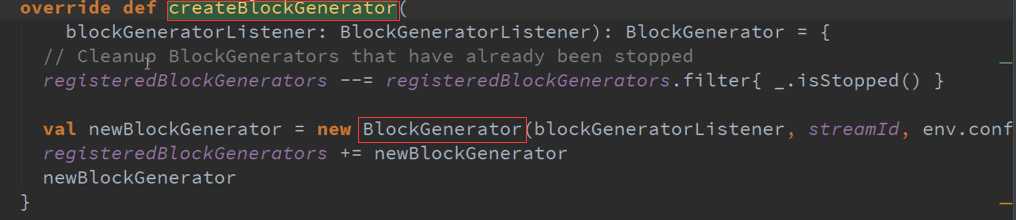
StartReceiver 接收数据与存储数据源码 :
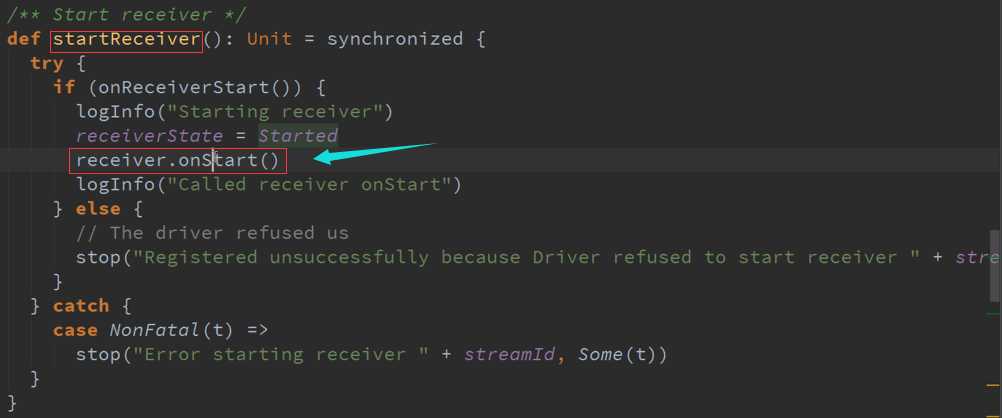
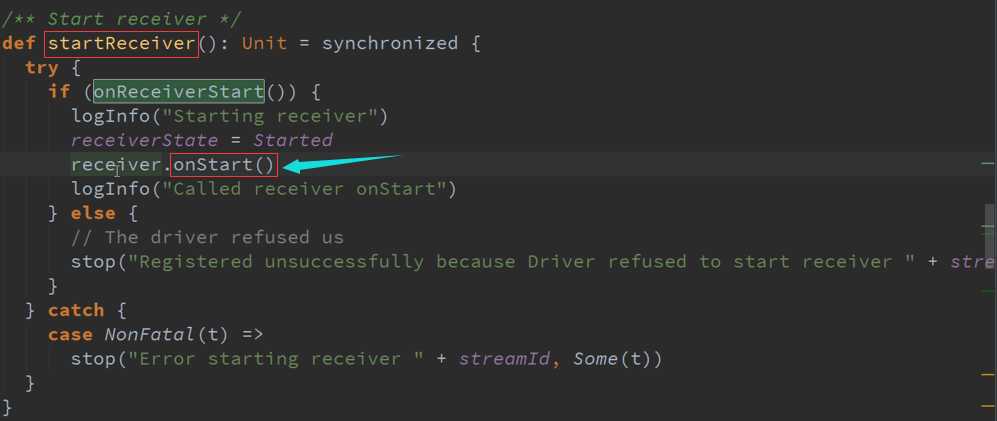
进入Start方法会有不同类型分别进行启动,
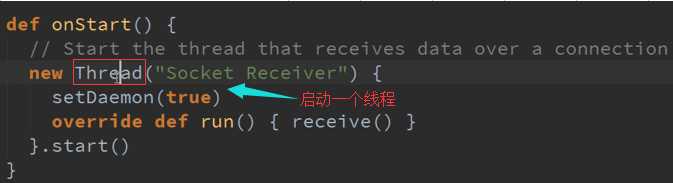
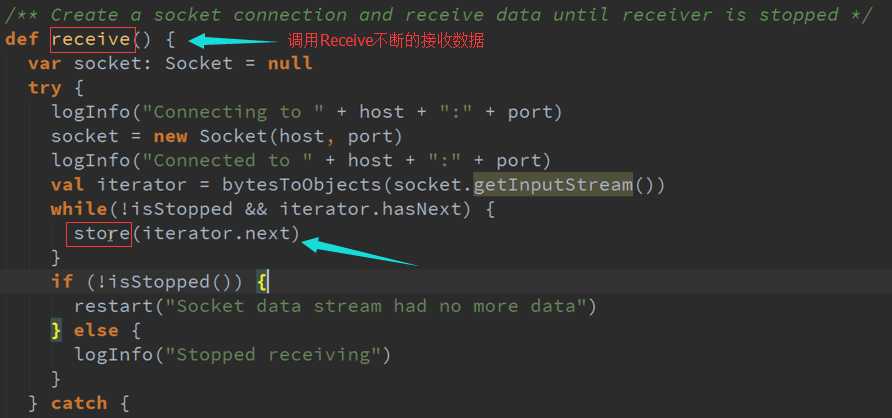
系统调用这个函数必须初始化所有资源包括线程、Buffer来接收数据,而且必须是非阻塞的,存储数据的话需要调用Spark的Store



