Greeplum 系列 基本用法
Posted binarylei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Greeplum 系列 基本用法相关的知识,希望对你有一定的参考价值。
Greeplum 系列(三) 基本用法
《PostgreSQL 教程》:https://www.yiibai.com/postgresql
一、Greeplum 登陆与创建
1.1 登陆
psql -d test -h 127.0.0.1 -p 5432 -U gpadmin
注意:默认登陆的表名为 gpadmin
1.2 创建数据库
create database test; # 需要登陆 psql
create database newdb template olddb; # 克隆数据库
createdb test; # 命令行模式
createdb -h mdw -p 5432 test; # 命令行模式
select datname from pg_database; # 查看数据库
\\dl
drop database test; # 删除数据库
dropdb test;
1.3 文件空间
(1) root 用户在 Master 和 Segment 上创建表空间
mkdir -p /data2/master
mkdir -p /data2/primary
mkdir -p /data2/mirror
chown gpadmin:gpadmin /data2/master
chown gpadmin:gpadmin /data2/primary
chown gpadmin:gpadmin /data2/mirror
(2) gpadmin 用户执行 gpfilespace 生成 gpfilespace_config 文件
gpfilespace -o gpfilespace_config
20180530:21:55:41:003355 gpfilespace:mdw:gpadmin-[INFO]:-
A tablespace requires a file system location to store its database
files. A filespace is a collection of file system locations for all components
in a Greenplum system (primary segment, mirror segment and master instances).
Once a filespace is created, it can be used by one or more tablespaces.
20180530:21:55:44:003355 gpfilespace:mdw:gpadmin-[INFO]:-getting config
Enter a name for this filespace
> new_file_space
Checking your configuration:
Your system has 2 hosts with 1 primary and 0 mirror segments per host.
Your system has 1 hosts with 0 primary and 0 mirror segments per host.
Configuring hosts: [sdw2, sdw1]
Please specify 1 locations for the primary segments, one per line:
primary location 1> /data2/primary
Configuring hosts: [mdw]
Enter a file system location for the master
master location> /data2/master
20180530:21:57:46:003355 gpfilespace:mdw:gpadmin-[INFO]:-Creating configuration file...
20180530:21:57:46:003355 gpfilespace:mdw:gpadmin-[INFO]:-[created]
20180530:21:57:46:003355 gpfilespace:mdw:gpadmin-[INFO]:-
To add this filespace to the database please run the command:
gpfilespace --config /home/gpadmin/gpfilespace_config
gpfilespace_config 内容如下,可手动编辑 gpfilespace_config 文件:
filespace:new_file_space
mdw:1:/data2/master/gpseg-1
sdw2:3:/data2/primary/gpseg1
sdw1:2:/data2/primary/gpseg0
