基本信息
CVPR 2018
作者主页李著文
Interactive Image Segmentation with Latent Diversity
笔记
-
主要研究内容是交互式图像分割。偏重于图像编辑应用领域。大概的理解,就是PS里面的魔棒什么的吧。
-
问题描述,用户在一张图片上点击(选取正负样本点),生成感兴趣的分割目标。问题的特点是多模态的(multimodality),用户的点击,你不能确定他是想选中jacket,还是整个人?
-
本文的目标是,尽可能减少用户的点击,就能获得一定满意程度的目标分割实例。
-
整体的思路是:
our approach trains a single feed-forward stream that generates diverse solutions and then selects among them.
生成一系列的候选分割目标,然后从中间选择一张的目标分割图片。
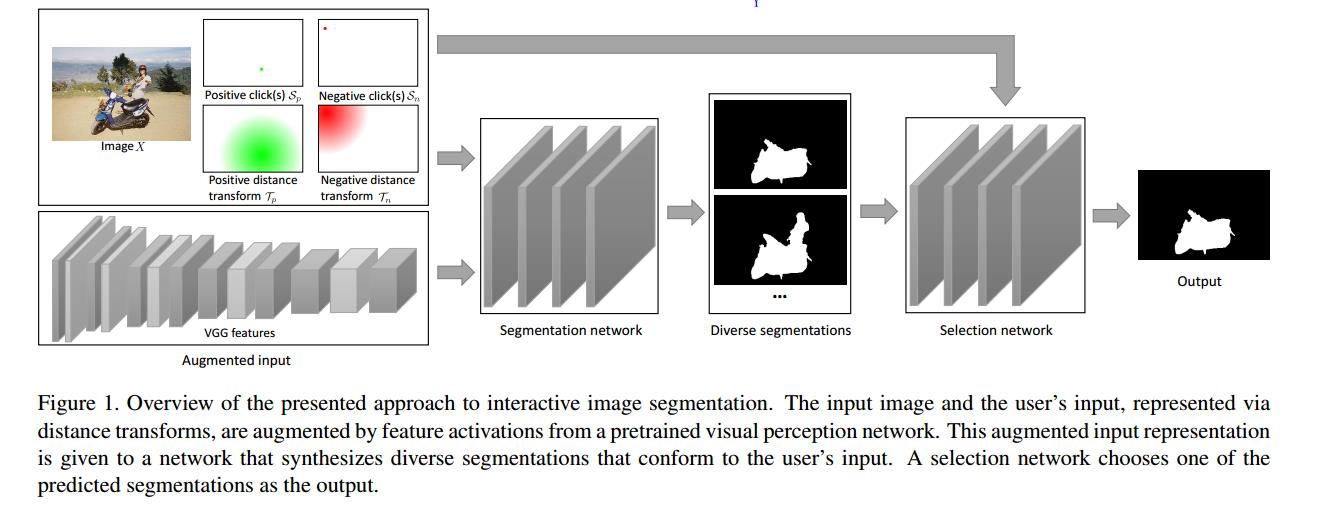
整体分成两个步骤:
- segmentation network (函数 \\(f\\))
- 输入:原始图片\\(X\\),正负点击点\\(S_p\\)和\\(S_n\\),正负点击距离转换\\(T_p\\)和\\(T_n\\),VGG提取后的特征。
- 输出:M个Segmentation Mask,像素值区间是[0,1]实数,连续的。
- selection network (函数 \\(g\\))
- 输入:原始图片\\(X\\),正负点击点\\(S_p\\)和\\(S_n\\),正负点击距离转换\\(T_p\\)和\\(T_n\\),以及M个Segmentation Masks。
- 输出:从M个中选择一个作为输出。
- segmentation network (函数 \\(f\\))
-
关于Loss 函数
Segmentation network使用的loss是作者自己构造的:\\[L_f(\\theta_f) = \\sum_{i} { min_{m}\\{l(Y_i,f_m(X_i;\\theta))+l_c(S_p^i,S_n^i,f_m(X_i;\\theta_f))\\}} \\]其中,
