互联网服务端技术——如何学(下C)
Posted 简单的老王
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了互联网服务端技术——如何学(下C)相关的知识,希望对你有一定的参考价值。
老王又在周日的下午来骚扰你了,今天给你带来的应该是这个系列的最后一篇~ 前面该铺垫的都做的差不多了(如果没看过老王之前的文章,请打开微信关注:simplemain),今天给大家聊聊很现实的、距离大家平时生活接触到的一些技术。
题外话:老王一直这样认为,计算机科学是一门实践科学,脱离了实践的计算机技术大部分是扯淡的(比如:中国高校的大部分毕业论文)。好吧,跟老王一起来吧~
今天聊的是一些通用的分布式系统的架构设计:动态聚合系统、内容检索系统、通用评论系统等。这里面有些是老王实际做过的,有些是老王自己琢磨还没有实际落地的。因为架构设计是一个开放性的问题,没有标准答案,所以需要按照应用的具体情况(流量、数据量等)来设定。如果老王说的不对,请大家指正哈~
因为这一系列文章主要是一个概述,所以系统只讲大概的设计原理,后面老王会慢慢一个系统一个系统的讲透,包括原理、关键部件的设计和实现等。大家如果有兴趣,就关注老王,听老王慢慢扯技术的淡吧~
动态聚合系统
这个系统是大家平时可能用的最多的一个系统,他要完成的功能,就是微信朋友圈、微博等:你的好友或者你关注的对象发了一个消息、一篇文章,你就可以看到;或者是你发了一个动态,你的朋友就能看到。大家有没有想过这个系统怎么实现的呢?
老王有幸在几年前实现过这样的系统,那个时候开心网还很流行(偷菜、抢车位),贴吧正好要做一个叫做i贴吧的东东,也是实现类似功能。老王负责这个系统的后台开发。后来回到成都,在百词斩也实现了类似的这个功能。
这个系统抽象一下,功能描述就是这样的:
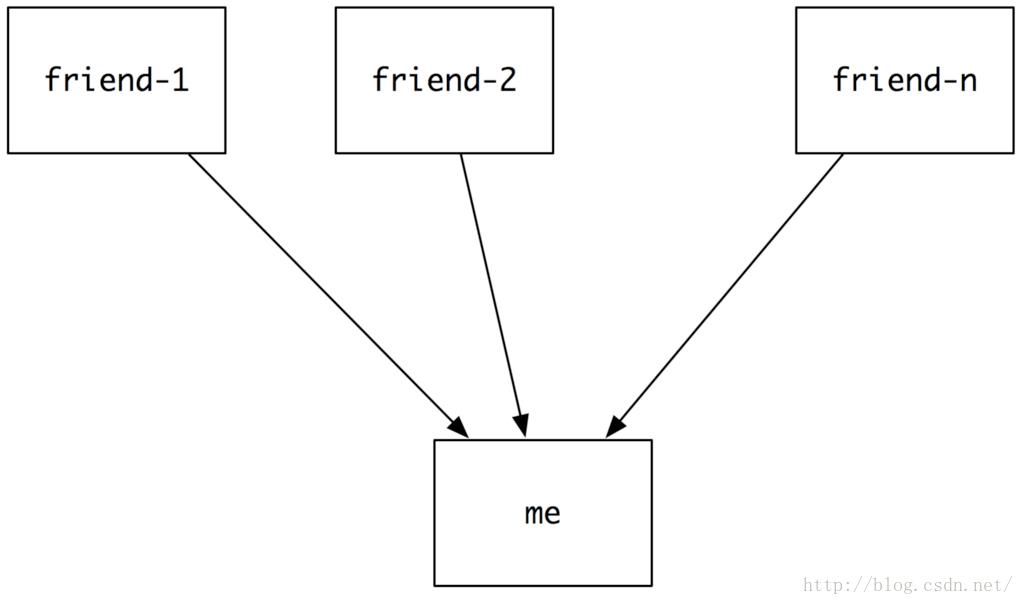
我的好友(或者我关注的人)发了一个动态,这个动态就会推给我,让我能看到。那怎么实现的呢?