(3) gpadmin 用户执行 gpfilespace –c gpfilespace_config
gpfilespace –c gpfilespace_config
1.4 表空间
(1) 常用命令
create tablespace tb_space filespace test_fs; # 创建表空间
drop tablespace tb_space; # 对象被删除前,表空间不能被删除
drop filespace test_fs; # 表空间被删除前,文件空间不能被删除
grant create on tablespace tb_space to admin; # 授予使用权限给普通用户
create table tb_01(id int) tablespace tb_space; # 使用表空间
set default_tablespace=tb_space; # 设置默认的表空间
(2) Greenplum 中默认的 2 个缺省表空间和 1 个缺省文件空间:
- pg_global(默认表空间):存储系统日志信息
- pg_default(默认表空间):存储template1和template0模版DB
- pg_system(默认文件空间):系统初始化时使用的数据目录
(3) 获取文件空间的信息:
SELECT spcname as tblspc, fsname as filespc, fsedbid as seg_dbid, fselocation as datadir
FROM pg_tablespace pgts, pg_filespace pgfs, pg_filespace_entry pgfse
WHERE pgts.spcfsoid=pgfse.fsefsoid AND pgfse.fsefsoid=pgfs.oid ORDER BY tblspc, seg_dbid;
查询结果如下:
tblspc | filespc | seg_dbid | datadir
------------+-----------+----------+----------------------
pg_default | pg_system | 1 | /data/master/gpseg-1
pg_default | pg_system | 2 | /data/primary/gpseg0
pg_default | pg_system | 3 | /data/primary/gpseg1
pg_global | pg_system | 1 | /data/master/gpseg-1
pg_global | pg_system | 2 | /data/primary/gpseg0
pg_global | pg_system | 3 | /data/primary/gpseg1
二、创建与管理模式
访问模式的对象:schema.table,缺省 Public 模式
1. 创建和删除模式
create schema sc01; # 创建 schema
create schema sc02 authorization dylan; # 将 schema 权限赋予用户 dylan
drop schema sc01; # 删除 schema(空模式)
drop schema sc01 cascade; # 删除模式及相关的所有对象
2. 查看模式
查看所有的模式为 \\dn
List of schemas
Name | Owner
--------------------+---------
gp_toolkit | gpadmin
information_schema | gpadmin
pg_aoseg | gpadmin
pg_bitmapindex | gpadmin
pg_catalog | gpadmin
pg_toast | gpadmin
public | gpadmin
3. 设置模式搜索路径
若不想通过指定模式名称的方式来搜索需要的对象,可以通过设置 search_path 的方式来实现,第一个模式为缺省。
# 查看当前的搜索路径
select current_schema();
show search_path;
# 设置搜索路径
# 通过ALTER DATABASE修改DB的模式搜索路径
alter database test set search_path to sc01,public,pg_catalog;
# 通过 alter role 修改 ROLE(User) 的模式搜索路径
alter role dylan set search_path to sc01,public,pg_catalog;
注意: 修改表的搜索路径后需要重新登陆才会生效,即不会在当前会话生效。
4. 系统模式
- pg_catalog 模式:存储系统日志表、内置类型、函数和运算符。
- Information_schema 模式:由一个标准化视图构成。其中包含DB中对象的信息。
- pg_toast 模式:是存储大对象(系统内部使用)
- pg_bitmapindex 模式:存储bitmap index对象(系统内部使用)