\\[l(A,B) = 1-\\frac{\\sum_pmin(A(p),B(p))}{\\sum_p(A(p),B(p))}$$这是一个简化版本(放宽限制)的Jaccard IoU距离。 $$l_c(S_p,S_n,B) = \\parallel S_p \\odot (S_p-B)\\parallel_1+ \\parallel S_n \\odot (S_n-(1-B))\\parallel_1\\]其中\\(\\odot\\)表示阿达马元素乘积。其实就是统计预测正确的点有多少个,当然实际上不是这样。
值得注意的是

也就是说A中值是离散的,而B中是连续的。
selection network的 loss 函数是:\\[L_g(\\theta) = \\sum_i\\left (-g_{\\phi_i}(Z_i;\\theta_g)+log\\sum_{m=1}^M exp (g_m(Z_i;\\theta_g))\\right) \\]其中,$\\phi_i $ 是mask的索引,用于最小化其和\\(Y_i\\)之间的Jaccard 距离。
-
Segmentation network的设计主要参考Multi-Scale Context Aggregation by Dilated Convolutions,主要特点是空洞卷积获得多尺度特征。主要结构如下:
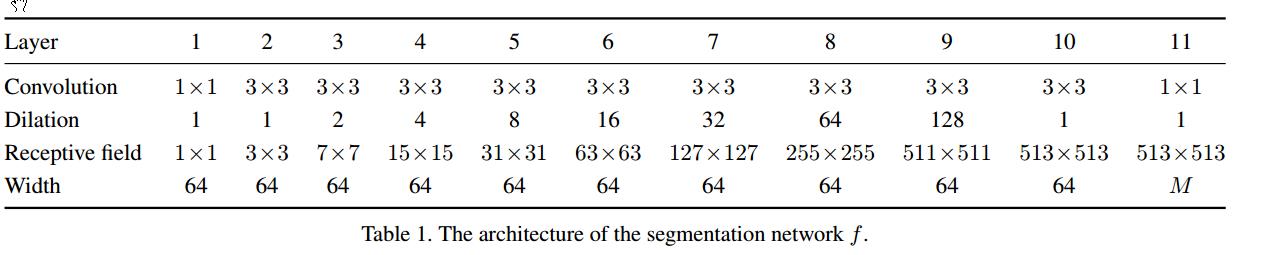
Selection network本质上是一个分类网络,本文沿用上面的网络结构,做了一些改变,第一层换成一个全局平均池化层,最后的全分辨率预测层,也增加一个全局平均池化层。 -
作者为什么使用一个选择网路去从M(M=6)个mask中,选择最后需要的解?作者是想过不同的设计方法,最初的设计就是,设计一个loss函数,作为分数函数,对每个结果进行打分,然后排序。这个方案作为了文章的baseline之一。
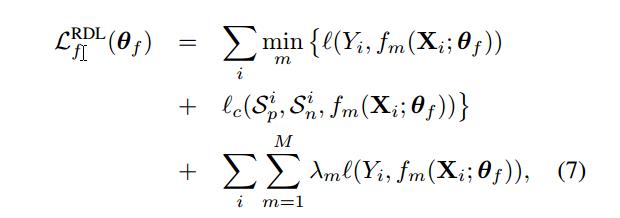
-
关于数据集。
作者使用了+ Semantic BoundariesDataset (SBD) + GrabCut + DAVIS + Microsoft COCO作者特别强调一点:
Note that we do not train on GrabCut, DAVIS, or COCO. Our model is trained only once, on the SBD training set.
