hbase 架构
Posted 努力,奋斗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hbase 架构相关的知识,希望对你有一定的参考价值。
在HBase中,表被分割成区域,并由区域服务器提供服务。区域被列族垂直分为“Stores”。Stores被保存在HDFS文件。
HBase有三个主要组成部分:客户端库,主服务器和区域服务器。区域服务器可以按要求添加或删除。
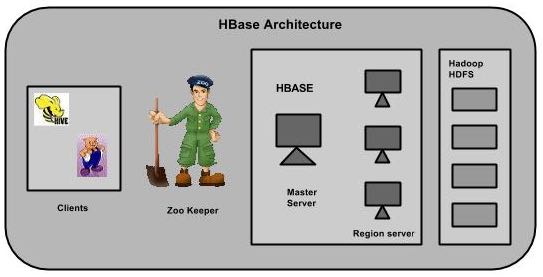
源自:https://www.yiibai.com/hbase/hbase_architecture.html
主服务器
主服务器是 -
- 分配区域给区域服务器并在Apache ZooKeeper的帮助下完成这个任务。
- 处理跨区域的服务器区域的负载均衡。它卸载繁忙的服务器和转移区域较少占用的服务器。
- 通过判定负载均衡以维护集群的状态。
- 负责模式变化和其他元数据操作,如创建表和列。
区域
区域只不过是表被拆分,并分布在区域服务器。
区域服务器
区域服务器拥有区域如下 -
- 与客户端进行通信并处理数据相关的操作。
- 句柄读写的所有地区的请求。
- 由以下的区域大小的阈值决定的区域的大小。
需要深入探讨区域服务器:包含区域和存储,如下图所示:
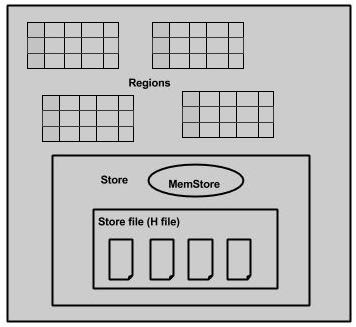
存储包含内存存储和HFiles。memstore就像一个高速缓存。在这里开始进入了HBase存储。数据被传送并保存在Hfiles作为块并且memstore刷新。
Zookeeper
- Zookeeper管理是一个开源项目,提供服务,如维护配置信息,命名,提供分布式同步等
- Zookeeper代表不同区域的服务器短暂节点。主服务器使用这些节点来发现可用的服务器。
- 除了可用性,该节点也用于追踪服务器故障或网络分区。
- 客户端通过与zookeeper区域服务器进行通信。
- 在模拟和独立模式,HBase由zookeeper来管理。
HBase 具有如下特性:
- 强一致性读写:HBase 不是“eventually consistent(最终一致性)”数据存储。这让它很适合高速计数聚合类任务;
- 自动分片(Automatic sharding): HBase 表通过 region 分布在集群中。数据增长时,region 会自动分割并重新分布;
- RegionServer 自动故障转移;
- Hadoop/HDFS 集成:HBase 支持开箱即用地支持 HDFS 作为它的分布式文件系统;
- MapReduce: HBase 通过 MapReduce 支持大并发处理;
- Java 客户端 API:HBase 支持易于使用的 Java API 进行编程访问;
- Thrift/REST API:HBase 也支持 Thrift 和 REST 作为非 Java 前端的访问;
- Block Cache 和 Bloom Filter:对于大容量查询优化, HBase 支持 Block Cache 和 Bloom Filter;
- 运维管理:HBase 支持 JMX 提供内置网页用于运维。
以上是关于hbase 架构的主要内容,如果未能解决你的问题,请参考以下文章