- pg_aoseg 模式:存储append-only表(系统内部使用)
- gp_toolkit 模式:是管理用的模式,可以查看和检索系统日志文件和其他系统信息。
三、创建与管理表
通过 CREATE TABLE 命令实现,在创建表时,通过需要定义以下几点:
- 哪些列及数据类型
- 约束限定可以存储什么样的数据
- 表的分布策略
- 存储方式。比如压缩、列存储等
- 大表的分区策略
3.1 数据类型
- 对于字符类型,多数选择 TEXT 或者 VARCHAR
- 对于数值类型,尽量选择更小的数据类型
- 对于打算用作连接的列,选择相同的数据类型
create table tb_products(
-- 1. 主键约束,唯一约束和非空约束的综合体。默认成为 DK(Distributed Key)
id integer integer PRIMARY KEY,
-- 2. 唯一约束,确保字段的数据在表中唯一
product_no integer UNIQUE,
-- 3. 非空约束,不可以存在空值
name text NOT NULL,
-- 4. 检查约束,过制定数据必须满足一个布尔表达式来约束
price numeric CHECK(price>0)
-- 5. 外键约束,GPDB 目前不支持。
);
注意: 主键约束与唯一约束只有出现一个。
3.2 分布策略
在 create table 和 alter table 的时候使用 DISTRIBUTED BY(HASH 分布)或 DISTRIBUTED RANDOMLY(随机分布)来决定数据如何分布。考虑要点:
- 均匀的数据分布:尽量确保每个 segment 实例存储了等量的数据;尽可能使用具有唯一性的 DK,比如主键、唯一键等。
- 本地操作与分布式操作:确保查询的处理(关联、排序、聚合等)尽可能在每个实例的本地完成,避免数据重分布;不同表尽量使用相同DK,避免使用随机分布。
- 均衡的查询处理:尽可能确保每个 segment 实例能处理等量的工作负载。
声明分布键:
- 在创建或者修改表定义的时候指定;
- 如果没有指定,系统会依次考虑使用主键或第一个字段作为HASH分布的DK;
- 几何类型或自定义类型的列不适合作为GP的DK。
- 如果没有合适类型的列可以保证数据平均分布,则使用随机分布。
create table tb_dk_01(a int, b int) distributed by(b);
create table tb_dk_02(a int, b int);
create table tb_dk_03(a int primary key, b int);
create table tb_dk_04(a int, b int) distributed randomly;
# 查看表分布键
\\d tb_dk_01
3.3 存储模式
选择堆存储(Heap)或只追加(Append-Only)存储
- 堆存储适合数据经常变化的小表,比如维度表;
- 只追加存储适合仓库中事实大表,通常是批量装载数据并只进行只读查询操作,不支持 UPADTE 和 DELETE 操作。
# 创建堆表,缺省的存储模式
CREATE TABLE tb_heap_01(id int) DISTRIBUTED BY (id)
# 创建只追加表
CREATE TABLE tb_ao_01(id int) WITH(appendonly=true)
3.4 行存储与列存储
选择行存储(Row-Orientation)或列存储(Column-Orientation),考虑因素:
-
表数据的更新:只能选择行存储。
-
如果经常有数据被 INSERT:考虑选择行存储。
-
查询设计的列数量:
如果在 SELECT 或 WHERE 中涉及表的全部或大部分列时,考虑行存储。列存储适用于在 WHERE 或 HAVING 中队单列作聚合操作:
SELECT SUM(salary)
SELECT AVG(salary)…WHERE salary>10000或在 WHERE 条件中使用单个列条件且返回少量的行使用压缩存储
SELECT salary, dept…WHERE state=‘CA’
-
表的列数量:行存储对于列多或行尺寸相对小的表更高效;列存储在只访问宽表的少量列的查询中性能更高。
-
压缩:列存储表具有压缩优势。
-- 创建列存储时,只能为追加(Append-Only)存储
create table tb_col_01(a int, b text) with (appendonly=true, orientation=column) distributed by (a);
3.5 压缩存储(只支持Append-only表)
两种压缩方式:表级压缩和列级压缩。
(1) 选择压缩方式和级别的考虑因素:
- CPU性能
- 压缩比
- 压缩速度
- 解压速度或查询效率
应保证不会显著提高压缩时间和查询效率的前提下最有效的压缩减少数据尺寸。ZLIB 压缩率高于 QUICKLZ,但速度较低。
-- 注意:QUICKLZ 只有一种压缩级别,即没有 compresslevel 参数,而 ZLIB 有 1-9 可选。
