转:http://www.cnblogs.com/luotianshuai/p/5206662.html
Kafka初识
1、Kafka使用背景
- 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位
- 我想对用户的搜索关键词进行统计,分析出当前的流行趋势
- 有些数据,存储数据库浪费,直接存储硬盘效率又低
Kafka相关概念
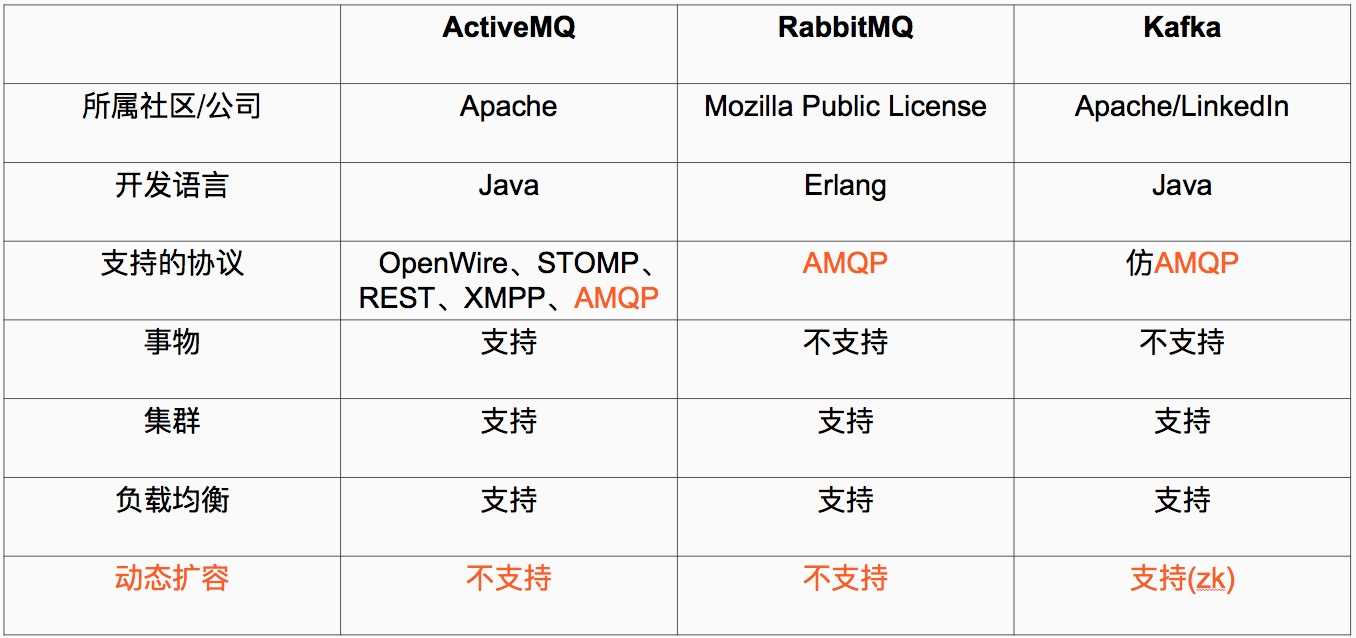
1、 AMQP协议

Zookeeper集群搭建
yum list java* yum -y install java-1.7.0-openjdk*
2、下载Zookeeper
首先要注意在生产环境中目录结构要定义好,防止在项目过多的时候找不到所需的项目
#我的目录统一放在/opt下面 #首先创建Zookeeper项目目录 mkdir zookeeper #项目目录 mkdir zkdata #存放快照日志 mkdir zkdatalog#存放事物日志
下载Zookeeper

#下载软件 cd /opt/zookeeper/ wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz #解压软件 tar -zxvf zookeeper-3.4.6.tar.gz
3、修改配置文件
#进入conf目录 /opt/zookeeper/zookeeper-3.4.6/conf #查看 [[email protected]]$ ll -rw-rw-r--. 1 1000 1000 535 Feb 20 2014 configuration.xsl -rw-rw-r--. 1 1000 1000 2161 Feb 20 2014 log4j.properties -rw-rw-r--. 1 1000 1000 922 Feb 20 2014 zoo_sample.cfg
#zoo_sample.cfg 这个文件是官方给我们的zookeeper的样板文件,给他复制一份命名为zoo.cfg,zoo.cfg是官方指定的文件命名规则。
3台服务器的配置文件
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/opt/zookeeper/zkdata dataLogDir=/opt/zookeeper/zkdatalog clientPort=12181 server.1=192.168.7.100:12888:13888 server.2=192.168.7.101:12888:13888 server.3=192.168.7.107:12888:13888 #server.1 这个1是服务器的标识也可以是其他的数字, 表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目录下面myid文件里 #192.168.7.107为集群里的IP地址,第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
配置文件解释:
#tickTime: 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。 #initLimit: 这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒 #syncLimit: 这个配置项标识 Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是5*2000=10秒 #dataDir: 快照日志的存储路径 #dataLogDir: 事物日志的存储路径,如果不配置这个那么事物日志会默认存储到dataDir制定的目录,这样会严重影响zk的性能,当zk吞吐量较大的时候,产生的事物日志、快照日志太多 #clientPort: 这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。修改他的端口改大点
创建myid文件
#server1 echo "1" > /opt/zookeeper/zkdata/myid #server2 echo "2" > /opt/zookeeper/zkdata/myid #server3 echo "3" > /opt/zookeeper/zkdata/myid
4、重要配置说明
1、myid文件和server.myid 在快照目录下存放的标识本台服务器的文件,他是整个zk集群用来发现彼此的一个重要标识。
2、zoo.cfg 文件是zookeeper配置文件 在conf目录里。
3、log4j.properties文件是zk的日志输出文件 在conf目录里用java写的程序基本上有个共同点日志都用log4j,来进行管理。
 configuration for log4j
configuration for log4j4、zkEnv.sh和zkServer.sh文件
但是可以通过命令去定期的清理。
