Flask上下文源码分析
Posted 大雷同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flask上下文源码分析相关的知识,希望对你有一定的参考价值。
flask中的上下文分两种,application context和request context,即应用上下文和请求上下文。
从名字上看,可能会有误解,认为应用上下文是一个应用的全局变量,所有请求都可以访问修改其中的内容;而请求上下文则是请求内可访问的内容。
但事实上,这两者并不是全局与局部的关系,它们都处于一个请求的局部中。
先说结论:每个请求的g都是独立的,并且在整个请求内都是可访问修改的。
下面来研究一下。
上下文类的定义:
上下文类定义在flask.ctx模块中
class AppContext(object):
def __init__(self, app):
self.app = app
self.url_adapter = app.create_url_adapter(None)
self.g = app.app_ctx_globals_class()
# Like request context, app contexts can be pushed multiple times
# but there a basic "refcount" is enough to track them.
self._refcnt = 0
self.app = app
self.url_adapter = app.create_url_adapter(None)
self.g = app.app_ctx_globals_class()
# Like request context, app contexts can be pushed multiple times
# but there a basic "refcount" is enough to track them.
self._refcnt = 0
查看了源代码,AppContext类即是应用上下文,可以看到里面只保存了几个变量,其中比较重要的有:
app是当前web应用对象的引用,如Flask;还有g,用来保存需要在每个请求中需要用到的请求内全局变量。
class RequestContext(object):
def __init__(self, app, environ, request=None):
self.app = app
if request is None:
request = app.request_class(environ)
self.request = request
self.url_adapter = app.create_url_adapter(self.request)
self.flashes = None
self.session = None
# Request contexts can be pushed multiple times and interleaved with
# other request contexts. Now only if the last level is popped we
# get rid of them. Additionally if an application context is missing
# one is created implicitly so for each level we add this information
self._implicit_app_ctx_stack = []
self.app = app
if request is None:
request = app.request_class(environ)
self.request = request
self.url_adapter = app.create_url_adapter(self.request)
self.flashes = None
self.session = None
# Request contexts can be pushed multiple times and interleaved with
# other request contexts. Now only if the last level is popped we
# get rid of them. Additionally if an application context is missing
# one is created implicitly so for each level we add this information
self._implicit_app_ctx_stack = []
RequestContext即请求上下文,其中有我们熟悉的request和session,app和应用上下文中的app含义相同。
上下文对象的作用域
那么这两种上下文运行时是怎么被使用的呢?
线程有个叫做ThreadLocal的类,也就是通常实现线程隔离的类。而werkzeug自己实现了它的线程隔离类:werkzeug.local.Local。LocalStack就是用Local实现的。
在flask.globals模块中定义了两个LocalStack对象:
_request_ctx_stack = LocalStack()
_app_ctx_stack = LocalStack()
_app_ctx_stack = LocalStack()
LocalStack是flask定义的线程隔离的栈存储对象,分别用来保存应用和请求上下文。
它是线程隔离的意思就是说,对于不同的线程,它们访问这两个对象看到的结果是不一样的、完全隔离的。这是根据pid的不同实现的,类似于门牌号。
而每个传给flask对象的请求,都是在不同的线程中处理,而且同一时刻每个线程只处理一个请求。所以对于每个请求来说,它们完全不用担心自己上下文中的数据被别的请求所修改。
然后就可以解释这个特性:从flask模块中引入的g、session、request、current_app是怎么做到同一个对象能在所有请求中使用并且不会冲突。
这几个对象还是定义在flask.globals中:
current_app = LocalProxy(_find_app)
request = LocalProxy(partial(_lookup_req_object, ‘request‘))
session = LocalProxy(partial(_lookup_req_object, ‘session‘))
g = LocalProxy(partial(_lookup_app_object, ‘g‘))
request = LocalProxy(partial(_lookup_req_object, ‘request‘))
session = LocalProxy(partial(_lookup_req_object, ‘session‘))
g = LocalProxy(partial(_lookup_app_object, ‘g‘))
LocalProxy类的构造函数接收一个callable参数,上面这几个就传入了一个偏函数。以g为例,当对g进行操作时,就会调用作为参数的偏函数,并把操作转发到偏函数返回的对象上。
查看这几个函数的实现:
def _lookup_req_object(name):
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(‘working outside of request context‘)
return getattr(top, name)
def _lookup_app_object(name):
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(‘working outside of application context‘)
return getattr(top, name)
def _find_app():
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(‘working outside of application context‘)
return top.app
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(‘working outside of request context‘)
return getattr(top, name)
def _lookup_app_object(name):
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(‘working outside of application context‘)
return getattr(top, name)
def _find_app():
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(‘working outside of application context‘)
return top.app
由于_app_ctx_stack和_request_ctx_stack都是线程隔离的,所以对g的调用就是这样一个过程:
访问g-->从当前线程的应用上下文栈顶获取应用上下文-->取出其中的g对象-->进行操作。
所以可以通过一个g对象而让所有线程互不干扰的访问自己的g。
上下文对象的推送
构建Flask对象后并不会推送上下文,而在Flask对象调用run()作为WSGI 应用启动后,每当有请求进入时,在推送请求上下文前,如果有必要就会推送应用上下文。但运行了run就会阻塞程序,所以在shell中调试时,必须手动推送上下文;或者使用flask-scripts,它运行的任务会在开始时自动推送。
上面加粗的“如果有必要”,那么什么叫有必要呢?是不是意味着在每个线程里应用上下文只会被推送一次、一次请求结束下一次请求来的时候就不用再推送应用上下文了呢?