create table tb_zlib_01(a int, b text) with (appendonly=true, compresstype=zlib, compresslevel=5);
(2) 检查 AO 表的压缩和分布情况:
# 查看表的分布情况,只能用于Append-Only表
select get_ao_distribution(\'表名\');
# 查看表的压缩率,只能用于Append-Only表
select get_ao_compression_ratio(\'表名\');
select gp_segment_id, count(1) from 表名 group by 1;
(3) 参数
- COMPRESSTYPE:ZLIB(更高压缩率)、QUICKLZ(更快压缩)、RLE_TYPE(运行长度编码)、none(无压缩、缺省)
- COMPRESSLEVEL:ZLIB为1-9级可选,1级最低,9级最高;QUICKLZ仅1级压缩可选;RLE_TYPE为1-4级可选,1级快但压缩率低,4级较慢但压缩率高
- BLOCKSIZE:8K~2M
(4) 压缩设置的优先级
在越低级别的设置具有越高的优先级:
- 子分区的列压缩设置将覆盖分区、列和表级的设置
- 分区的列压缩设置将覆盖列和表级的设置
- 列的压缩设置将覆盖整个表级的设置
注意: 存储设置不可以被继承
create table tb_t3 (
c1 int encoding(compresstype=zlib),
c2 text,
c3 text encoding(compresstype=rle_type),
c4 smallint encoding(compresstype=none),
defalut column encoding(compresstype=quicklz, blocksize=65536)
)
with(appendonly=true, orientation=column)
partition by range(c3)
(
start(\'2010-01-01\'::date) end(\'2010-12-31\'::date),
column c3 encoding(compresstype=zlib)
);
3.6 变更表
alter table 命令用于改变现有表的定义。例如:
alter table tb_01 alter column a set not null;
(1) 修改分布策略
-- 数据会重分布,并递归地应用于所有子分区
alter table tb_01 set distributed by(b);
-- 注意:将分布策略改为随机分布时不会重新分布数据
alter table tb_01 set distributed randomly;
(2) 重分布表数据
# 随机分布策略或者不改变分布策略的表,强行重分布
alter table tb_01 set with(reorganize=true);
(3) 修改表的存储模式
存储模式只能在CREATE TABLE时被指定。如果要修改,必须使用正确的存储选项重建该表。
CREATE TABLE tb_zlib_02 (like tb_zlip_01) WITH (appendonly=true, compresstype=quicklz, compresslevel=1, orientation=column);
INSERT INTO tb_zlib_02 SELECT * FROM tb_zlip_01;
DROP TABLE tb_zlip_01;
ALTER TABLE tb_zlib_02 RENAME TO tb_zlib_01;
GRANT ALL PRIVILEGES ON tb_zlib_01 TO admin;
GRANT SELECT ON tb_zlib_01 TO dylan;
(4) 添加压缩列
ALTER TABLE tb_zlib_01 ADD COLUMN c int DEFAULT 0 ENCODING (COMPRESSTYPE=zlib);
(5) 删除表
-- 删除与表相关的视图,必须使用CASCADE
DROP TABLE tb01;
DROP TABLE tb03 CASCADE;
-- 使用 DELETE 或 TRUNCATE 清空表记录
DELETE FROM tb02;
TRUNCATE tb02;
四、分区表
一张大表逻辑性地分成多个部分,如按照分区条件进行查询,将减少数据的扫描范围,提高系统性能。提高对于特定类型数据的查询速度和性能,更方便数据库的维护和更新。
决定表的分区策略:
- 表是否足够大?大的事实表适合做表分区。
- 对目前的性能不满意?查询性能低于预期时再考虑分区。
- 查询条件是否能匹配分区条件?查询语句的WHERE条件是否与考虑分区的列一致
- 数据仓库是否需要滚动历史数据?历史数据的滚动需求也是分区设计的考虑因素
- 按照某个规则数据是否可以被均匀的分拆?尽量把数据均匀分拆的规则
4.1 分区表类型
- Range分区: (日期范围或数字范围)/如日期、价格等
- List 分区: 例如地区、产品等
