R统计基于相似系数的聚类分析
Posted 原本山川,极命草木
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R统计基于相似系数的聚类分析相关的知识,希望对你有一定的参考价值。
题目:
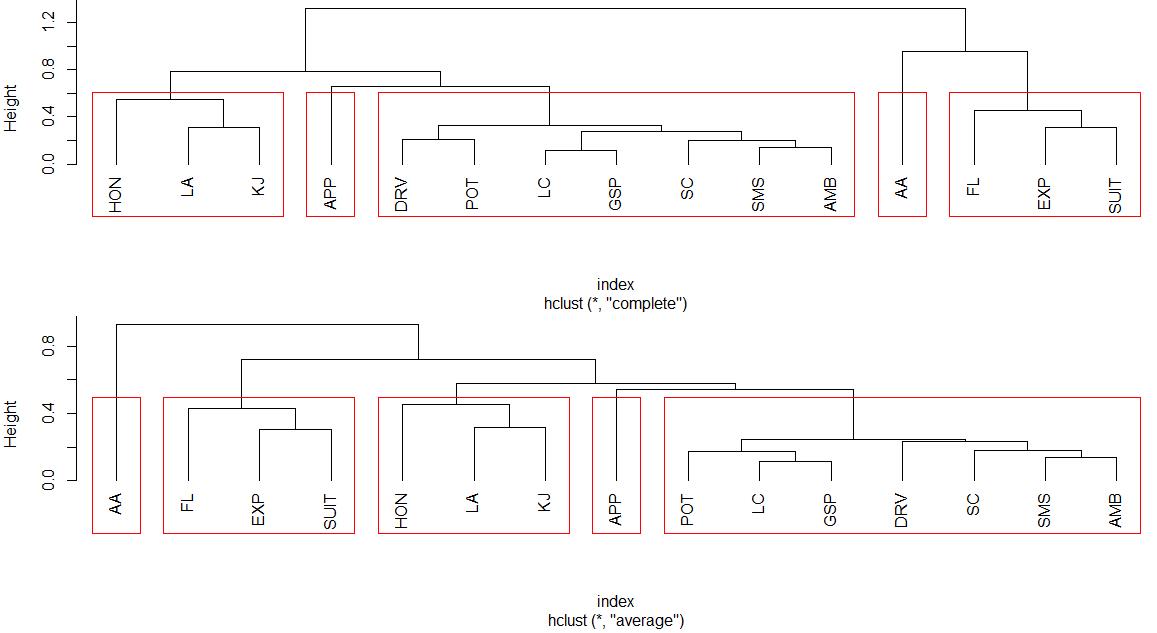
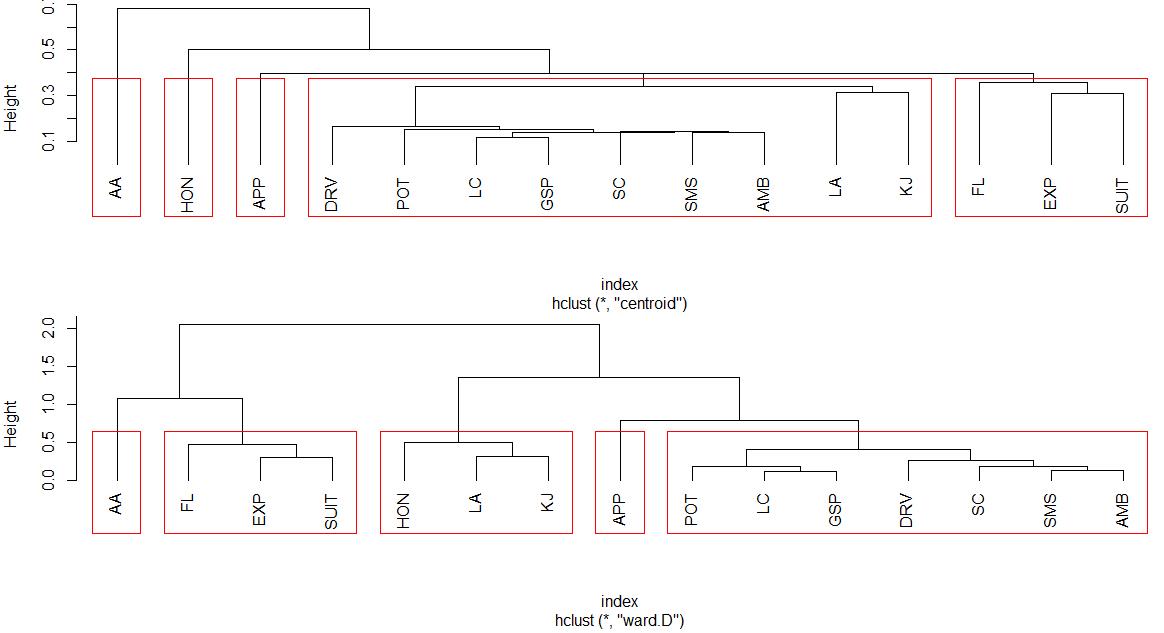
对48名应聘者数据的自变量作聚类分析,选择变量的相关系数作为变量间的相似系数(cij),距离定义为dij=1-cij。分别用最长距离法、均值法、重心法和Ward法作聚类分析,并画出相应的谱系图。如果将所有变量分为5类,试写出各种方法的分类结果。
数据(applicant.data):
FL APP AA LA SC LC HON SMS EXP DRV AMB GSP POT KJ SUIT 1 6 7 2 5 8 7 8 8 3 8 9 7 5 7 10 2 9 10 5 8 10 9 9 10 5 9 9 8 8 8 10 3 7 8 3 6 9 8 9 7 4 9 9 8 6 8 10 4 5 6 8 5 6 5 9 2 8 4 5 8 7 6 5 5 6 8 8 8 4 4 9 5 8 5 5 8 8 7 7 6 7 7 7 6 8 7 10 5 9 6 5 8 6 6 6 7 9 9 8 8 8 8 8 8 10 8 10 8 9 8 10 8 9 9 9 8 9 9 8 8 10 9 10 9 9 9 10 9 9 9 7 8 8 8 8 5 9 8 9 8 8 8 10 10 4 7 10 2 10 10 7 10 3 10 10 10 9 3 10 11 4 7 10 0 10 8 3 9 5 9 10 8 10 2 5 12 4 7 10 4 10 10 7 8 2 8 8 10 10 3 7 13 6 9 8 10 5 4 9 4 4 4 5 4 7 6 8 14 8 9 8 9 6 3 8 2 5 2 6 6 7 5 6 15 4 8 8 7 5 4 10 2 7 5 3 6 6 4 6 16 6 9 6 7 8 9 8 9 8 8 7 6 8 6 10 17 8 7 7 7 9 5 8 6 6 7 8 6 6 7 8 18 6 8 8 4 8 8 6 4 3 3 6 7 2 6 4 19 6 7 8 4 7 8 5 4 4 2 6 8 3 5 4 20 4 8 7 8 8 9 10 5 2 6 7 9 8 8 9 21 3 8 6 8 8 8 10 5 3 6 7 8 8 5 8 22 9 8 7 8 9 10 10 10 3 10 8 10 8 10 8 23 7 10 7 9 9 9 10 10 3 9 9 10 9 10 8 24 9 8 7 10 8 10 10 10 2 9 7 9 9 10 8 25 6 9 7 7 4 5 9 3 2 4 4 4 4 5 4 26 7 8 7 8 5 4 8 2 3 4 5 6 5 5 6 27 2 10 7 9 8 9 10 5 3 5 6 7 6 4 5 28 6 3 5 3 5 3 5 0 0 3 3 0 0 