七编码文件
Posted HaydenGuo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了七编码文件相关的知识,希望对你有一定的参考价值。
一、编码
1.1:内存和硬盘
- CPU: 从内存中读取程序的指令,然后解码并运行程序;
- 硬盘: 永久保存数据;
- 内存: 临时存储数据,任何程序运行都需事先加载到内存;
- 应用软件: 调用操作系统提供的接口;间接地使用计算机硬件,加载到内存中;
- 操作系统: 控制硬件,提供系统调用接口,加载到内存中;
1.2:文本编辑器存取文件的原理
例如(nodepad++,pycharm,word等),打开编辑器就可以启动一个进程,是在内存中的,所以在编辑器编写的内容也都是存放在内存中的,断电后数据就丢失了。因而需要保存在硬盘上,点击保存按钮或快捷键,就把内存中的数据保存到了硬盘上。在这一点上,我们编写的py文件(没有执行时),跟编写的其他文件没有什么区别,都只是编写一堆字符而已。
1.3:python解释器执行py文件的原理
例如python 、test.py:
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器;
第二阶段:python解释器相当于文本编辑器,去打开test.py,从硬盘上将test.py的文件内容读入到内存中;
第三阶段:python解释器执行刚刚加载到内存中的test.py的代码(在该阶段,即执行时,才会识别python的语法,执行到字符串时,会开辟内存空间存放字符串);
python解释器与文本编辑器相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样;
python解释器与文本编辑器不同点:文本编辑器将文件内容读入内存后,是为了显示/编辑,而python解释器将文件内容读入内存后,是为了执行(识别python的语法);
1.3:编码解释
计算机想要工作必须通电,高低电平(高电平即二进制数1,低电平即二进制数0),计算机只认识数字,让计算机读懂人类的字符就必须经过:字符---------(翻译过程)-------------数字,实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码。
1.一个python文件中的内容是由一堆字符组成的(python文件未执行时)
2.python中的数据类型字符串是由一串字符组成的(python文件执行时)
1.5:编码的发展史
阶段一:
- 现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII;
- ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符;
- ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符);
- 后来为了将拉丁文也编码进了ASCII表,将最高位也占用了;
阶段二:
- 为了满足中文,中国人定制了GBK;
- GBK:2Bytes代表一个字符,为了满足其他国家,各个国家纷纷定制了自己的编码,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里;
阶段三:
- 各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码;
- 于是产生了unicode, 统一用2Bytes代表一个字符, 2**16-1=65535,可代表6万多个字符,因而兼容万国语言;
- 但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的);
- 于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes;
阶段四:
- unicode:简单粗暴,多有的字符都是2Bytes,优点是字符--数字的转换速度快;缺点是占用空间大。
- utf-8:精准,可变长,优点是节省空间;缺点是转换速度慢,因为每次转换都需要计算出需要多长Bytes才能够准确表示。
- 内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是越快越好)
- 硬盘中或网络传输用utf-8,保证数据传输的稳定性。


1: 所有程序,最终都要加载到内存,程序保存到硬盘不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因在于此),统一且固定使用unicode, 2: 这就是为何内存固定用unicode的原因,你可能会说兼容万国我可以用utf-8啊,可以,完全可以正常工作,之所以不用肯定是unicode比utf-8更高效啊(uicode固定用2个字节编码 3:utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把unicode转成utf-8, 4: 因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
1.6:字符编码转换
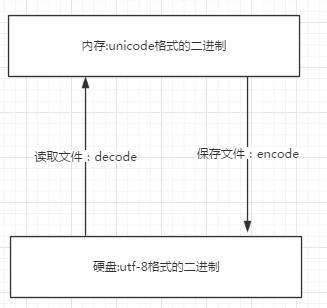
- 文件从内存刷到硬盘的操作简称存文件
- 文件从硬盘读到内存的操作简称读文件
- 乱码:存文件时就已经乱码 或者 存文件时不乱码而读文件时乱码
ascii:数字,字母 特殊字符。
字节:8位表示一个字节。
字符:是你看到的内容的最小组成单位。
abc : a 一个字符。
中国:中 一个字符。
a : 0000 1011
unicode: 万国码
起初:
a : 0000 1011 0000 1011
中: 0000 1011 0000 1111
升级:
a : 0000 1011 0000 1011 0000 1011 0000 1011
中: 0000 1011 0000 1111 0000 1011 0000 1011
utf-8:最少用8位表示一个字符。
a: 0000 1011
欧洲: 0000 1011 0000 1011
亚洲中:0000 1011 0000 1011 0000 1011
gbk:国标
a: 0000 1011
中文:0000 1011 0000 1011 两个字节。
- 不同编码之间的二进制是不能互相识别的。
- 对于文件的存储,及传输不能是unicode的编码。
python3x
int
bool
bytes:内部编码方式:(非unicode,utf-8,gbk.gb2312...)