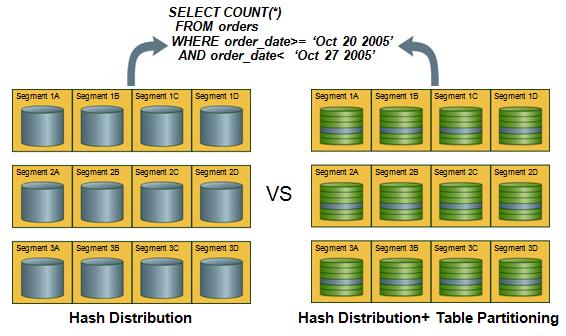
4.2 创建分区
TABLE 只能在 CREATE TABLE 时被分区。第一步要选择分区类型(范围分区、列表分区)和分区字段
(1) 定义日期范围分区表(range分区)
使用单个 date 或者 timestamp 字段作为分区键。如果需要,还可以使用同样的字段做子分区。通过使用 START、END 和 EVERY 子句定义分区增量让 GP 自动产生分区。
CREATE TABLE tb_cp_01 (id int, date date, amt decimal(10, 2))
DISTRIBUTED BY (id)
PARTITION BY RANGE (date)
(
-- (默认行为)INCLUSIVE:包含 2013-01-01;EXCLUSIVE:不包含 2014-01-01
START (date \'2013-01-01\') INCLUSIVE
END (date \'2014-01-01\') EXCLUSIVE
EVERY (INTERVAL \'1 month\')
);
也可以为每个分区单独制定名称
CREATE TABLE tb_cp_02 (id int, date date, amt decimal(10, 2))
DISTRIBUTED BY (id)
PARTITION BY RANGE (date)
(
PARTITION Jan13 START (date \'2013-01-01\') INCLUSIVE,
PARTITION Feb13 START (date \'2013-02-01\') INCLUSIVE,
PARTITION Mar13 START (date \'2013-03-01\') INCLUSIVE,
PARTITION Apr13 START (date \'2013-04-01\') INCLUSIVE,
PARTITION May13 START (date \'2013-05-01\') INCLUSIVE,
PARTITION Jun13 START (date \'2013-06-01\') INCLUSIVE,
PARTITION Jul13 START (date \'2013-07-01\') INCLUSIVE,
PARTITION Aug13 START (date \'2013-08-01\') INCLUSIVE,
PARTITION Sep13 START (date \'2013-09-01\') INCLUSIVE,
PARTITION Oct13 START (date \'2013-10-01\') INCLUSIVE,
PARTITION Nov13 START (date \'2013-11-01\') INCLUSIVE,
PARTITION Dec13 START (date \'2013-12-01\') INCLUSIVE
END (date \'2014-01-01\') EXCLUSIVE
);
(2) 定义数字范围分区表
CREATE TABLE tb_cp_03 (id int, rank int, year int, gender char(1), count int)
DISTRIBUTED BY (id)
PARTITION BY RANGE (year)
(
START (2010) END (2014) EVERY (1),
DEFAULT PARTITION extra
);
(3) 创建列表分区表(list分区)
可以使用任何数据类型的列作为分区键;可以使用多个列组合作为分区键。
CREATE TABLE tb_cp_04 (id int, rank int, year int, gender char(1), count int )
DISTRIBUTED BY (id)
PARTITION BY LIST (gender)
(
PARTITION girls VALUES (\'F\'),
PARTITION boys VALUES (\'M\'),
DEFAULT PARTITION other
);
(4) 定义多级分区表
当需要子分区时,可以使用多级分区的设计。
CREATE TABLE tb_cp_05 (trans_id int, date date, amount decimal(9, 2), region text)
DISTRIBUTED BY (trans_id)
PARTITION BY RANGE (date)
SUBPARTITION BY LIST (region)
SUBPARTITION TEMPLATE
(
-- 子分区
SUBPARTITION usa VALUES (\'usa\'),
SUBPARTITION europe VALUES (\'europe\'),
DEFAULT SUBPARTITION other_regions
)
(
-- 主分区
START (date \'2013-09-01\') INCLUSIVE
END (date \'2014-01-01\') EXCLUSIVE