ps:为了说起来方便,以下我们就统一说成“被关注者”(比如我的好友或者是微博大V)和“粉丝”(就是我),这样方便大家理解,免得说的绕口。
第一种:推(push)
这是很天然的一种方式。每个粉丝都有一个像邮箱一样的盒子,用来装被关注者推送过来的动态,当刷新动态的时候,就会从盒子里取出最新的动态展示给你。
对于粉丝不多的系统来讲(比如:微信朋友圈,平均每个人最多被一两百个朋友关注),这是一个非常天然的设计。一条动态发出来,就投递到所有粉丝的邮箱。由于量不大,整个投递过程非常短(投递的时候,可以借助消息队列(Message Queue)来完成)。
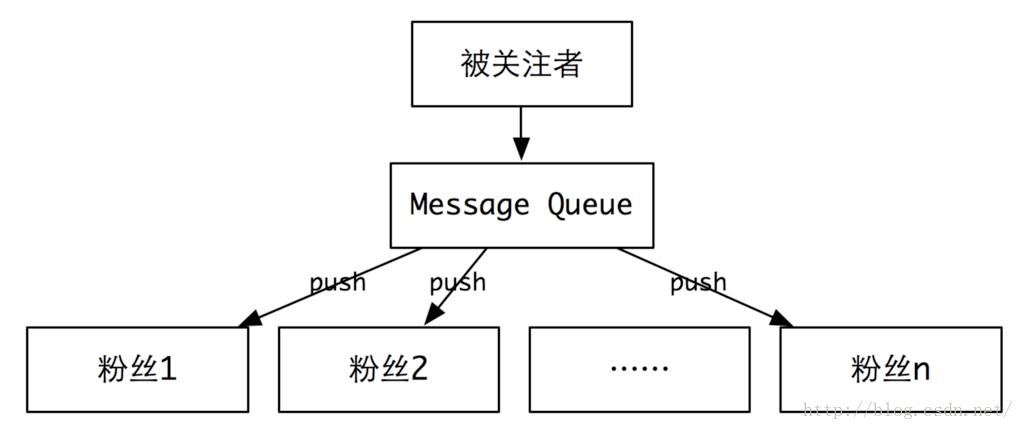
不过,当粉丝很多的时候(比如:微博的大V,有几百万甚至上千万的粉丝)的时候,这种方式就有点吃不消,比如推送一个粉丝需要10个毫秒,那么1000万粉丝就需要100000秒,也就是说,如果这个大V发一个消息,你要大概30个小时以后,才能看到。如果是一个实时信息,你能接受么?!
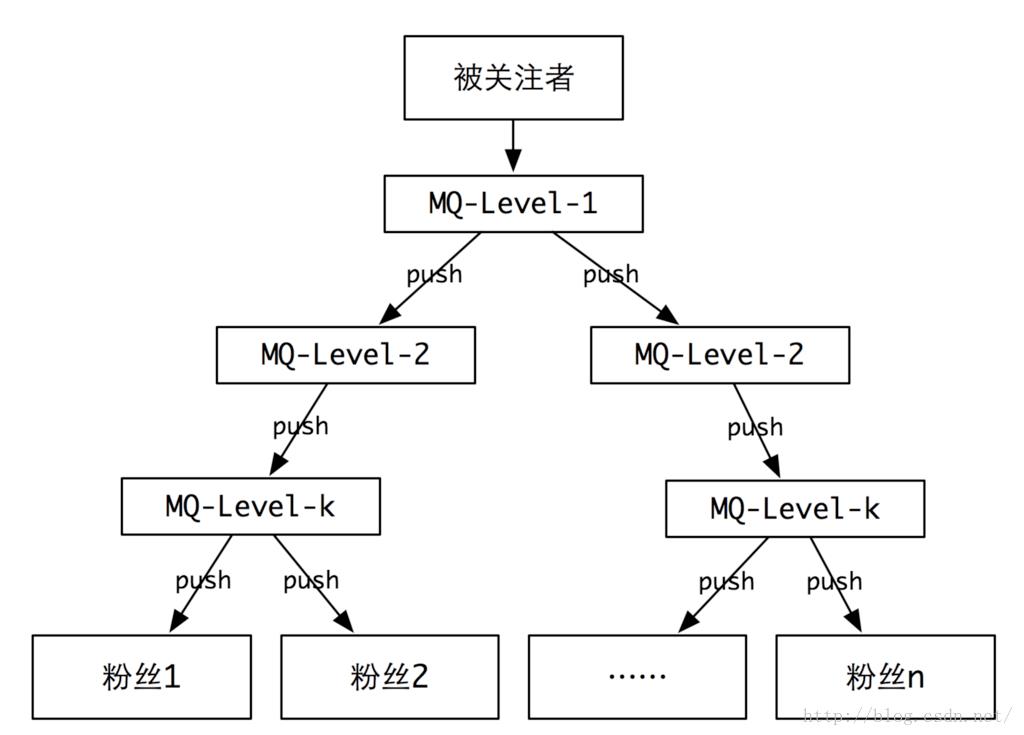
其实如果非要用这种方式来实现也是可以的,只是需要对这种推的方式做优化。我们可以借助算法里面的优化思想,用分层的多级推送,类似一棵多叉树,将一个O(n)复杂度的算法降低到O(lgn)。不过用这种方式实现整体的代价会比较大。那我们有没有其他的方式来实现呢?
