

但是,这个接口在没有登录的情况下会有请求频率检测。如果一段时间内访问太过频繁,比如打开这个链接,一直不断刷新,则会看到请求频率过高的提示,如下图所示。


一、本节目标
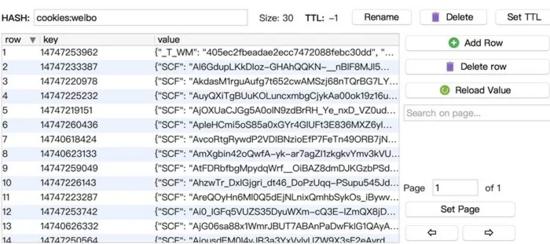
我们以新浪微博为例来实现一个Cookies池的搭建过程。Cookies池中保存了许多新浪微博账号和登录后的Cookies信息,并且Cookies池还需要定时检测每个Cookies的有效性,如果某Cookies无效,那就删除该Cookies并模拟登录生成新的Cookies。同时Cookies池还需要一个非常重要的接口,即获取随机Cookies的接口,Cookies运行后,我们只需请求该接口,即可随机获得一个Cookies并用其爬取。
由此可见,Cookies池需要有自动生成Cookies、定时检测Cookies、提供随机Cookies等几大核心功能。
二、准备工作
搭建之前肯定需要一些微博的账号。需要安装好Redis数据库并使其正常运行。需要安装Python的RedisPy、requests、Selelnium、Flask库。另外,还需要安装Chrome浏览器并配置好ChromeDriver。
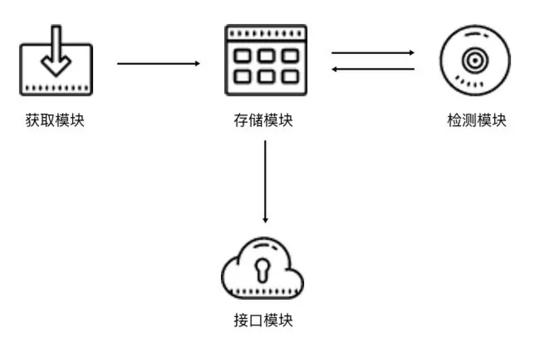
三、Cookies池架构
Cookies的架构和代理池类似,同样是4个核心模块,如下图所示。

四、Cookies池的实现
首先分别了解各个模块的实现过程。



2. 生成模块
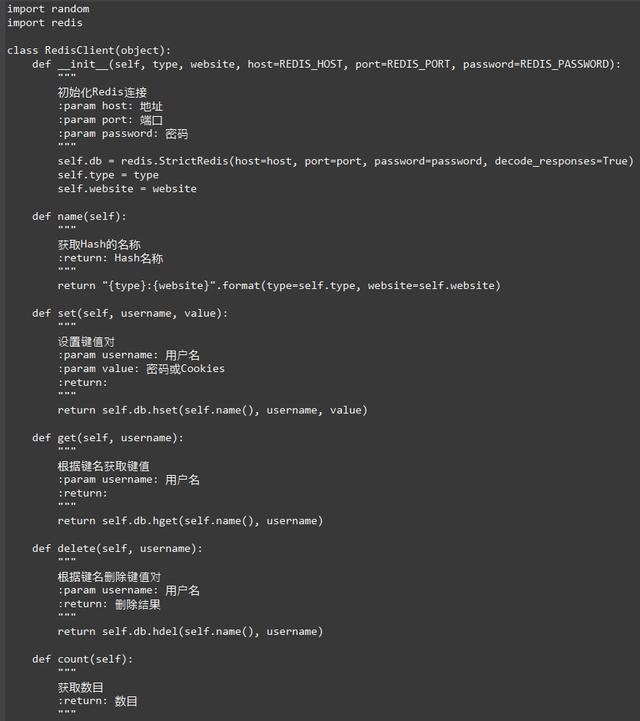
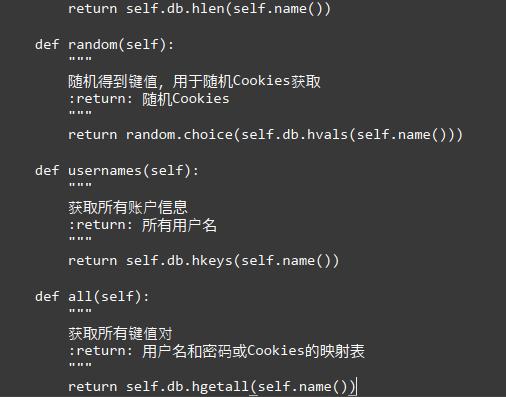
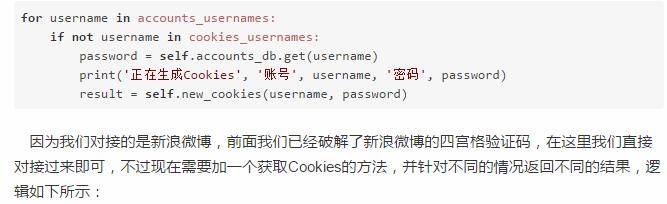
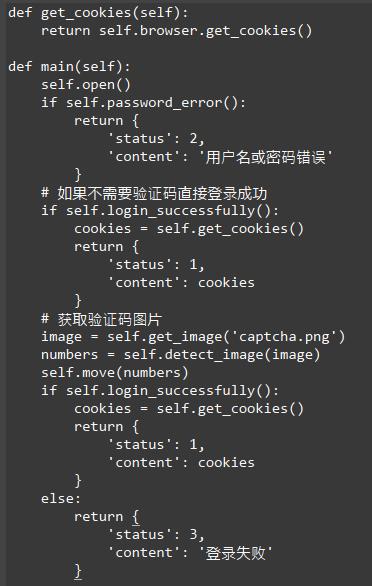
生成模块负责获取各个账号信息并模拟登录,随后生成Cookies并保存。我们首先获取两个Hash的信息,看看账户的Hash比Cookies的Hash多了哪些还没有生成Cookies的账号,然后将剩余的账号遍历,再去生成Cookies即可。
这里主要逻辑就是找出那些还没有对应Cookies的账号,然后再逐个获取Cookies,代码如下:



3. 检测模块
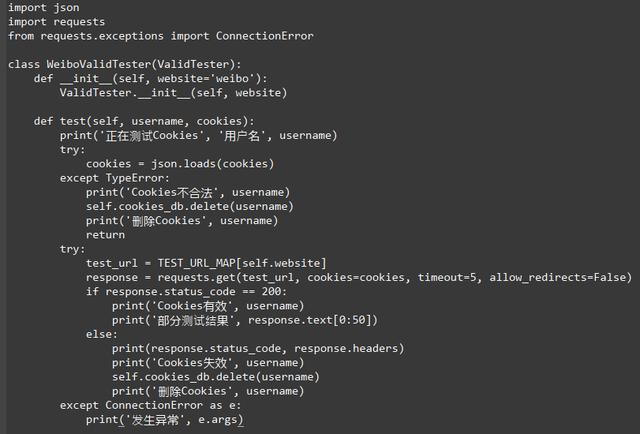
我们现在可以用生成模块来生成Cookies,但还是免不了Cookies失效的问题,例如时间太长导致Cookies失效,或者Cookies使用太频繁导致无法正常请求网页。如果遇到这样的Cookies,我们肯定不能让它继续保存在数据库里。




4. 接口模块
生成模块和检测模块如果定时运行就可以完成Cookies实时检测和更新。但是Cookies最终还是需要给爬虫来用,同时一个Cookies池可供多个爬虫使用,所以我们还需要定义一个Web接口,爬虫访问此接口便可以取到随机的Cookies。我们采用Flask来实现接口的搭建,代码如下所示:
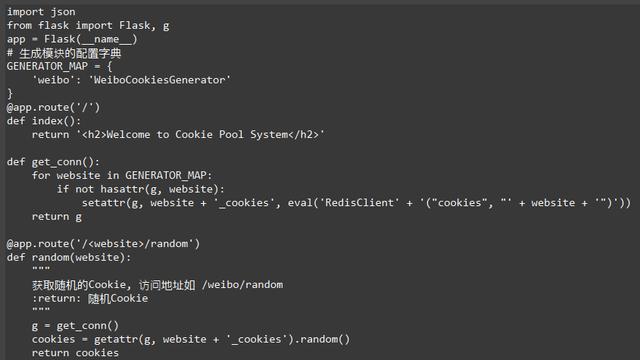
我们同样需要实现通用的配置来对接不同的站点,所以接口链接的第一个字段定义为站点名称,第二个字段定义为获取的方法,例如,/weibo/random是获取微博的随机Cookies,/zhihu/random是获取知乎的随机Cookies。
5. 调度模块
最后,我们再加一个调度模块让这几个模块配合运行起来,主要的工作就是驱动几个模块定时运行,同时各个模块需要在不同进程上运行,实现如下所示:
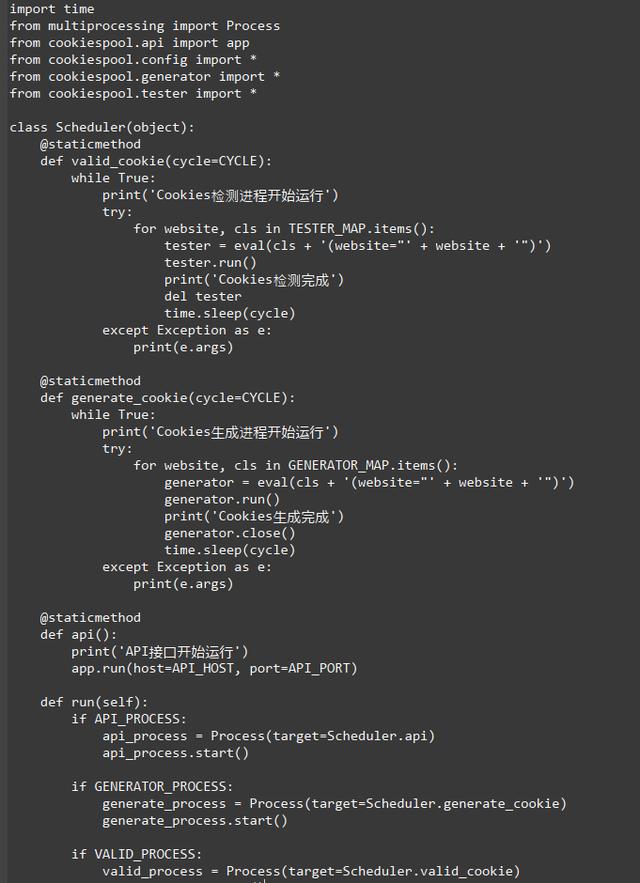
这里用到了两个重要的配置,即产生模块类和测试模块类的字典配置,如下所示:

Scheduler里将字典进行遍历,同时利用 eval() 动态新建各个类的对象,调用其入口run() 方法运行各个模块。同时,各个模块的多进程使用了multiprocessing中的Process类,调用其 start() 方法即可启动各个进程。
另外,各个模块还设有模块开关,我们可以在配置文件中自由设置开关的开启和关闭,如下所示:
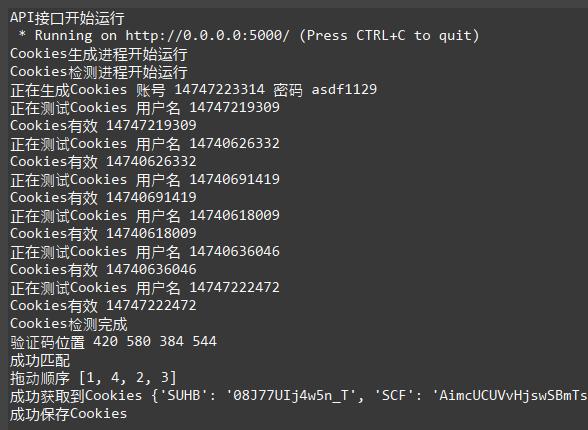
以上所示是程序运行的控制台输出内容,我们从中可以看到各个模块都正常启动,测试模块逐个测试Cookies,生成模块获取尚未生成Cookies的账号的Cookies,各个模块并行运行,互不干扰。
我们可以访问接口获取随机的Cookies,如下图所示。
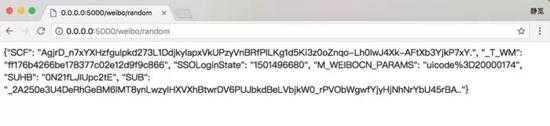
爬虫只需要请求该接口就可以实现随机Cookies的获取。
五、本节代码

欢迎大家关注我的博客:https://home.cnblogs.com/u/sm123456/