#!/bin/bash #snapshot file dir dataDir=/opt/zookeeper/zkdata/version-2 #tran log dir dataLogDir=/opt/zookeeper/zkdatalog/version-2 #Leave 66 files count=66 count=$[$count+1] ls -t $dataLogDir/log.* | tail -n +$count | xargs rm -f ls -t $dataDir/snapshot.* | tail -n +$count | xargs rm -f #以上这个脚本定义了删除对应两个目录中的文件,保留最新的66个文件,可以将他写到crontab中,设置为每天凌晨2点执行一次就可以了。 #zk log dir del the zookeeper log #logDir= #ls -t $logDir/zookeeper.log.* | tail -n +$count | xargs rm -f
其他方法:
第二种:使用ZK的工具类PurgeTxnLog,它的实现了一种简单的历史文件清理策略,可以在这里看一下他的使用方法 http://zookeeper.apache.org/doc/r3.4.6/zookeeperAdmin.html
第三种:对于上面这个执行,ZK自己已经写好了脚本,在bin/zkCleanup.sh中,所以直接使用这个脚本也是可以执行清理工作的。
第四种:从3.4.0开始,zookeeper提供了自动清理snapshot和事务日志的功能,通过配置 autopurge.snapRetainCount 和 autopurge.purgeInterval 这两个参数能够实现定时清理了。这两个参数都是在zoo.cfg中配置的:
#进入到Zookeeper的bin目录下 cd /opt/zookeeper/zookeeper-3.4.6/bin #启动服务(3台都需要操作) ./zkServer.sh start
2、检查服务状态
#检查服务器状态 ./zkServer.sh status
通过status就能看到状态:
./zkServer.sh status JMX enabled by default Using config: /opt/zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg #配置文件 Mode: follower #他是否为领导
zk集群一般只有一个leader,多个follower,主一般是相应客户端的读写请求,而从主同步数据,当主挂掉之后就会从follower里投票选举一个leader出来。
可以用“jps”查看zk的进程,这个是zk的整个工程的main
#执行命令jps 20348 Jps 4233 QuorumPeerMain
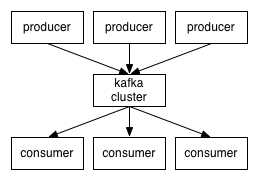
Kafka集群搭建
#创建目录 cd /opt/ mkdir kafka #创建项目目录 cd kafka mkdir kafkalogs #创建kafka消息目录,主要存放kafka消息 #下载软件 wget http://apache.opencas.org/kafka/0.9.0.1/kafka_2.11-0.9.0.1.tgz #解压软件 tar -zxvf kafka_2.11-0.9.0.1.tgz
3、修改配置文件
cd /opt/kafka/kafka_2.11-0.9.0.1/config/
主要关注:server.properties 这个文件即可,我们可以发现在目录下:
有很多文件,这里可以发现有Zookeeper文件,我们可以根据Kafka内带的zk集群来启动,但是建议使用独立的zk集群
-rw-r--r--. 1 root root 5699 Feb 22 09:41 192.168.7.101 -rw-r--r--. 1 root root 906 Feb 12 08:37 connect-console-sink.properties -rw-r--r--. 1 root root 909 Feb 12 08:37 connect-console-source.properties -rw-r--r--. 1 root root 2110 Feb 12 08:37 connect-distributed.properties -rw-r--r--. 1 root root 922 Feb 12 08:38 connect-file-sink.properties -rw-r--r--. 1 root root 920 Feb 12 08:38 connect-file-source.properties -rw-r--r--. 1 root root 1074 Feb 12 08:37 connect-log4j.properties -rw-r--r--. 1 root root 2055 Feb 12 08:37 connect-standalone.properties -rw-r--r--. 