来看RequestContext的源码,push函数:
def push(self):
top = _request_ctx_stack.top
if top is not None and top.preserved:
top.pop(top._preserved_exc)
# Before we push the request context we have to ensure that there
# is an application context.
app_ctx = _app_ctx_stack.top
if app_ctx is None or app_ctx.app != self.app:
app_ctx = self.app.app_context()
app_ctx.push()
self._implicit_app_ctx_stack.append(app_ctx)
else:
self._implicit_app_ctx_stack.append(None)
_request_ctx_stack.push(self)
if top is not None and top.preserved:
top.pop(top._preserved_exc)
# Before we push the request context we have to ensure that there
# is an application context.
app_ctx = _app_ctx_stack.top
if app_ctx is None or app_ctx.app != self.app:
app_ctx = self.app.app_context()
app_ctx.push()
self._implicit_app_ctx_stack.append(app_ctx)
else:
self._implicit_app_ctx_stack.append(None)
_request_ctx_stack.push(self)
flask在推送请求上下文的时候调用push函数,他会检查当前线程的应用上下文栈顶是否有应用上下文;如果有,判断与请求上下文是否属于同一个应用。在单WSGI应用的程序中,后者的判断无意义。
此时,只要没有应用上下文就会推送一个当前应用的上下文,并且把该上下文记录下来。
请求处理结束,调用auto_pop函数,其中又调用自身的pop函数:
def pop(self, exc=None):
app_ctx = self._implicit_app_ctx_stack.pop()
………………
………………
rv = _request_ctx_stack.pop()
# Get rid of the app as well if necessary.
if app_ctx is not None:
app_ctx.pop(exc)
if app_ctx is not None:
app_ctx.pop(exc)
会把请求上下文和应用上下文都pop掉。
故,在单WSGI应用环境下,每个请求的两个上下文都是完全独立的(独立于线程上曾经的请求,独立于其他线程的请求)。Q.E.D
那么,什么时候没必要推送呢?事实上,每次请求到来的时候都会推送,都是有必要的。因为当Flask在作为WSGI应用运行的时候,不可能出现当前线程的应用上下文已存在的情况。
那么就要搞清什么时候会有已存在的应用上下文。
该博文在最后提到了“两个疑问”:①应用和请求上下文在运行时都是线程隔离的,为何要分开来?②每个线程同时只处理一个请求,上下文栈肯定只有一个对象,为何要用栈来存储?
博主认为,这两个设计都是为了在离线状态下调试用:
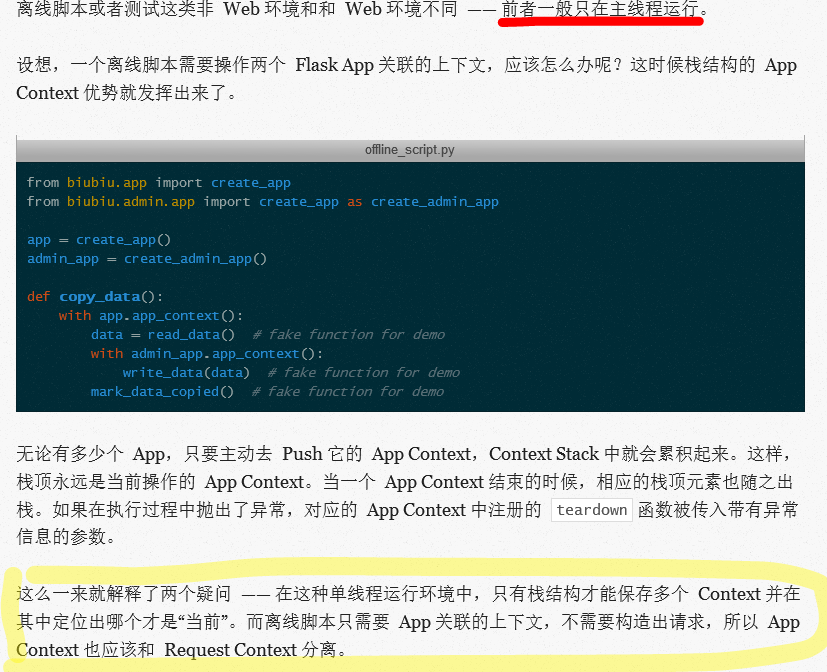
所以,综上所述,在非离线状态下,上下文栈在每个WSGI应用里是独立的,而每个应用里线程同时只处理一个请求,故上下文栈肯定只有一个对象。并且,在请求结束后都会释放,所以新的请求来的时候都会重新推送两个上下文。
小结:
解释了这么多,对于flask编程来说,只有一个应用上的结论:每个请求的g都是独立的,并且在整个请求内都是可访问修改的。
ps.本来只是想知道能否在请求中保存一个变量,就研究了g的生存周期和作用范围,最后花了5个小时左右读了flask英文文档、各种博文和源代码,写了这些文字。我这对于细枝末节的东西吹毛求疵的精神真是害苦了我。。。
附上一些其他的笔记:
全局变量g,会在每次请求到来时重置
flask.gJust store on this whatever you want. For example a database connection or the user that is currently logged in.
Starting with Flask 0.10 this is stored on the application context and no longer on the request context which means it becomes available if only the application context is bound and not yet a request
这个意思是g在应用上下文,而不是请求上下文。只要push了应用上下文就可以使用g对象
不要误解为g是整个程序内共享的
The application context is created and destroyed as necessary. It never moves between threads and it will not be shared between requests.
推送程序上下文:app = Flask(xxx), app.app_context().push() 推送了程序上下文,g可以使用,当前线程的current_app指向app
以上是关于Flask上下文源码分析的主要内容,如果未能解决你的问题,请参考以下文章