EVERY (INTERVAL \'1 month\'),
DEFAULT PARTITION outlying_dates
);
创建3级子分区表,被分区为年、月、区域三层。
CREATE TABLE tb_cp_06 (id int, year int, month int, day int, region text)
DISTRIBUTED BY (id)
PARTITION BY RANGE (year)
SUBPARTITION BY RANGE (month)
SUBPARTITION TEMPLATE (
-- 定义二级分区(2个 + default)
START (1) END (3) EVERY (1),
DEFAULT SUBPARTITION other_months)
SUBPARTITION BY LIST (region)
SUBPARTITION TEMPLATE (
-- 定义三级分区(2个 + default)
SUBPARTITION usa VALUES (\'usa\'),
SUBPARTITION europe VALUES (\'europe\'),
DEFAULT SUBPARTITION other_regions)
(
-- 定义一级分区(2个 + default)
START (2012) END (2014) EVERY (1),
DEFAULT PARTITION outlying_years
);
4.3 查看分区设计
通过 pg_partitions 视图查看分区表设计情况。
SELECT partitionboundary, partitiontablename, partitionname, partitionlevel, partitionrank
FROM pg_partitions WHERE tablename=\'tb_cp_05\';
如下视图也可以查看分区表的信息:
- 查看创建 SUBPARTITION 的 pg_partition_templates
- 查看分区表的分区键 pg_partition_columns
4.4 维护分区表
必须使用 ALTER TABLE 命令从顶级表来维护分区。
(1) 添加新分区
原分区表包含 subpartition template 设计:
ALTER TABLE tb_cp_05 DROP DEFAULT PARTITION;
ALTER TABLE tb_cp_05 ADD PARTITION START (date \'2014-01-01\') INCLUSIVE END (date \'2014-02-01\') EXCLUSIVE;
原分区不包含 subpartition template 设计:
ALTER TABLE tb_cp_05 ADD PARTITION START (date \'2014-02-01\') INCLUSIVE END (date \'2014-03-01\') EXCLUSIVE
(
SUBPARTITION usa VALUES (\'usa\'),
SUBPARTITION asia VALUES (\'asia\'),
SUBPARTITION europe VALUES (\'europe\')
);
注意:如果存在默认分区,只能从默认分区中拆分新的分区
(2) 重命名分区
GP 中的对象长度限制为 63 个字符,并且受唯一性约束。子表的名称格式:
<父表名称>_<分区层级>_prt_<分区名称>
修改父表名称,将会影响所有分区表
# 对应分区表将会改为:tbcp05_1_prt_5
ALTER TABLE tb_cp_05 rename to tbcp05;
只修改分区名称:
# 对应分区表将会改为:tbcp05_1_prt_jun13
ALTER TABLE tbcp05 RENAME PARTITION FOR(\'2013-06-01\') TO Jun13;
(3) 删除分区
# 删除指定的分区
ALTER TABLE tb_cp_04 DROP PARTITION other;
# 删除默认分区:
ALTER TABLE tb_cp_04 DROP DEFAULT PARTITION;
# 对于多级分区表,为同一层每一个分区删除默认分区:
ALTER TABLE tb_cp_06 ALTER PARTITION FOR (RANK(1)) DROP DEFAULT PARTITION;
ALTER TABLE tb_cp_06 ALTER PARTITION FOR (RANK(2)) DROP DEFAULT PARTITION;
(4) 添加默认分区
# 使用ALTER TABLE命令添加默认分区:
ALTER TABLE tbcp05 ADD DEFAULT PARTITION other;
# 如果是多级分区表,同一层每个分区都需要默认分区:
ALTER TABLE tb_cp_06 ALTER PARTITION FOR (RANK(1)) ADD DEFAULT PARTITION other;
ALTER TABLE tb_cp_06 ALTER PARTITION FOR (RANK(2)) ADD DEFAULT PARTITION other;