1 root root 1199 Feb 12 08:37 consumer.properties -rw-r--r--. 1 root root 4369 Feb 12 08:37 log4j.properties -rw-r--r--. 1 root root 2228 Feb 12 08:38 producer.properties -rw-r--r--. 1 root root 5699 Feb 15 18:10 server.properties -rw-r--r--. 1 root root 3325 Feb 12 08:37 test-log4j.properties -rw-r--r--. 1 root root 1032 Feb 12 08:37 tools-log4j.properties -rw-r--r--. 1 root root 1023 Feb 12 08:37 zookeeper.properties
修改配置文件:
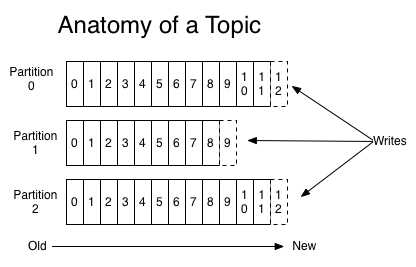
broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样 port=19092 #当前kafka对外提供服务的端口默认是9092 host.name=192.168.7.100 #这个参数默认是关闭的,在0.8.1有个bug,DNS解析问题,失败率的问题。 num.network.threads=3 #这个是borker进行网络处理的线程数 num.io.threads=8 #这个是borker进行I/O处理的线程数 log.dirs=/opt/kafka/kafkalogs/ #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个 socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能 socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘 socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小 num.partitions=1 #默认的分区数,一个topic默认1个分区数 log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天 message.max.byte=5242880 #消息保存的最大值5M default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务 replica.fetch.max.bytes=5242880 #取消息的最大直接数 log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件 log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除 log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能 zookeeper.connect=192.168.7.100:12181,192.168.7.101:12181,192.168.7.107:1218 #设置zookeeper的连接端口
上面是参数的解释,实际的修改项为:
#broker.id=0 每台服务器的broker.id都不能相同 #hostname host.name=192.168.7.100 #在log.retention.hours=168 下面新增下面三项 message.max.byte=5242880 default.replication.factor=2 replica.fetch.max.bytes=5242880 #设置zookeeper的连接端口 zookeeper.connect=192.168.7.100:12181,192.168.7.101:12181,192.168.7.107:12181
4、启动Kafka集群并测试
1、启动服务
#从后台启动Kafka集群(3台都需要启动) cd
/opt/kafka/kafka_2.11-0.9.0.1//bin #进入到kafka的bin目录
./kafka-server-start.sh -daemon ../config/server.properties
2、检查服务是否启动
#执行命令jps 20348 Jps 4233 QuorumPeerMain 18991 Kafka
3、创建Topic来验证是否创建成功
更多请看官方文档:http://kafka.apache.org/documentation.html
