Vivado HLS Coding Style-22维卷积:C代码构建高效硬件
Posted wordchao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Vivado HLS Coding Style-22维卷积:C代码构建高效硬件相关的知识,希望对你有一定的参考价值。
------------------------------------------------------------------------------------------------------------
作者:王超
微信QQ:526160753
facebook:wordchao
研究:机器学习、深度学习
图像识别检测、车牌识别、人脸识别
人工智能算力优化、FPGA 协处理
------------------------------------------------------------------------------------------------------------
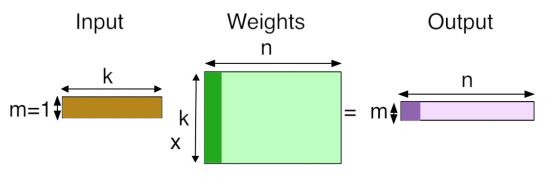
矩阵乘法GEMM(GEneral Matrix to Matrix Multiplication)

![Figure 2: Projection of low-level “shallow” features (left) and high-level “deep” features (right) from a vision model where related objects group together in the deep representation. Points that are close in this visualization are close in the model representation. Each point represents the feature extracted from an image and the color marks the general category of its contents. The model was trained on precise object classes like “espresso” and “chickadee” but learned features that group dogs, birds, and even animals on a whole together despite their visual contrasts [2].](https://image.cha138.com/20210605/20f2b7c6fc1b4143b6ba9bcd2668ee73.jpg)


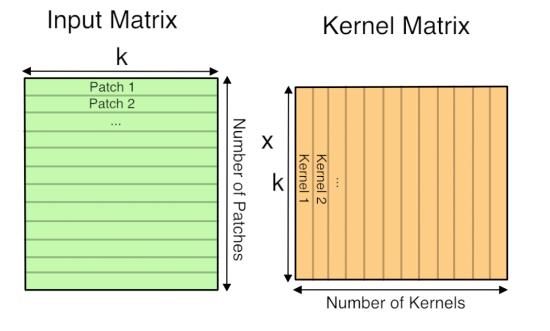
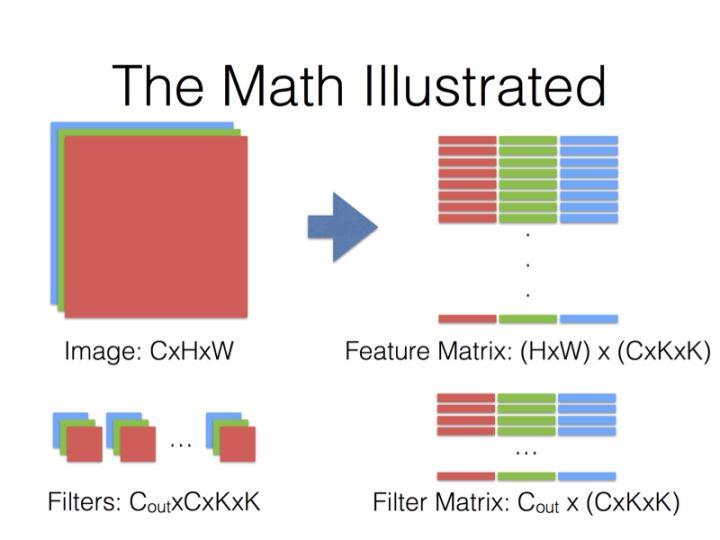
Why GEMM works for Convolutions
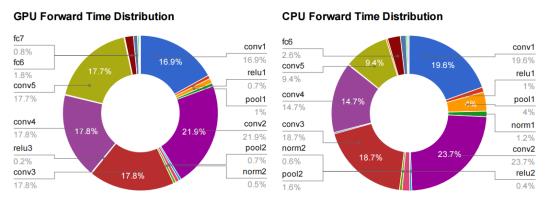
Hopefully you can now see how you can express a convolutional layer as a matrix multiplication, but it’s still not obvious why you would do it. The short answer is that it turns out that the Fortran world of scientific programmers has spent decades optimizing code to perform large matrix to matrix multiplications, and the benefits from the very regular patterns of memory access outweigh the wasteful storage costs. This paper from Nvidia is a good introduction to some of the different approaches you can use, but they also describe why they ended up with a modified version of GEMM as their favored approach. There are also a lot of advantages to being able to batch up a lot of input images against the same kernels at once, and this paper on Caffe con troll uses those to very good effect. The main competitor to the GEMM approach is using Fourier transforms to do the operation in frequency space, but the use of strides in our convolutions makes it hard to be as efficient.
The good news is that having a single, well-understood function taking up most of our time gives a very clear path to optimizing for speed and power usage, both with better software implementations and by tailoring the hardware to run the operation well. Because deep networks have proven to be useful for a massive range of applications across speech, NLP, and computer vision, I’m looking forward to seeing massive improvements over the next few years, much like the widespread demand for 3D games drove a revolution in GPUs by forcing a revolution in vertex and pixel processing operations.
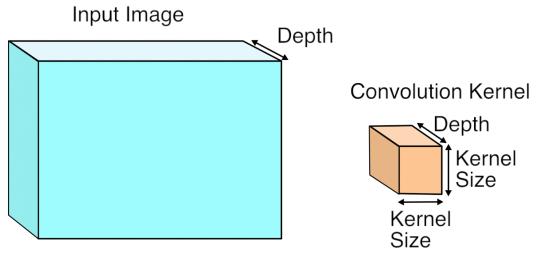
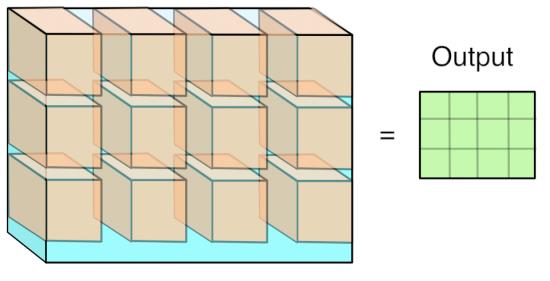
The trick is to just lay out all the local patches, and organize them to a (W*H, K*K*D) matrix. In Matlab, this is usually known as an im2col operation. After that, consider the filters being a (M, K*K*D) matrix too, the convolution naturally gets reduced to a matrix multiplication (Gemm in BLAS) problem.
So this is the story of the memory issue that came into play. I didn\'t mean to defend it - in any means, it was designed as a temporary solution.
So we are having a lot of improvements being worked on by Berkeley folks and collaborators - things will apparently get better soon - expect a faster yet more memory-efficient convolution this fall.

