理解netty对protocol buffers的编码解码
Posted Tank的技术博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理解netty对protocol buffers的编码解码相关的知识,希望对你有一定的参考价值。
一,netty+protocol buffers简要说明
Netty是业界最流行的NIO框架之一
优点:
1)API使用简单,开发门槛低;
2)功能强大,预置了多种编解码功能,支持多种主流协议;
3)定制能力强,可以通过ChannelHandler对通信框架进行灵活的扩展;
4)性能高,通过与其它业界主流的NIO框架对比,Netty的综合性能最优;
5)成熟、稳定,Netty修复了已经发现的所有JDK NIO BUG,业务开发人员不需要再为NIO的BUG而烦恼;
6)社区活跃,版本迭代周期短,发现的BUG可以被及时修复,同时,更多的新功能会被加入;
7)经历了大规模的商业应用考验,质量已经得到验证。在互联网、大数据、网络游戏、企业应用、电信软件等众多行业得到成功商用,证明了它可以完全满足不同行业的商业应用。
Protocol Buffers是Google公司开发的一种以有效并可扩展的格式编码结构化数据的方式。
可用于数据存储、通信协议等方面,它不依赖于语言和平台并且可扩展性极强。
现阶段官方支持C++、JAVA、Python等三种编程语言,但可以找到大量的几乎涵盖所有语言的第三方拓展包。
优点
1)二进制消息,性能好/效率高(空间和时间效率都很不错)
2)proto文件生成目标代码,简单易用
3)序列化反序列化直接对应程序中的数据类,不需要解析后在进行映射(XML,JSON都是这种方式)
4)支持向前兼容(新加字段采用默认值)和向后兼容(忽略新加字段),简化升级
5)支持多种语言
二,认识varint
proto 消息格式如:Length + Protobuf Data (消息头+消息数据)
消息头描述消息数据体的长度。为了更减少传输量,消息头采用的是varint 格式。
什么是varint?
Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,会用两个字节。
例如整数1的表示,仅需一个字节:
0000 0001
例如300的表示,需要两个字节:
1010 1100 0000 0010
采 用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。
下图演示了 Google Protocol Buffer 如何解析两个 bytes。注意到最终计算前将两个 byte 的位置相互交换过一次,这是因为 Google Protocol Buffer 字节序采用 little-endian 的方式。
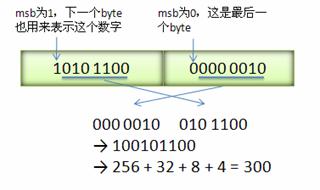
三,通信的编码解码
netty 默认提供了对protocol buffers 的支持,所以整合起来很简单。整合的关系,关键在于对编码解码的理解。
2.11 服务器端起用一个服务基本的代码如下:
EventLoopGroup boosGroup = new NioEventLoopGroup();
EventLoopGroup workGroup = new NioEventLoopGroup();
try {
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(boosGroup, workGroup).channel(NioserverSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 100).childHandler(new ChannelInitializer<Channel>() {
@Override
protected void initChannel(Channel ch) throws Exception {
ch.pipeline().addLast(new ProtobufVarint32FrameDecoder());// 解码(处理半包)
ch.pipeline().addLast(new ProtobufDecoder(MsgProto.Packet.getDefaultInstance()));
ch.pipeline().addLast(new ProtobufVarint32LengthFieldPrepender());//加长度
ch.pipeline().addLast(new ProtobufEncoder());// 编码
ch.pipeline().addLast(new ServerChannelHandlerAdapter());// 业务处理handler
}
});
// 绑定端口
ChannelFuture future = bootstrap.bind(2015).sync();
// 等待关闭
future.channel().closeFuture().sync();
} catch (Exception e) {
LOG.error("{}", e);
} finally {
boosGroup.shutdownGracefully();
workGroup.shutdownGracefully();
}
2.21 重点查看编码解码源码类,ProtobufVarint32FrameDecoder,ProtobufVarint32LengthFieldPrepender,ProtobufEncoder
编码类:
ProtobufEncoder:这里只是把proto 对象直接写入out
@Sharable
public class ProtobufEncoder extends MessageToMessageEncoder<MessageLiteOrBuilder> {
@Override
protected void encode(
ChannelHandlerContext ctx, MessageLiteOrBuilder msg, List<Object> out) throws Exception {
if (msg instanceof MessageLite) {
out.add(wrappedBuffer(((MessageLite) msg).toByteArray()));
return;
}
if (msg instanceof MessageLite.Builder) {
out.add(wrappedBuffer(((MessageLite.Builder) msg).build().toByteArray()));
}
}
}
关键是ProtobufVarint32LengthFieldPrepender类:
* BEFORE DECODE (300 bytes) AFTER DECODE (302 bytes)
* +---------------+ +--------+---------------+
* | Protobuf Data |-------------->| Length | Protobuf Data |
* | (300 bytes) | | 0xAC02 | (300 bytes) |
* +---------------+ +--------+---------------+
//数据格式为=数据长度(头部)+ 真正的数据
@Sharable
public class ProtobufVarint32LengthFieldPrepender extends MessageToByteEncoder<ByteBuf> {
@Override
protected void encode(
ChannelHandlerContext ctx, ByteBuf msg, ByteBuf out) throws Exception {
int bodyLen = msg.readableBytes();
int headerLen = CodedOutputStream.computeRawVarint32Size(bodyLen);
out.ensureWritable(headerLen + bodyLen);//确保可写长度(头部长度+数据长度)
//数据长度写入头部
CodedOutputStream headerOut =
CodedOutputStream.newInstance(new ByteBufOutputStream(out), headerLen);
headerOut.writeRawVarint32(bodyLen);
headerOut.flush();
//写数据
out.writeBytes(msg, msg.readerIndex(), bodyLen);
}
}
对应的解码类 ProtobufVarint32FrameDecoder:
做的事情如类注解:
* BEFORE DECODE (302 bytes) AFTER DECODE (300 bytes)
* +--------+---------------+ +---------------+
* | Length | Protobuf Data |----->| Protobuf Data |
* | 0xAC02 | (300 bytes) | | (300 bytes) |
* +--------+---------------+ +---------------+
//半包粘包处理
public class ProtobufVarint32FrameDecoder extends ByteToMessageDecoder {
// TODO maxFrameLength + safe skip + fail-fast option
// (just like LengthFieldBasedFrameDecoder)
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
in.markReaderIndex();//标记读取的位置
final byte[] buf = new byte[5];//varint32 最大5个字节
for (int i = 0; i < buf.length; i ++) {
if (!in.isReadable()) {
in.resetReaderIndex();
return;
}
buf[i] = in.readByte();
if (buf[i] >= 0) {
int length = CodedInputStream.newInstance(buf, 0, i + 1).readRawVarint32();//varint表示的格式 转 实际长度int
if (length < 0) {
throw new CorruptedFrameException("negative length: " + length);
}
if (in.readableBytes() < length) {//长度不够,回滚标记
in.resetReaderIndex();
return;
} else {
out.add(in.readBytes(length));//正确读取返回
return;
}
}
}
// Couldn\'t find the byte whose MSB is off.
throw new CorruptedFrameException("length wider than 32-bit");
}
}
四,总结
netty 默认已经帮我们实现了protocol buffers 的编码解码,所以使用起来很方便。
但如果有特殊需要,如加密等,自己定义编码解码则需要理解编码解码的规则和参考它的默认实现。
以上是关于理解netty对protocol buffers的编码解码的主要内容,如果未能解决你的问题,请参考以下文章