str : 内部编码方式unicode
list
dict
tuple
bytes:内部编码方式:(非unicode,utf-8,gbk.gb2312...)
str : 内部编码方式unicode
1.6.1:对于字母
str:
- 表现形式:s1 = \'alex\'
- 内部编码:unicode
bytes:
- 表现形式:s2 = b\'alex\'
- 内部编码:非unicode
1.6.2:对于中文
str:
- 表现形式:s1 = \'中国\'
- 内部编码:unicode
bytes:
- 表现形式:b1 = b\'\\xe4\\xb8\\xad\\xe5\\x9b\\xbd\'
- 内部编码:非unicode
1.6.3: 例子
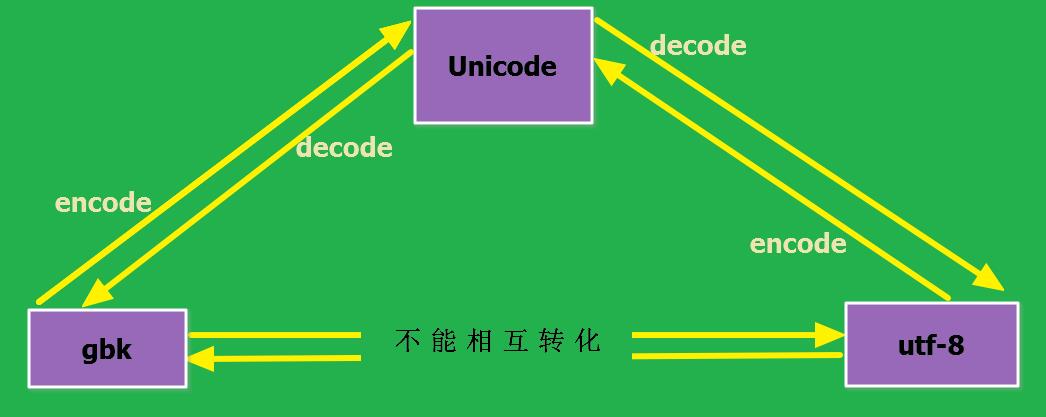
unicode和utf-8之间的转换:
s1 = \'alex\' #将alex从unicode编码转换为utf-8 b1 = s1.encode(\'utf-8\') print(b1) #输出结果: b\'alex\'
s1 = \'alex\' b1 = b\'alex\' print(s1.capitalize()) print(b1.capitalize()) #输出结果: Alex b\'Alex\'
s2 = \'中国\' b2 = s2.encode(\'utf-8\') print(b2) #输出结果: b\'\\xe4\\xb8\\xad\\xe5\\x9b\\xbd\'
unicode----->utf-8------>unicode
s1 = \'alex\' # str ---> bytes encode 编码 b1 = s1.encode(\'utf-8\') print(b1) #bytes---> str decode 解码 s2 = b1.decode(\'utf-8\') print(s2) #输出结果: b\'alex\' alex
Unicode、gbk、utf-8之间的转换:
s1 = \'alex\' b2 = s1.encode(\'gbk\') s3 = b2.decode(\'gbk\') print(b2) print(s3) #输出结果: b\'alex\' alex
s1 = \'alex\' b1 = s1.encode(\'utf-8\') s2 = b1.decode(\'gbk\') print(s2) #输出结果: alex
utf-8、gbk之间的转换
s4 = \'中国\' b4 = s4.encode(\'utf-8\') # utf-8 bytes print(b4) b6 = b4.decode(\'utf-8\').encode(\'gbk\') print(b6) #输出结果: b\'\\xe4\\xb8\\xad\\xe5\\x9b\\xbd\' #bytes类型的utf-8一个中文3个字节 b\'\\xd6\\xd0\\xb9\\xfa\' #bytes类型的gbk一个中文2个字节
二、文件
2.1:文件处理流程
- f1 文件句柄,f,file,file_hander,f_h....