第二种:拉(pull)
这个时候,每个粉丝不再拥有一个邮箱盒子。而是每次刷新动态的时候,去找你的被关注者要最新的动态,然后将所有的这些动态进行时间排序、合并等操作,最后展示到你的面前。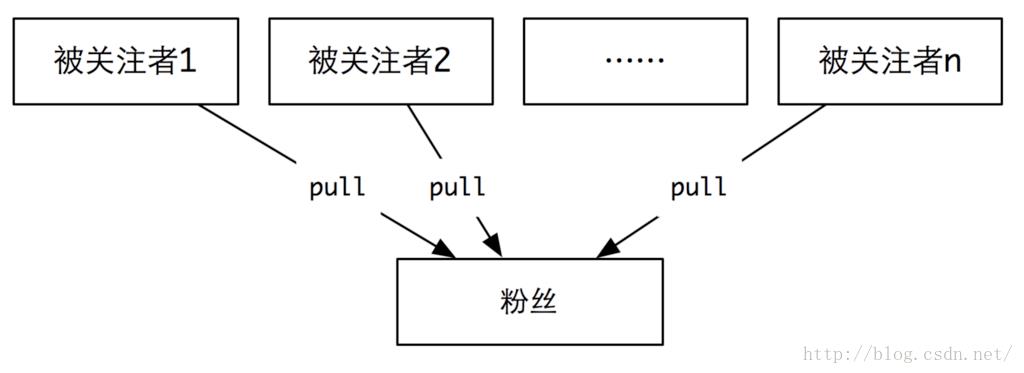
这种方式相对于前一种,更像是懒惰(lazy)模式。要才取,不要就不管。这种模式的优点就是大V发送消息的时候,系统没有太大的压力。而当用户读取的时候,才会有压力过来。实际上,这是将写压力转化成了读的时候的压力。
那这种实现方式是不是就没有问题呢?当然不是,比如你关注了成千上万个人,那你要是刷新一次,需要多少时间呢?如果我们算平均取一个好友的动态需要10毫秒,那么如果有1万关注,串行的来做就需要100秒,也就是差不多2分钟……你有耐心去等待刷一个朋友圈需要2分钟么?
那这种方式有优化的办法么?当然有。不过就是需要从产品和技术两头去折中。比如,你看好友动态的时候,如果这1万个被关注者都有更新,你看的过来么?必然是看不过来的。这个时候,我们就可以将最后更新的100个人的动态聚合出来给你。你看到这100个人,心里已经就很满足了,对吧~ (况且,1万个被关注者同时更新的可能性也极小)
另外,对于每个被关注者的动态,也可以用cache去缓存,就不用每次读数据库或者数据文件,可以极大的提升访问效率。
上面两种方式是不是看明白了呢?除了刚刚说的发动态,其实还有删除动态的问题。比如某人发了xx言论,觉得不好,要删掉,也会有同样的推、拉引起的问题。
好了,具体到我们现有的系统怎么来实现的呢?当时在贴吧的时候,由于存在大V这样的形态,所以最终选择了拉的方式,实现起来成本相对低一些。而微博据说是用的推拉结合,没有仔细考证过,这里就不评论了。
内容检索系统
这个系统,说白了就是google或者百度。你输入一段文字,给你把相关的文章找出来;或者是你输入一个单词,帮你把对应的释义找出来;你输入一个用户的昵称,帮你把对应的用户找出来……
老王在当年学校里创业的时候,用过Lucene(apache的开源项目)来做检索。当时完全不知道他的工作原理,就觉得这玩意儿真是牛逼啊,给他文章就能搜索出东西来。后来去了百度才知道,哦,原来是一个叫做分词和倒排索引的东东在起作用。回成都后,在百词斩指导相关同事做了用户搜索。
那具体怎么做呢?
