spark示例:二次排序
Posted zzhangyuhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark示例:二次排序相关的知识,希望对你有一定的参考价值。
我们有这样一个文件



首先我们的思路是把输入文件数据转化成键值对的形式进行比较不就好了嘛!
但是你要明白这一点,我们平时所使用的键值对是不具有比较意义的,也就说他们没法拿来直接比较。
我们可以通过sortByKey,sortBy(pair._2)来进行单列的排序,但是没法进行两列的同时排序。
那么我们该如何做呢?
我们可以自定义一个键值对的比较类来实现比较,
类似于JAVA中自定义类实现可比较性实现comparable接口。
我们需要继承Ordered和Serializable特质来实现自定义的比较类。
1.读取数据创建rdd
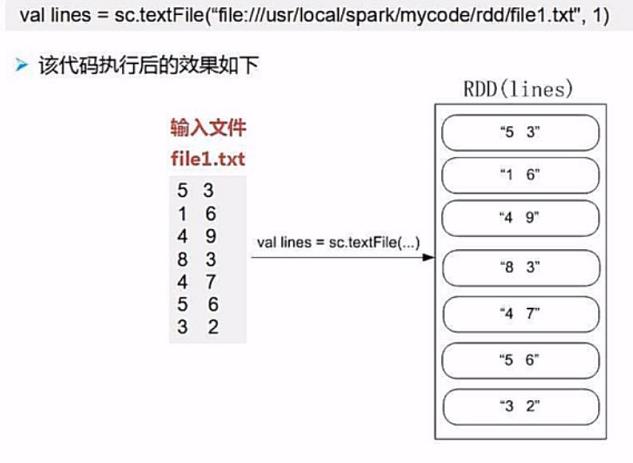
2.根据要求来定义比较类
任务要求,先根据key进行排序,相同再根据value进行排序。
我们可以把键值对当成一个数据有两个数字,先通过第一个数字比大小,再通过第二个数字比大小。
(1)我们定义两个Int参数的比较类
(2)继承Ordered 和 Serializable 接口 实现 compare 方法实现可以比较
class UDFSort (val first:Int,val second:Int) extends Ordered[UDFSort] with Serializable {
override def compare(that: UDFSort): Int = {
if(this.first - that.first != 0){//第一个值不相等的时候,直接返回大小
this.first - that.first //返回值
}
else {//第一个值相等的时候,比较第二个值
this.second - that.second
}
}
}
其实,懂java的人能看出来这个跟实现comparable很类似。
3.处理rdd
我们将原始数据按照每行拆分成一个含有两个数字的数组,然后传入我们自定义的比较类中
不是可以通过UDFSort就可以比较出结果了吗,
但是我们不能把结果给拆分掉,也就是说,我们只能排序,不能改数据。
我们这样改怎么办?
我们可以生成键值对的形式,key为UDFSort(line(0),line(1)),value为原始数据lines。
这样,我们通过sortByKey就能完成排序,然后通过取value就可以保持原始数据不变。

4.排序取结果

完整代码
package SparkDemo
import org.apache.spark.{SparkConf, SparkContext}
class UDFSort (val first:Int,val second:Int) extends Ordered[UDFSort] with Serializable {//自定义比较类
override def compare(that: UDFSort): Int = {
if(this.first - that.first != 0){//第一个值不相等的时候,直接返回大小
this.first - that.first //返回值
}
else {//第一个值相等的时候,比较第二个值
this.second - that.second
}
}
}
object Sort{
def main(args:Array[String]): Unit ={
//初始化配置:设置主机名和程序主类的名字
val conf = new SparkConf().setAppName("UdfSort");
//通过conf来创建sparkcontext
val sc = new SparkContext(conf);
val lines = sc.textFile("file:///...")
//转换为( udfsort( line(0),line(1) ),line ) 的形式
val pair = lines.map(line => (new UDFSort(line.split(" ")(0).toInt,line.split(" ")(1).toInt),line))
//对key进行排序,然后取value
val result = pair.sortByKey().map( x => x._2)
}
}
以上是关于spark示例:二次排序的主要内容,如果未能解决你的问题,请参考以下文章