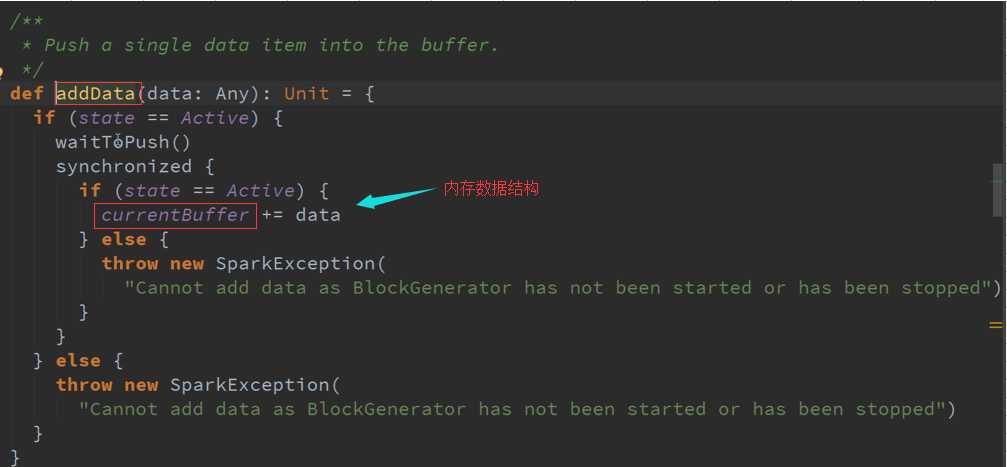

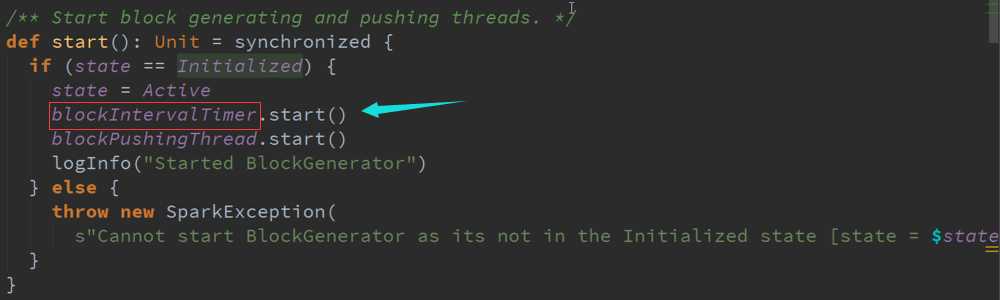

根据时间频率生成一个个的Block,并把数据不断合并起来的

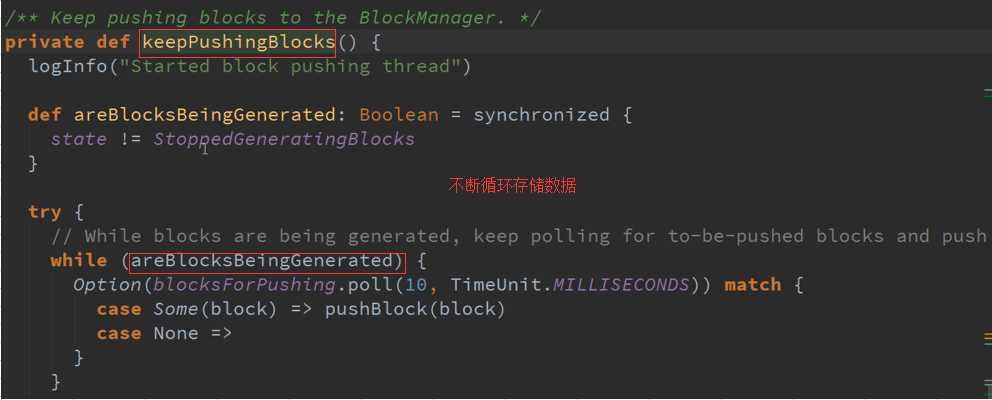
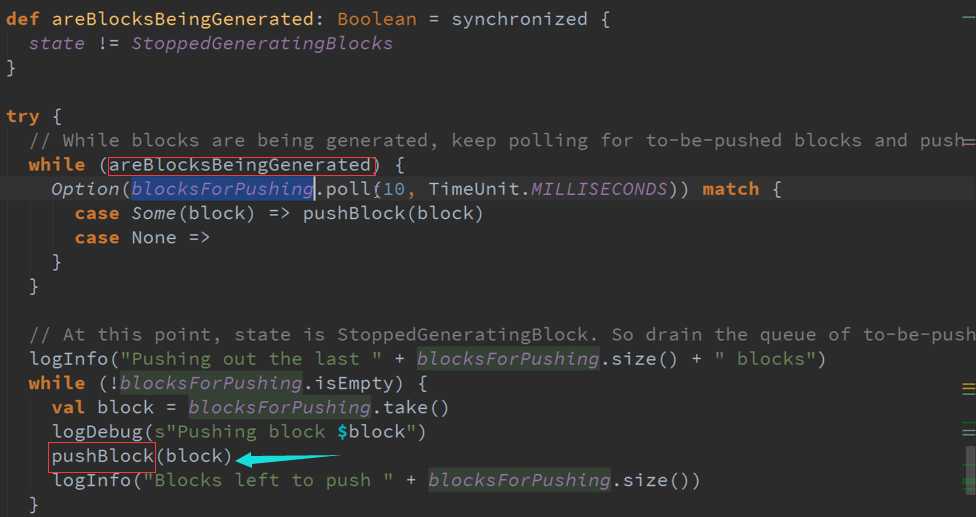
备注:
-
- 资料来源于:王家林(Spark发行版本定制)
- 新浪微博:http://www.weibo.com/ilovepains
以上是关于Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考的主要内容,如果未能解决你的问题,请参考以下文章
第10课:Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考
第10课:Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考
(版本定制)第10课:Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考