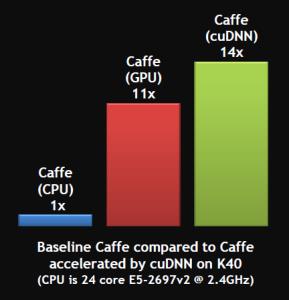



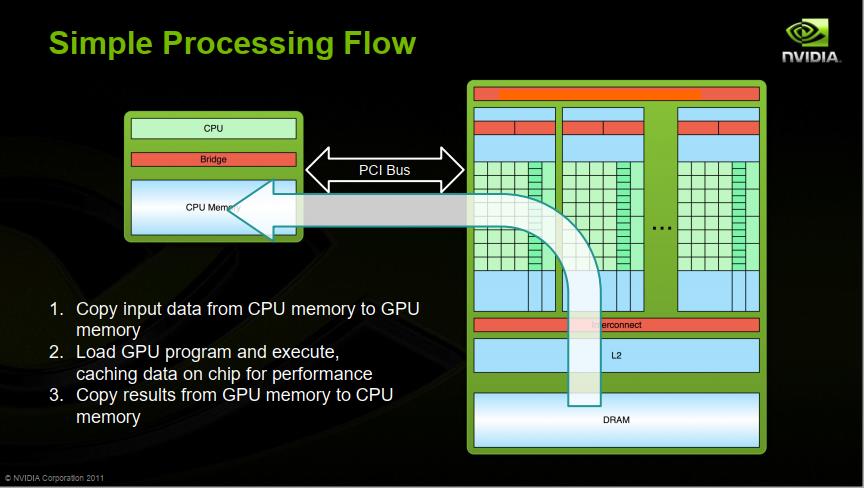









Reference
| 1.Caffe源码解析5: Conv_Layer | http://www.cnblogs.com/louyihang-loves-baiyan/p/5154337.html |
| 2.Understanding Convolution in Deep Learning | http://timdettmers.com/2015/03/26/convolution-deep-learning/ |
| 3.Convolution in Caffe: a memo | https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo |
| 4. | https://code.google.com/p/cuda-convnet/wiki/LayerParams#Local_response_normalization_layer_(across_maps) |
| 5.Why GEMM is at the heart of deep learning | https://petewarden.com/2015/04/20/why-gemm-is-at-the-heart-of-deep-learning/ |
| 6.Deep Learning for Computer Vision with Caffe and cuDNN | https://devblogs.nvidia.com/deep-learning-computer-vision-caffe-cudnn/ |
| 7.cuDNN: Efficient Primitives for Deep Learning | https://arxiv.org/pdf/1410.0759.pdf |
| 8.CS231n Convolutional Neural Networks for Visual Recognition | http://cs231n.github.io/convolutional-networks/ |
| 9.What are GPUs, anyway? | https://petewarden.com/2016/05/17/what-are-gpus-anyway/ |
| 10.Accelerate Machine Learning with the cuDNN Deep Neural Network Library | https://devblogs.nvidia.com/accelerate-machine-learning-cudnn-deep-neural-network-library/ |
| 11.An Introduction to GPU Computing and CUDA Architecture | http://on-demand.gputechconf.com/gtc-express/2011/presentations/GTC_Express_Sarah_Tariq_June2011.pdf |
| 12.Introduction to GPUs | https://www.cs.utexas.edu/~pingali/CS378/2015sp/lectures/IntroGPUs.pdf |
| 13.Deep learning:五十(Deconvolution Network简单理解) | http://www.cnblogs.com/tornadomeet/p/3444128.html |
以上是关于Vivado HLS Coding Style-22维卷积:C代码构建高效硬件的主要内容,如果未能解决你的问题,请参考以下文章