开源爬虫框架哪家强?是骡子是马,拉出来溜溜就知道了!
Posted sm123456
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源爬虫框架哪家强?是骡子是马,拉出来溜溜就知道了!相关的知识,希望对你有一定的参考价值。

| Project | Language | Star | Watch | Fork |
| Nutch | Java | 1111 | 195 | 808 |
| webmagic | Java | 4216 | 618 | 2306 |
| WebCollector | Java | 1222 | 255 | 958 |
| heritrix3 | Java | 773 | 141 | 428 |
| crawler4j | Java | 1831 | 242 | 1136 |
| Pyspider | Python | 8581 | 687 | 2273 |
| Scrapy | Python | 19642 | 1405 | 5261 |
看到了吗?星星数排名第一的Scrapy比其他所有的加起来都要多,我仿佛听到他这样说:




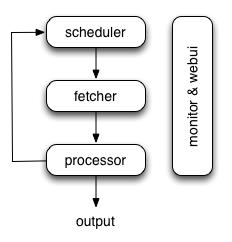
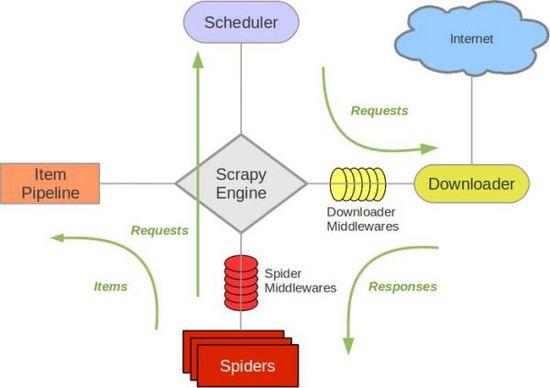
优点:
-
极其灵活的定制化爬取。
-
社区人数多、文档完善。
-
URL去重采用布隆过滤器方案。
-
可以处理不完整的html,Scrapy已经提供了selectors(一个在lxml的基础上提供了更高级的接口),可以高效地处理不完整的HTML代码。
缺点:
-
不支持分布式部署。
-
原生不支持抓取javascript的页面。
-
全命令行操作,对用户不友好,需要一定学习周期。
结论
篇幅有限,就先选择这三个最有代表性的框架进行PK。他们都有远超别人的优点,比如:Nutch天生的搜索引擎解决方案、Pyspider产品级的WebUI、Scrapy最灵活的定制化爬取。也都各自致命的缺点,比如Scrapy不支持分布式部署,Pyspider不够灵活,Nutch和搜索绑定。究竟该怎么选择呢?
我们的目标是做纯粹的爬虫,不是搜索引擎,所以先把Nutch排除掉,剩下人性化的Pyspider和高可定制的Scrapy。Scrapy的灵活性几乎能够让我们完成任何苛刻的抓取需求,它的“难用”也让我们不知不觉的研究爬虫技术。现在还不是享受Pyspider的时候,目前的当务之急是打好基础,应该学习最接近爬虫本质的框架,了解它的原理,所以把Pyspider也排除掉。
最终,理性的从个人的需求角度对比,还是Scrapy胜出!其实Scrapy还有更多优点:
-
HTML, XML源数据选择及提取的原生支持。
-
提供了一系列在spider之间共享的可复用的过滤器(即 Item Loaders),对智能处理爬取数据提供了内置支持。
-
通过 feed导出 提供了多格式(JSON、CSV、XML),多存储后端(FTP、S3、本地文件系统)的内置支持。
-
提供了media pipeline,可以 自动下载 爬取到的数据中的图片(或者其他资源)。
-
高扩展性。您可以通过使用 signals ,设计好的API(中间件, extensions, pipelines)来定制实现您的功能。
-
内置的中间件及扩展为下列功能提供了支持:
-
cookies and session 处理
-
HTTP 压缩
-
HTTP 认证
-
HTTP 缓存
-
user-agent模拟
-
robots.txt
-
爬取深度限制
-
针对非英语语系中不标准或者错误的编码声明, 提供了自动检测以及健壮的编码支持。
-
支持根据模板生成爬虫。在加速爬虫创建的同时,保持在大型项目中的代码更为一致。
-
针对多爬虫下性能评估、失败检测,提供了可扩展的 状态收集工具 。
-
提供 交互式shell终端 , 为您测试XPath表达式,编写和调试爬虫提供了极大的方便。
-
提供 System service, 简化在生产环境的部署及运行。
-
内置 Telnet终端 ,通过在Scrapy进程中钩入Python终端,使您可以查看并且调试爬虫。
-
Logging 为您在爬取过程中捕捉错误提供了方便。
-
支持 Sitemaps 爬取。
-
具有缓存的DNS解析器。
下一步
吹了半天的Scrapy,时间也到了,如果大家能够喜欢上它,学习的效率一定会成倍提升!下次我会为大家带来满满的干货,并完成更具挑战性的爬虫任务,我们下期再见!
原文链接:http://www.cnblogs.com/tuohai666/p/8861422.html
欢迎关注我的博客:https://home.cnblogs.com/u/sm123456/
欢迎大家加入万人交流群:125240963
以上是关于开源爬虫框架哪家强?是骡子是马,拉出来溜溜就知道了!的主要内容,如果未能解决你的问题,请参考以下文章