#创建Topic ./kafka-topics.sh --create --zookeeper 192.168.7.100:12181 --replication-factor 2 --partitions 1 --topic shuaige #解释 --replication-factor 2 #复制两份 --partitions 1 #创建1个分区 --topic #主题为shuaige ‘‘‘在一台服务器上创建一个发布者‘‘‘ #创建一个broker,发布者 ./kafka-console-producer.sh --broker-list 192.168.7.100:19092 --topic shuaige ‘‘‘在一台服务器上创建一个订阅者‘‘‘ ./kafka-console-consumer.sh --zookeeper localhost:12181 --topic shuaige --from-beginning
测试(在发布者那里发布消息看看订阅者那里是否能正常收到~):
4、其他命令
大部分命令可以去官方文档查看
4.1、查看topic
./kafka-topics.sh --list --zookeeper localhost:12181 #就会显示我们创建的所有topic
4.2、查看topic状态
/kafka-topics.sh --describe --zookeeper localhost:12181 --topic shuaige
#下面是显示信息
Topic:ssports PartitionCount:1 ReplicationFactor:2 Configs:
Topic: shuaige Partition: 0 Leader: 1 Replicas: 0,1 Isr: 1
#分区为为1 复制因子为2 他的 shuaige的分区为0
#Replicas: 0,1 复制的为0,1
#
OKkafka集群搭建完毕
5、其他说明标注
5.1、日志说明
默认kafka的日志是保存在/opt/kafka/kafka_2.10-0.9.0.0/logs目录下的,这里说几个需要注意的日志
server.log #kafka的运行日志 state-change.log #kafka他是用zookeeper来保存状态,所以他可能会进行切换,切换的日志就保存在这里 controller.log #kafka选择一个节点作为“controller”,当发现有节点down掉的时候它负责在游泳分区的所有节点中选择新的leader,这使得Kafka可以批量的高效的管理所有分区节点的主从关系。如果controller down掉了,活着的节点中的一个会备切换为新的controller.
5.2、上面的大家你完成之后可以登录zk来查看zk的目录情况
#使用客户端进入zk
./zkCli.sh -server 127.0.0.1:12181 #默认是不用加’-server‘参数的因为我们修改了他的端口
#查看目录情况 执行“ls /”
[zk: 127.0.0.1:12181(CONNECTED) 0] ls /
#显示结果:[consumers, config, controller, isr_change_notification, admin, brokers, zookeeper, controller_epoch]
‘‘‘
上面的显示结果中:只有zookeeper是,zookeeper原生的,其他都是Kafka创建的
‘‘‘
#标注一个重要的
[zk: 127.0.0.1:12181(CONNECTED) 1] get /brokers/ids/0
{"jmx_port":-1,"timestamp":"1456125963355","endpoints":["PLAINTEXT://192.168.7.100:19092"],"host":"192.168.7.100","version":2,"port":19092}
cZxid = 0x1000001c1
ctime = Mon Feb 22 15:26:03 CST 2016
mZxid = 0x1000001c1
mtime = Mon Feb 22 15:26:03 CST 2016
pZxid = 0x1000001c1
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x152e40aead20016
dataLength = 139
numChildren = 0
[zk: 127.0.0.1:12181(CONNECTED) 2]
#还有一个是查看partion
[zk: 127.0.0.1:12181(CONNECTED) 7] get /brokers/topics/shuaige/partitions/0
null
cZxid = 0x100000029
ctime = Mon Feb 22 10:05:11 CST 2016
mZxid = 0x100000029
mtime = Mon Feb 22 10:05:11 CST 2016
pZxid = 0x10000002a
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
[zk: 127.0.0.1:12181(CONNECTED) 8]