(5) 清空分区数据
# 使用ALTER TABLE命令来清空分区。
ALTER TABLE tbcp05 TRUNCATE PARTITION FOR (RANK(1));
(6) 交换分区
交换分区是用一个普通的 TABLE 与现有的分区交换身份。使用 ALTER TABLE 命令来交换分区。只能交换最低层次的分区表。
CREATE TABLE jan13(LIKE tb_cp_02) WITH(appendonly=true);
INSERT INTO jan13 VALUES(1,\'2013-01-15\',123.45);
ALTER TABLE tb_cp_02 EXCHANGE PARTITION for(date \'2013-01-01\') WITH TABLE jan13;
(7) 拆分分区
使用 ALTER TABLE 命令将现有的一个分区拆分成两个。例如:将一个月分区数据拆分到一个1-15日的分区和另一个16-31日的分区
ALTER TABLE tb_cp_02 SPLIT PARTITION FOR(\'2013-01-01\') AT (\'2013-01-16\')
INTO (PARTITION jan131to15, PARTITION jan0816to31);
如果分区表有默认分区,要添加新分区只能从默认分区拆分:
ALTER TABLE tb_cp_03 SPLIT DEFAULT PARTITION
START (2014) INCLUSIVE END (2015) EXCLUSIVE
INTO (PARTITION y2014, DEFAULT PARTITION);
(8) 修改子分区模板
使用 ALTER TABLE SET SUBPARTITION TEMPLATE 命令来修改现在分区表的子分区模板。例如:
ALTER TABLE tb_cp_05 SET SUBPARTITION TEMPLATE
(
SUBPARTITION usa VALUES(\'usa\'),
SUBPARTITION africa VALUES(\'africa\'),
DEFAULT SUBPARTITION other
);
使用新模板后为表 tb_cp_05 添加一个分区,
ALTER TABLE tb_cp_05 ADD PARTITION Feb14 START (\'2014-02-01\') INCLUSIVE END(\'2014-03-01\') EXCLUSIVE;
4.5 其它
(1) 装载分区表
- 分区表中顶级表是空的,数据存储在最底层的表中。
- 为避免数据装载失败,可选择定义默认分区。
- 查询分区表时,默认分区总是会被扫描,如果默认分区包含数据,会影响查询效率。
- 在使用 COPY 或者 INSERT 向父级表装载数据时,数据会自动路由到正确的分区。
- 可考虑交换分区的方法直接转载数据到子表,提高性能。
(2) 验证分区策略
# EXPLAIN查看查询计划是否扫描了相关分区
EXPLAIN SELECT * FROM tb_cp_05 WHERE date=‘2013-12-01’ AND region=‘usa’;
(3) 分区选择性扫描的限制
如果查询计划显示分区表没有被选择性的扫描,可能和以下的限制有关:
- 查询计划仅可以对稳定的比较运算符,如:
=, <, <=, >, >=, <> - 查询计划不识别非稳定函数来执行选择性扫描。比如,WHERE 子句中使用如 date>CURRENT_DATE 会使查询计划执行分区扫描,而 time>TIMEOFDAY 不会。
五、序列
CREATE SEQUENCE myserial START 101; -- 创建索引
SELECT * FROM myserial; -- 查询索引
SELECT setval(‘myserial’,201); -- 设置索引
INSERT INTO tb02 VALUES(nextval(‘myserial’), ‘abc’); -- 使用索引
ALTER SEQUENCE myserial RESTART WITH 105; -- 修改索引
DROP SEQUENCE myserial; -- 删除索引
注意:如果启用了镜像功能,nextval 不允许在 UPDATE 和 DELETE 语句中被使用
六、索引
在分布式数据库如 GP 中,应保守使用索引。GP会自动为主键建立主键索引,并确保索引在查询工作负载(如表关联、查询)中真正被使用到。
GP中常用的两种:B-tree 和 Bitmap 索引。
CREATE INDEX idx_01 ON tb_cp_02(id); -- 创建 B-tree 索引
CREATE INDEX bmidx_01 ON tb_cp_02 USING BITMAP(date); -- 创建位图索引
REINDEX TABLE tb_cp_02; -- 重建全部索引
REINDEX INDEX bmidx_01; -- 重建特定索引
DROP INDEX bmidx_01; -- 删除索引,在装载数据时,通常先删除索引,再装载数据