- open()调用的内置函数,内置函数调用的系统内部的open,
- 一切对文件进行的操作都是基于文件句柄f1.
执行流程:
1,打开文件,产生文件句柄。
f=open(\'a.txt\',\'r\',encoding=\'utf-8\') #默认打开模式就为r
2,对文件句柄进行操作。
data=f.read()
3,关闭文件句柄。
f.close()
注意1:
打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为: 1、f.close() #回收操作系统级打开的文件 2、del f #回收应用程序级的变量 其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源。 而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close() 如果实在记不住f.close(),可以使用with关键字来帮我们管理上下文: with open(\'a.txt\',\'w\') as f: pass with open(\'a.txt\',\'r\') as read_f,open(\'b.txt\',\'w\') as write_f: data=read_f.read() write_f.write(data)
注意2:
f=open(...)是由操作系统打开文件,那么如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。 若要保证不乱码,文件以什么方式存的,就要以什么方式打开。 f=open(\'a.txt\',\'r\',encoding=\'utf-8\')
2.2:文件打开模式
打开文件(open 函数):
- open(file,[option])
- file 是要打开的文件名
- option 是可选择的参数,常见有 mode encoding
打开模式:
- r (只读模式):文件不存在时会报错。
- w (写入模式):文件存在会清空之前的内容,文件不存在则会新建文件。
- x (写入模式):文件存在会报错,文件不存在则会新建文件。
- a (追加写入模式):不清空之前的文件内容,直接将写入的内容添加到后面。
- b (以二进制模式读写文件):wb,rb,ab。 + 可读写模式,r+,w+,x+,a+,这几种模式还遵循了r,w,x,a的基本原则。
2.2.1:文本文件
文件句柄=open(\'文件路径\',‘模式’);
打开文件时,需要指定文件路径和以什么方式打开文件;
打开文件的模式有:
- r :只读模式【默认模式,文件必须存在,不存在则抛出异常】
- w:只写模式【不可读;不存在则创建;存在则清空内容】
- x: 只写模式【不可读;不存在则创建,存在则报错】
- a: 追加模式【可读; 不存在则创建;存在则只追加内容】
#只读模式 f=open(r\'c.txt\',encoding=\'utf-8\') print(\'====>1\',f.read()) print(\'====>2\',f.read()) print(f.readable()) print(f.readline(),end=\'\') print(f.readline()) print("="*20) print(f.read()) print(f.readlines()) f.close() #写模式:文件不存在则创建,文件存在则覆盖原有的 f=open("new.py",\'w\',encoding=\'utf-8\') f.write(\'1111111111\\n\') f.writelines([\'2222\\n\',\'2222548\\n\',\'978646\\n\']) f.close() # 追加模式:文件不存在则创建,文件存在不会覆盖,写内容是追加的方式写 f=open(\'new.py\',\'a\',encoding=\'utf-8\') f.write(\'nishishui\\n\') f.writelines([\'aa\\n\',\'bb\\n\']) f.close()
2.2.2:非文本文件
对于非文本文件,只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式)。
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码。
利用b模式,编写一个cp工具,要求:既可以拷贝文本又可以拷贝视频,图片等文件。 # b模式 f=open(\'1.jpg\',\'rb\') data=f.read() # print(data) f=open(\'2.jpg\',\'wb\') f.write(data) print(data)
2.2.3:‘+’模式
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
2.2.4:以bytes类型操作的读写,写读,写读模式
- r+b, 读写【可读,可写】
- w+b,写读【可写,可读】
- a+b, 写读【可写,可读】
2.3:文件的读
2.3.1:read() 全读出来
- f.read(size) 读取文件的内容,将文件的内容以字符串形式返回。
