用Python玩爬虫,首先得有一个流程,这个流程最适合小白用!
Posted python1234
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Python玩爬虫,首先得有一个流程,这个流程最适合小白用!相关的知识,希望对你有一定的参考价值。
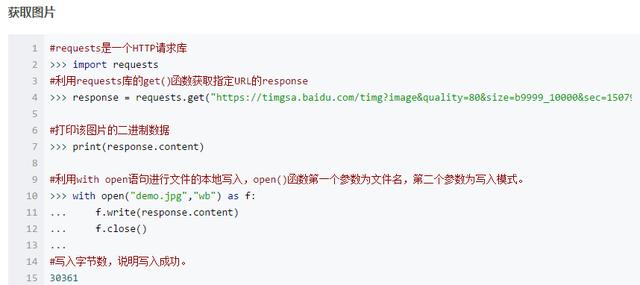
爬虫基本流程
-
发起请求
通过HTTP库向目标服务器发送Request,Request内可以包含额外的headers信息。
-
获取响应内容
如果服务器正常响应,会返回Response, 里面包含的就是该页面的内容。
-
解析数据
内容或许是html,可以用正则表达式、网页解析库进行解析。
或许是Json,可以直接转换为Json对象解析。
-
保存数据
可以存储为文本,也可以保存至数据库,或其他特定类型文件。

Response中包含的内容
-
响应状态
Status Code:200
即状态码,一般200表示响应成功。
-
响应头
Response Headers
内容类型,内容长度,服务器信息,设置Cookie等。
-
响应体
请求资源的内容,如网页源代码,二进制数据等。

一般做网页请求的时候,可以先判断状态码是否是200,再取出响应体进行解析。
解析方式
-
直接处理
-
Json解析
-
正则表达式
-
BeautifulSoup
-
PyQuery
-
XPath
视情况选择合适的解析方式。
保存数据
-
文本保存
纯文本、Json、Xml等。
-
关系型数据库保存
mysql、Oracle、SQLServer等。
-
非关系型数据库保存
MongoDB、Redis等Key-Value形式存储。
-
二进制文件
图片、视频、音频等特定文件。
Urllib库
Python内置的HTTP请求库
| 模块 | 说明 |
|---|---|
| urllib.request | 请求模块 |
| urllib.error | 异常处理模块 |
| urllib.parse | url解析模块 |
| urllib.robotparser | robots.txt解析模块 |



欢迎大家关注我的博客:https://home.cnblogs.com/u/Python1234/
欢迎加入千人交流学习群:125240963
以上是关于用Python玩爬虫,首先得有一个流程,这个流程最适合小白用!的主要内容,如果未能解决你的问题,请参考以下文章