七、视图
CREATE VIEW vw_01 AS SELECT * FROM tb_cp_03 WHERE gender=‘F’; -- 创建视图
DROP VIEW vw_01; -- 删除视图
八、数据管理
8.1 GP 事务管理
- GP 使用多版本控制模型(Mutltiversion Concurrency Control/MVCC)保持数据一致性
- MVCC 以避免给数据库事务显式锁定的方式,最大化减少锁争用以确保多用户环境下的性能
- GP 提供了各种锁机制来控制对表数据的并发访问
- GP 为每个事务提供事务隔离
(1) 表 1: GP 的并发控制-锁模式
| 锁模式 | 相关SQL命令 | 冲突的锁 |
|---|---|---|
| ACCESS SHARE | SELECT | ACCESS EXCLUSIVE |
| ROW SHARE | SELECT FOR UPDATE, SELECT FOR SHARE | EXCLUSIVE, ACCESS EXCLUSIVE |
| ROW EXCLUSIVE | INSERT, COPY | SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE, ACCESS EXCLUSIVE |
| SHARE UPDATE EXCLUSIVE | VACUUM (without FULL), ANALYZE | SHARE UPDATE EXCLUSIVE, SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE, ACCESS EXCLUSIVE |
| SHARE | CREATE INDEX | ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, SHARE ROW EXCLUSIVE, EXCLUSIVE, ACCESS EXCLUSIVE |
| SHARE ROW EXCLUSIVE | ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE, ACCESS EXCLUSIVE | |
| EXCLUSIVE | DELETE, UPDATE | ROW SHARE, ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE, ACCESS EXCLUSIVE |
(2) 事务使用
事务允许将多个 SQL 语句放在一起作为一个整体操作,所有 SQL 一起成功或失败
在 GP 中执行事务的 SQL 命令:
- 使用 BEGIN 或 START TRANSACTION 开始一个事务块
- 使用 END 或 COMMIT 提交事务块
- 使用 ROLLBACK 回滚事务而不提交任何修改
- 使用 SAVEPOINT 选择性的保存事务点,之后可以使用 ROLLBACK TO SAVEPOINT 回滚到之前保存的事务。
begin
insert into tb_cp_01 values();
savepoint p1;
insert into tb_cp_01 values();
roleback to p1;
end
(3) 事务隔离级别
SQL 标准定义了 4 个事务隔离级别:
- 未提交读:在GP中与已提交读等同
- 已提交读(缺省):当事务使用该隔离级别,SELECT查询只能看到查询开始前的数据,其永远读不到SELECT查询期间其他并发事务未提交或已提交的修改。
- 可重复读:在GP中与穿行化等同
- 可串行化:这是严格的事务隔离级别。该级别要求事务被串行执行,也就是事务必须一个接一个的执行而不是并行执行。
8.2 回收空间和分析
事务 ID 管理,在每个数据库每 2 百万个事务的时候,对每张表执行 VACUUM 是很有必要的。
- 系统目录维护:大量的 CREATE 和 DROP 命令会导致系统表的迅速膨胀,以至于影响系统性能。
- 由于 MVCC 事务并发模型的原因,已经删除或者更新的记录仍然占据着磁盘空间。
- 如果数据库有大量的更新和删除操作,将会产生大量的过期记录
- 定期的运行 VACUUM 命令可以删除过期记录,回收空间。
- 自由映射空间的设置参数:max_fsm_pages、max_fsm_relations
VACUUM tb_cp_02; -- 回收空间
ANALYZE tb_cp_02; -- 收集查询优化器需要的统计信息
8.3 日常重建索引
- 对于 B-tree 索引,新重建的索引比存在较多更新的索引更快
- 重建索引可以回收过期的空间
- 在 GP 中,删除索引然后创建通常比 REINDEX 更快
- 当更新索引列时,Bitmap 索引不会被更新
8.4 GPDB 日志文件
服务器日志文件存放在每个实例数据目录的 pg_log 目录下,格式:gpdb-YYYY-MM-DD_TIME.csv
每天用心记录一点点。内容也许不重要,但习惯很重要!
以上是关于Greeplum 系列 基本用法的主要内容,如果未能解决你的问题,请参考以下文章