- size 是可选的数值,指定字符串长度,如果没有指定size或者指定为负数, 就会读取并返回整个文件。
- 当文件大小为当前机器内存两倍时就会产生问题, 反之就尽可能大的size读取和返回数据,如果到了文件末尾,会返回空字符串。
f1 = open(\'log1\', encoding=\'utf-8\') content = f1.read() print(content) f1.close() f1 = open(\'1.jpg\', mode=\'rb\') print(f1.read()) f1.close()
2.3.2:read(n) 读一部分
f1 = open(\'log1\', encoding=\'utf-8\') content = f1.read(3) print(content) f1.close() #r 模式 read(n) n 按照字符读取。 #rb 模式 read(n) n 按照字节读取。 f1 = open(\'log1\', mode=\'rb\') print(f1.read(3).decode(\'utf-8\')) f1.close()
2.3.4:readline() 按行读取
- f.readline() 从文件中读取单独一行,字符串结尾会自动加上一个换行符 \\n,
- 只有当文件最后没有以换行符结尾时,这一操作才会被忽略, 这样返回值就不会有混淆。
- 如果返回空字符串,表示到达率文件末尾, 如果是空行,就会描述为\\n,一个只有换行符的字符串。
f1 = open(\'log1\', encoding=\'utf-8\') print(f1.readline()) print(f1.readline()) print(f1.readline()) f1.close()
2.3.5:readlines()
- f.readlines() 一次读取所有,返回一个列表,列表的元素为文件行的内容。
- 可以通过列表索引的方式将文件的每一行的内容输出。
- 可以通过 for 循环迭代输出每一行的信息。
f1 = open(\'log1\', encoding=\'utf-8\') print(f1.readlines()) f1.close()
2.3.6:for循环读取
f1 = open(\'log1\', encoding=\'utf-8\') for line in f1: print(line) f1.close()
2.3.7:r+读写
f1 = open(\'log1\', encoding=\'utf-8\', mode=\'r+\') # print(f1.read()) # f1.write(\'666\') f1.write(\'a\') print(f1.read()) f1.close()
2.4:文件的写
- f.write() 将要写入的内容以字符串的形式通过 write 方法写入文件中。
- f.writelines() 括号里必须是由字符串元素组成的序列。
- 没有文件,新建文件写入内容
- 有原文件,先清空内容,在写入新内容。
2.4.1:文本文件写
f1 = open(\'log2\', encoding=\'utf-8\', mode=\'w\') f1.write(\'桃白白fdksagdfsa\') f1.close()
2.4.2:图片的读取及写入
f1 = open(\'1.jpg\', mode=\'rb\') content = f1.read() f2 = open(\'2.jpg\', mode=\'wb\') f2.write(content) f1.close() f2.close()
2.4.3:w+ 先写后读
f1 = open(\'log2\', encoding=\'utf-8\', mode=\'w+\') f1.write(\'两款发动机了\') f1.seek(0) print(f1.read()) f1.close()
2.5:文件的追加
a 没有文件,新建文件写入内容 f1 = open(\'log3\', encoding=\'utf-8\', mode=\'a\') # f1.write(\'alex 666\') f1.write(\'\\nalex 666\') f1.close() a+ f1 = open(\'log3\', encoding=\'utf-8\', mode=\'a+\') f1.write(\'python22期\') f1.seek(0) print(f1.read()) f1.close()
2.6:上下文管理
不用主动关闭文件句柄:
with open(\'a.txt\',\'w\') as f:
pass
with open(\'a.txt\',\'r\') as read_f,open(\'b.txt\',\'w\') as write_f:
data=read_f.read()
write_f.write(data)
with open(\'log1\', encoding=\'utf-8\') as f1,\\ open(\'log2\', encoding=\'utf-8\', mode=\'w\') as f2: content = f1.read() f2.write(content)
