kafka源码分析Metadata的数据结构与读取更新策略
Posted 强迫疒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka源码分析Metadata的数据结构与读取更新策略相关的知识,希望对你有一定的参考价值。
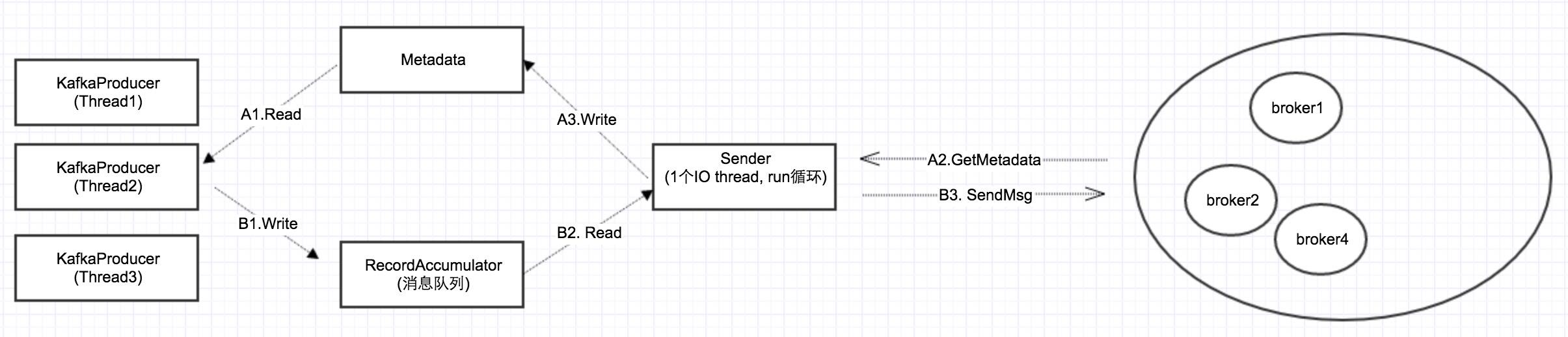
一、基本思路
异步发送的基本思路就是:send的时候,KafkaProducer把消息放到本地的消息队列RecordAccumulator,然后一个后台线程Sender不断循环,把消息发给Kafka集群。
要实现这个,还得有一个前提条件:就是KafkaProducer/Sender都需要获取集群的配置信息Metadata。所谓Metadata,也就是在上一篇所讲的,Topic/Partion与broker的映射关系:每一个Topic的每一个Partion,得知道其对应的broker列表是什么,其中leader是谁,follower是谁。
二、2个数据流
所以在上图中,有2个数据流:
Metadata流(A1,A2,A3):Sender从集群获取信息,然后更新Metadata; KafkaProducer先读取Metadata,然后把消息放入队列。
消息流(B1, B2, B3)
从上图可以看出,Metadata是多个producer线程读,一个sender线程更新,因此它必须是线程安全的
三、Metadata的线程安全性
从下面代码也可以看出,它的所有public方法都是synchronized:
1 public final class Metadata {
2 。。。
3 public synchronized Cluster fetch() {
4 return this.cluster;
5 }
6 public synchronized long timeToNextUpdate(long nowMs) {
7 。。。
8 }
9 public synchronized int requestUpdate() {
10 。。。
11 }
12 。。。
13 }
四、Metadata的数据结构
1 public final class Metadata { 2 ... 3 private final long refreshBackoffMs; //更新失败的情况下,下1次更新的补偿时间(这个变量在代码中意义不是太大) 4 private final long metadataExpireMs; //关键值:每隔多久,更新一次。缺省是600*1000,也就是10分种 5 private int version; //每更新成功1次,version递增1。这个变量主要用于在while循环,wait的时候,作为循环判断条件 6 private long lastRefreshMs; //上一次更新时间(也包含更新失败的情况) 7 private long lastSuccessfulRefreshMs; //上一次成功更新的时间(如果每次都成功的话,则2者相等。否则,lastSuccessulRefreshMs < lastRefreshMs) 8 private Cluster cluster; //集群配置信息 9 private boolean needUpdate; //是否强制刷新 10 、 11 ... 12 }
以上是关于kafka源码分析Metadata的数据结构与读取更新策略的主要内容,如果未能解决你的问题,请参考以下文章