-
关于结果
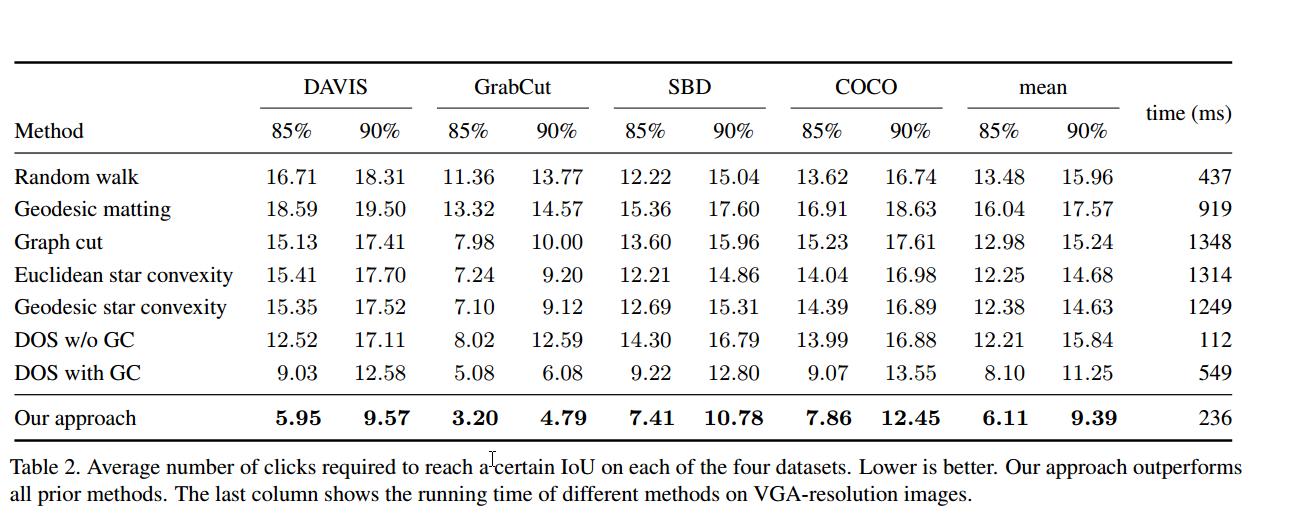
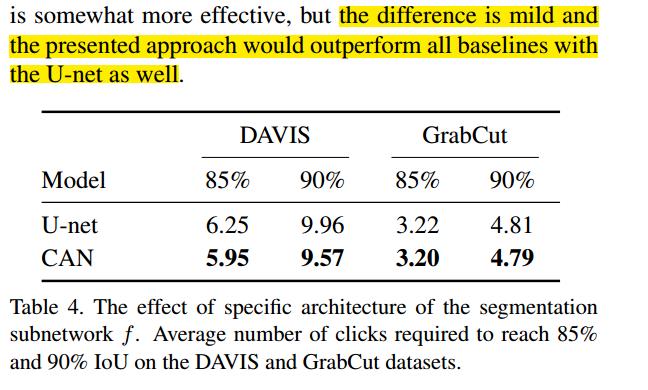
因为作者的目的是减少点击次数,这个U-Net上面的数据貌似不是很好,添加这个Unet和CAN的纵向对比试验,也就是说SBD和COCO上的数据集数据是怎么样呢?都做了怎么多了,应该不差这俩个吧····
总结
这个整体方案还是第一次见到,用的网络还是在其他网路的基础上,做了小修改。
第一次接触交互式任务。主要特点就在这仿真生成模拟点击,在实际使用的过程中相当于增加了两个通道,本文的相较于普通的图像增加了四个通道。
关于交互式点击模拟:

对于图像大致方法就是采样20次,之间关于分布概率的计算采用测地距离。第一次是根据mask进行正例的采样,以后每次采样都是从当前分类错误的集合\\(\\mathcal{O}\'\\)中采样。每次采样,都会刷新预测结果,影响下一次采样。根据这个分布进行采样,应该是尽量采样那些较大块未分类正确的区域,我的理解。(这块不是很了解,欢迎讨论。)