3.高并发教程-基础篇-之分布式全文搜索引擎elasticsearch的搭建
Posted 齐泽西
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3.高并发教程-基础篇-之分布式全文搜索引擎elasticsearch的搭建相关的知识,希望对你有一定的参考价值。
高并发教程-基础篇-之分布式全文搜索引擎elasticsearch的搭建
如果大家看了我的上一篇《2.高并发教程-基础篇-之nginx+mysql实现负载均衡和读写分离》文章,如果能很好的利用,那么其实已经可以轻松日抗千万级别的访问量了,但是如果业务涉及查询比较多,查询条件比较丰富,又或者我就想要查询的响应更快点,那么在mysql上面去做优化,其实比较辛苦,有没有更好的解决方案呢?答案是肯定的!它就是我们今天的主角,分布式全文搜索引擎elasticsearch.
技巧提示:mysql集群层主要提供核心业务逻辑的读写以及数据的冗余备份;elasticsearch负责前端的查询和展示。比如,用户的所有写操作都是在mysql的master服务器上面完成;然后通过主从机制,把数据同步至多个mysql从机,然后通过从机把数据同步至elasticsearch.因为有多个mysql从机,所有同步的时候划分合适数量的表分担至各个从机去同步,这样既可以减轻各个mysql服务器的压力,又可以更加高效同步。同步工具这里推荐logstash,大家自行搜索了解,如果遇到坑可以留言。
一、架构图: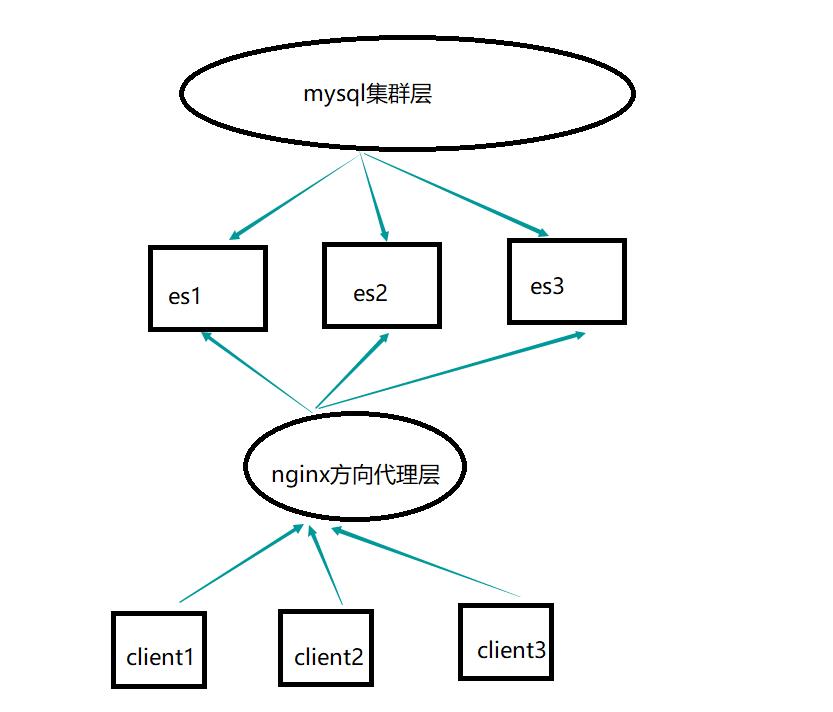
服务器准备:3台,ubuntu16.04系统+elasticsearch-6.2.4
slave1:192.168.1.191 ES集群master
slave2:192.168.1.192 ES集群slave
slave3:192.168.1.193 ES集群slave
[注意:nginx方向代理和mysql集群的配置这里不做说明,大家可以看我的之前的文章]
二、elasticsearch配置(分别在三台服务器上面进行如下操作)
1.java环境配置:
*请自行前往java官方下载java,然后解压至合适目录
vim /etc/profile加入如下内容:
#java
export JAVA_HOME=/home/qizexi/data/java #这个改为你java的解压目录
export JAVA_CLASS=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/jre/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
保存,退出
source /etc/profile
java -version看到如下内容即是java安装成功
---------------------------------------
java version "1.8.0_141"
---------------------------------------
2.账号准备:
elasticsearch不允许以root账号运行,所以我们可以添加一个es用户来负责运行elasticsearch
useradd es
passwd es
将elasticsearch-6.2.4的安装目录变更为es用户
chown -R es:es elasticsearch-6.2.4
改变ulimit的1024的限制
vim /etc/security/limits.conf
* hard nofile 100000
* soft nofile 100000
* hard nproc 100000
* soft nproc 100000
保存退出
source /etc/security/limits.conf
切换es用户(su es)之后运行
ulimit -n可以看到
100000
说明成功,否则可以重启生效:)
改变max_map_countd的限制:
vim /etc/sysctl.conf修改如下配置:
vm.max_map_count=262144
保存退出
运行:sysctl -p
3.主服务器配置(191):
cd 到elasticsearch-6.2.4的解压目录
vim config/elasticsearch.yml修改如下内容:
cluster.name: my-app
node.name: master
network.host: 192.168.1.191
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.1.191", "192.168.1.192", "192.168.1.193"]
保存,然后使用es账号启动即可.
su es
bin/elasticsearch -d
su root
netstat -tlnp看到如下内容即是成功(有可能过几秒钟才能看到):
------------------------------------------------------
192.168.1.191:9200
192.168.1.191:9300
4.配置从服务器(192,193):
cd 到elasticsearch-6.2.4的解压目录
vim config/elasticsearch.yml修改如下内容:
cluster.name: my-app
node.name: slave1 #193服务器改为slave2
network.host: 192.168.1.192 #193服务器改为192.168.1.193
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.1.191", "192.168.1.192", "192.168.1.193"]
保存,然后使用es账号启动即可.
su es
bin/elasticsearch -d
su root
netstat -tlnp看到如下内容即是成功(有可能过几秒钟才能看到):
-------------------------------------------------------
192.168.1.192:9200 #192上面看到是193
192.168.1.192:9300 #192上面看到是193
5.查看集群的状态:
curl -XGET \'http://192.168.1.191:9200/_cat/nodes?v\'
看到三个节点即可成功:
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.1.191 25 55 0 0.00 0.01 0.00 mdi * master
192.168.1.192 22 97 5 0.70 0.34 0.17 mdi - slave1
192.168.1.193 20 75 30 0.54 0.14 0.05 mdi - slave2
以上是关于3.高并发教程-基础篇-之分布式全文搜索引擎elasticsearch的搭建的主要内容,如果未能解决你的问题,请参考以下文章