with open(\'log1\', encoding=\'utf-8\') as f1: print(f1.read()) f1.close() pass with open(\'log1\', encoding=\'utf-8\',mode=\'w\') as f2: f2.write(\'666\')
2.6:文件的修改
2.6.1:修改流程
- 以读模式打开原文件。
- 以写的模式打开一个新文件。
- 将原文件读出按照要求修改将修改后的内容写入新文件。
- 删除原文件。
- 将新文件重命名原文件。
import os with open(\'file\', encoding=\'utf-8\') as f1,\\ open(\'file.bak\', encoding=\'utf-8\', mode=\'w\') as f2: old_content = f1.read() new_content = old_content.replace(\'alex\', \'SB\') f2.write(new_content) os.remove(\'file\') os.rename(\'file.bak\', \'file\')
升级版:
# import os # with open(\'file\', encoding=\'utf-8\') as f1,\\ # open(\'file.bak\', encoding=\'utf-8\', mode=\'w\') as f2: # for line in f1: # new_line = line.replace(\'SB\',\'alex\') # f2.write(new_line) # # os.remove(\'file\') # os.rename(\'file.bak\', \'file\') with open(\'log1\', encoding=\'utf-8\', mode=\'w\') as f1: f1.write(\'111\') f1.write(\'666\') f1.write(\'333\') f1.write(\'222\')
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
2.6.2:修改方式一:
将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)。
import os #调用系统模块 with open(\'a.txt\') as read_f,open(\'.a.txt.swap\',\'w\') as write_f: data=read_f.read() #全部读入内存,如果文件很大,会很卡 data=data.replace(\'alex\',\'SB\') #在内存中完成修改 write_f.write(data) #一次性写入新文件 os.remove(\'a.txt\') #删除原文件 os.rename(\'.a.txt.swap\',\'a.txt\') #将新建的文件重命名为原文件
2.6.3:修改方式二:
将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件。
import os with open(\'a.txt\') as read_f,open(\'.a.txt.swap\',\'w\') as write_f: for line in read_f: line=line.replace(\'alex\',\'SB\') write_f.write(line) os.remove(\'a.txt\') os.rename(\'.a.txt.swap\',\'a.txt\')
2.7:文件的光标移动
2.7.1:read
read(3):
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
2.7.2:seek、tell、truncate
其余的文件内光标移动都是以字节为单位如:seek,tell,truncate。
注意:
- seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的,seek控制光标的移动,是以文件开头作为参照的。
- tell当前光标的位置。
- truncate是截断文件,截断必须是写模式,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果。
# f1 = open(\'log2\', encoding=\'utf-8\') # f1.read() # print(f1.tell()) # print(f1.seek(0)) # print(f1.seek(0,2)) # f1.seek(12) # 任意调整 # f1.seek(0,2) #光标调整到最后 # f1.seek(0) #光标调整到开头 # print(f1.tell()) # 告诉光标的位置 # f1.close() # f1 = open(\'log3\', encoding=\'utf-8\', mode=\'a+\') # f1.truncate(3) # 按照字节对原文件进行截取 必须在a 或 a+ 模式 # f1.close()
import time with open(\'test.txt\',\'rb\') as f: f.seek(