实际上整个过程分成两大块:
提交部分:对内容切分(分词)和建倒排索引;
查询部分:源数据查询和内容合并排序。
先来看看提交部分:
当一个文本被提交到检索系统后(比如:爬虫爬取下来的网页,或者新用户注册到系统等),检索系统就先对文本进行切分。需要注意的是,切分需要按业务形态来进行。
比如对于百度这样的搜索引擎来将,文章是由词来构成,单个的字意义不大,所以,按词进行切分就是最合理的,自然就用到了分词的算法。
而对于用户名的检索,因为用户名本身比较短,且经常是无意义的几个字的组合,所以以字为单位就更有价值,切分就自然按照字为单位切分。
为了统一说法,我们不妨说最后切分的结果都叫做segment(简称s)。那我们就很容易将一篇文章article(简称a)切分成s1, s2, ..., sn的一个集合。就是如下这个关系:
a -> s1 s2 ... sn
我们叫这样的关系为正排拉链(就是按正常的逻辑排列的)。
如果有很多篇文章,分别切分的结果是:
a1 -> s1 s3 s4 s6
a2 -> s1 s2 s3
a3 -> s3 s6
对于这样的一个结果,我们可以反过来建立一个列表:
s1 -> a1 a2
s2 -> a2
s3 -> a1 a2 a3
s4 -> a1
s6 -> a1 a3
这样,我们就可以建立一个segment到article的对应列表,我们把这种列表叫做倒排拉链。
当我们要查找哪些文章含有s1的时候,就很明显可以直接输出a1和a2,对吧~
接下来我们看看查找部分:
由于数据量很大,我们有可能把s1,s2...sn的倒排拉链放到不同的服务器上,这个时候,我们就要先根据用户的请求,去不同的服务器找到对应的拉链数据。比如,用户输入了s1和s6,我们就要去他们所在的服务器找到对应的拉链。这是第一步。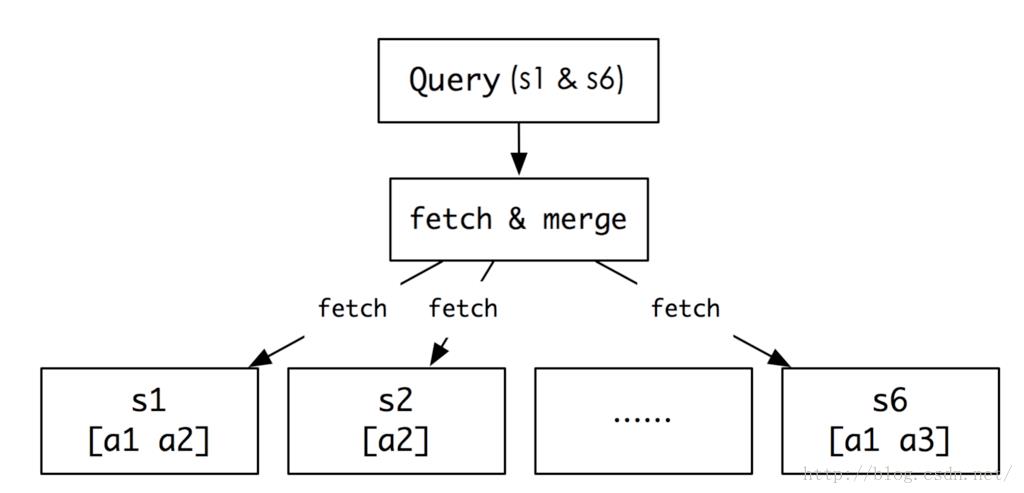
接下来,我们就要对s1和s6的拉链结果进行合并和排序。合并的结果可能是这样的:a1出现2次,a2和a3各出现一次。明显,a1是最相关的,因此可能排在最前面(注意,这里说的是可能),a2和a3排在后面。那是不是一定就是这样的结果呢?不一定。比如有一种case,就是按时间优先排序的话,如果a1是一篇很老的新闻,那么有可能就不会排在前面展示,而是在后面。这就是看具体的业务需求来对结果排序。比如:新闻类的服务,一般会更强调实时性;电商类的服务,一般更关注信用度;百度这样的通用搜索引擎则更强调相关度。
好了,检索系统基本上就是这样一个工作的原理,老王讲清楚了嘛?
通用评论系统
这个系统可能是我们在平时生活中用的最多的一个系统之一了。朋友圈里评论一下、论坛里做个回复、买了东西做个评价……

以上是关于互联网服务端技术——如何学(下C)的主要内容,如果未能解决你的问题,请参考以下文章