1. Flink
Flink介绍:
Flink 是一个针对流数据和批数据的分布式处理引擎。它主要是由 Java 代码实现。目前主要还是依靠开源社区的贡献而发展。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。再换句话说,Flink 会把所有任务当成流来处理,这也是其最大的特点。Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。
Flink的特性:
Flink是个分布式流处理开源框架:
1>. 即使数据源是无序的或者晚到达的数据,也能保持结果准确性
2>. 有状态并且容错,可以无缝的从失败中恢复,并可以保持exactly-once
3>. 大规模分布式
4>. 实时计算场景的广泛应用(阿里双十一实时交易额使用的Blink就是根据Flink改造而来)
Flink可以确保仅一次语义状态计算;Flink有状态意味着,程序可以保持已经处理过的数据;
Flink支持流处理和窗口事件时间语义,Flink支持灵活的基于时间窗口,计数,或会话数据驱动的窗户;
Flink容错是轻量级和在同一时间允许系统维持高吞吐率和提供仅一次的一致性保证,Flink从失败中恢复,零数据丢失;
Flink能够高吞吐量和低延迟;
Flink保存点提供版本控制机制,从而能够更新应用程序或再加工历史数据没有丢失并在最小的停机时间。
2. Kafka
Kafka介绍
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
Kafka特性
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
1>. 通过磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
2>. 高吞吐量即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
3>. 支持通过Kafka服务器和消费机集群来分区消息。
4>. 支持Hadoop并行数据加载。
Kafka的安装配置及基础使用
因为此篇博客是本地Flink消费Kafka的数据实现WordCount,所以Kafka不需要做过多配置,从Apache官网下载安装包直接解压即可使用
这里我们创建一个名为test的topic
在producer输入数据流:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test

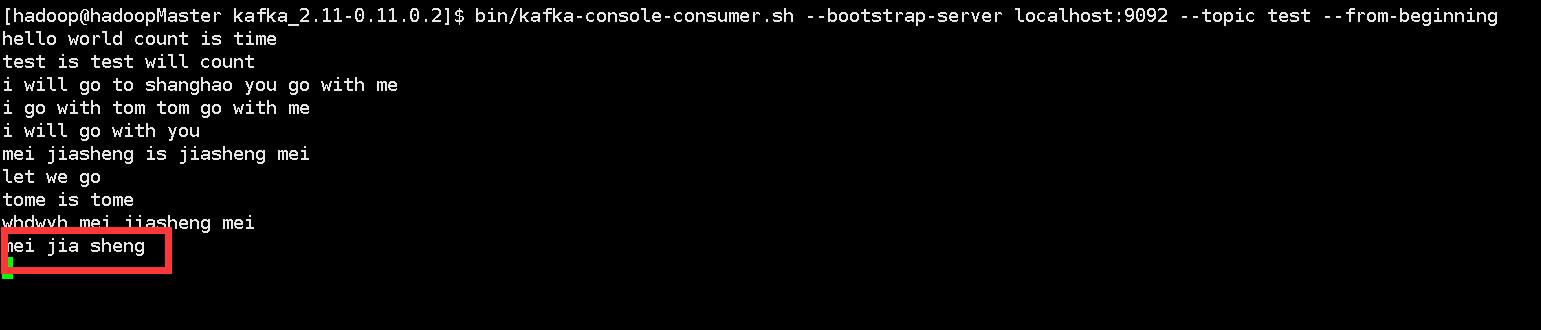
在consumer监控从producer输入的数据流:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
3. Flink Java API实现Flink消费Kafka的数据实现WordCount过程
1>. 创建maven project
2>. 配置flink和flink-kafka需要的依赖pom文件
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.0.0</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.8_2.11</artifactId>
<version>1.0.0</version>
</dependency>
</dependencies>
3>. 引入Flink StreamExecutionEnvironment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
4>. 设置监控数据流时间间隔(官方叫状态与检查点)
env.enableCheckpointing(1000);
5>. 配置kafka和zookeeper的ip和端口
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.1.20:9092");
properties.setProperty("zookeeper.connect", "192.168.1.20:2181");
properties.setProperty("group.id", "test");
6>. 将kafka和zookeeper配置信息加载到Flink StreamExecutionEnvironment
FlinkKafkaConsumer08<String> myConsumer = new FlinkKafkaConsumer08<String>("test", new SimpleStringSchema(),properties);
7>. 将Kafka的数据转成flink的DataStream类型
DataStream<String> stream = env.addSource(myConsumer);
8>. 实施计算模型并输出结果
DataStream<Tuple2<String, Integer>> counts = stream.flatMap(new LineSplitter()).keyBy(0).sum(1);
counts.print();
计算模型具体逻辑代码
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split("\\\\W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
4. 验证
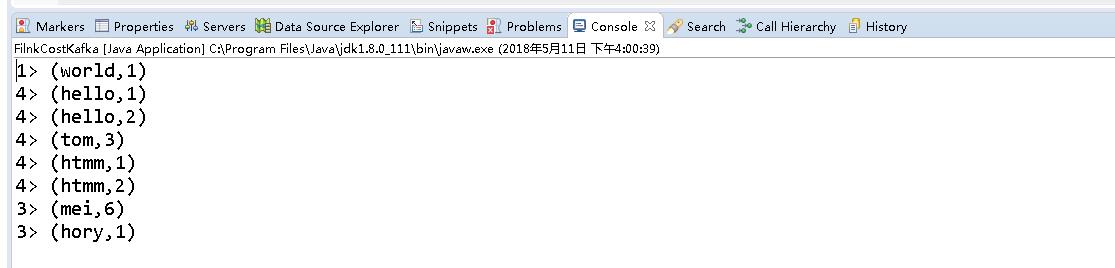
1>. Kafka producer输入

2>. Flink客户端立刻得出结果
完整代码
package com.scn;
import java.util.Properties;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
public class FilnkCostKafka {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.1.20:9092");
properties.setProperty("zookeeper.connect", "192.168.1.20:2181");
properties.setProperty("group.id", "test");
FlinkKafkaConsumer08<String> myConsumer = new FlinkKafkaConsumer08<String>("test", new SimpleStringSchema(),
properties);
DataStream<String> stream = env.addSource(myConsumer);
DataStream<Tuple2<String, Integer>> counts = stream.flatMap(new LineSplitter()).keyBy(0).sum(1);
counts.print();
env.execute("WordCount from Kafka data");
}
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split("\\\\W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}