场景:上次回答word2vec相关的问题,回答的是先验概率和后验概率,没有回答到关键点。
词袋模型(Bag of Words, BOW)与词向量(Word Embedding)模型
- 词袋模型就是将句子分词,然后对每个词进行编码,常见的有one-hot、TF-IDF、Huffman编码,假设词与词之间没有先后关系。
- 词向量模型是用词向量在空间坐标中定位,然后计算cos距离可以判断词于词之间的相似性。
先验概率和后验概率
先验概率和后验证概率是基于词向量模型。首先一段话由五个词组成:
A B C D E
对C来说:先验概率指ABDE出现后C出现的概率,即P(C|A,B,D,E)
可以将C用ABDE出现的概率来表示 Vector(C) = [P(C|A), P(C|B), P(C|D), P(C|E) ]
后验概率指C出现后ABDE出现的概率:即P(A|C),P(B|C),P(D|C),P(E|C)
n-gram
先验概率和后验概率已经知道了,但是一个句子很长,对每个词进行概率计算会很麻烦,于是有了n-gram模型。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。
一般情况下我们只计算一个单词前后各两个词的概率,即n取2, 计算n-2,.n-1,n+1,n+2的概率。
如果n=3,计算效果会更好;n=4,计算量会变得很大。
cbow
cbow输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量,即先验概率。
训练的过程如下图所示,主要有输入层(input),映射层(projection)和输出层(output)三个阶段。
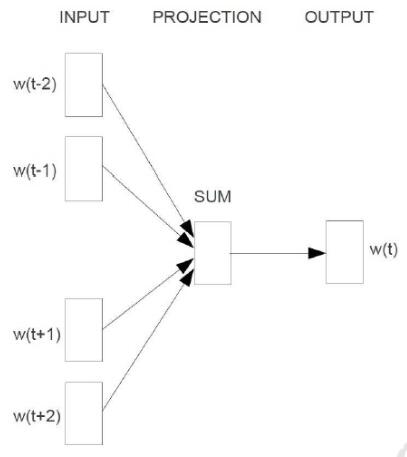
skip-gram
Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量,即后验概率。训练流程如下:
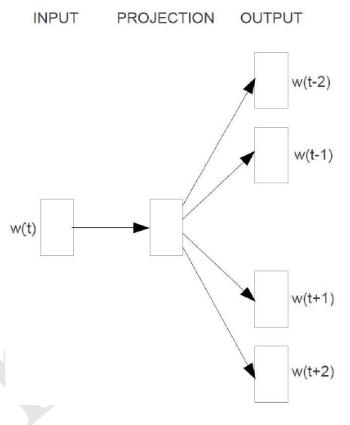
word2vec中的Negative Sampling概述
传统网络训练词向量的网络:
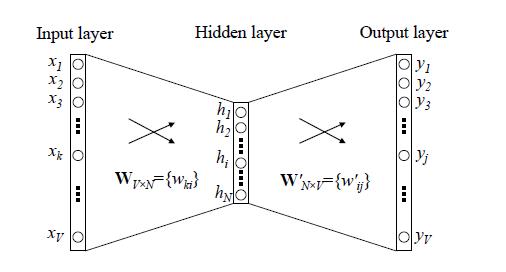
word2vec训练方法和传统的神经网络有所区别,主要解决的是softmax计算量太大的问题,采用Hierarchical Softmax和Negative Sampling模型。
word2vec中cbow,skip-gram都是基于huffman树然后进行训练,左子树为1右子树为0,同时约定左子树权重不小于右子树。
构建的Huffman树如下:
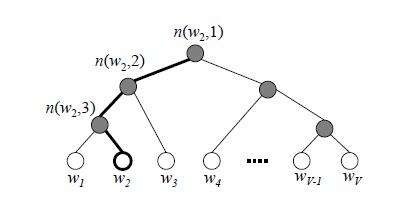
其中,根节点的词向量对应我们的投影后的词向量,而所有叶子节点就类似于之前神经网络softmax输出层的神经元,叶子节点的个数就是词汇表的大小。在霍夫曼树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着霍夫曼树一步步完成的,因此这种softmax取名为"Hierarchical Softmax"。
因为时间有限,暂时总结这些,下一次详细看一下word2vec中的实现。
参考:
word2vec原理(一) CBOW与Skip-Gram模型基础
word2vec原理(二) 基于Hierarchical Softmax的模型
自己动手写word2vec (四):CBOW和skip-gram模型