5 0 29 4 3 4 3 3 0 0 0 0 4 4 0 0 5 0 30 4 6 5 6 9 4 10 3 1 3 3 2 2 7 3 31 5 5 4 7 8 4 10 3 2 5 5 3 4 8 3 32 3 3 5 7 7 9 10 3 2 5 3 7 5 5 2 33 2 3 5 7 7 9 10 3 2 2 3 6 4 5 2 34 3 4 6 4 3 3 8 1 1 3 3 3 2 5 2 35 6 7 4 3 3 0 9 0 1 0 2 3 1 5 3 36 9 8 5 5 6 6 8 2 2 2 4 5 6 6 3 37 4 9 6 4 10 8 8 9 1 3 9 7 5 3 2 38 4 9 6 6 9 9 7 9 1 2 10 8 5 5 2 39 10 6 9 10 9 10 10 10 10 10 8 10 10 10 10 40 10 6 9 10 9 10 10 10 10 10 10 10 10 10 10 41 10 7 8 0 2 1 2 0 10 2 0 3 0 0 10 42 10 3 8 0 1 1 0 0 10 0 0 0 0 0 10 43 3 4 9 8 2 4 5 3 6 2 1 3 3 3 8 44 7 7 7 6 9 8 8 6 8 8 10 8 8 6 5 45 9 6 10 9 7 7 10 2 1 5 5 7 8 4 5 46 9 8 10 10 7 9 10 3 1 5 7 9 9 4 4 47 0 7 10 3 5 0 10 0 0 2 2 0 0 0 0 48 0 6 10 1 5 0 10 0 0 2 2 0 0 0 0
脚本:
rt<-read.table("applicant.data")
c<-cor(rt)
index<-as.dist(1-c)
hc1<-hclust(index, "complete")
hc2<-hclust(index, "average")
hc3<-hclust(index, "centroid")
hc4<-hclust(index, "ward")
opar<-par(mfrow=c(2,1), mar=c(5.2,4,0,0))
plclust(hc1,hang=-1)
re1<-rect.hclust(hc1,k=5,border="red")
plclust(hc2,hang=-1)
re2<-rect.hclust(hc2,k=5,border="red")
par(opar)
opar<-par(mfrow=c(2,1), mar=c(5.2,4,0,0))
plclust(hc3,hang=-1)
re3<-rect.hclust(hc3,k=5,border="red")
plclust(hc4,hang=-1)
re4<-rect.hclust(hc4,k=5,border="red")
par(opar)
图片:
博文源代码和习题均来自于教材《统计建模与R软件》(ISBN:9787302143666,作者:薛毅)。
以上是关于R统计基于相似系数的聚类分析的主要内容,如果未能解决你的问题,请参考以下文章
R语言聚类分析之基于划分的聚类KMeans实战:基于菌株数据